目次
- 14.1. MySQL Cluster の概要
- 14.2. 基本的な MySQL Cluster のコンセプト
- 14.3. 簡単なマルチ コンピューターの手引き
- 14.4. MySQL Cluster の設定
- 14.5. MySQL Cluster のアップグレードおよびダウンロード
- 14.6. MySQL Cluster のプロセス管理
- 14.7. MySQL Cluster の管理
- 14.8. MySQL Cluster のオンライン バックアップ
- 14.9. クラスタ ユーティリティ プログラム
- 14.9.1. ndb_config ? NDB 設定情報の抽出
- 14.9.2. ndb_delete_all ? NDB テーブルからのすべての行を削除する
- 14.9.3. ndb_desc ? NDB テーブルの説明
- 14.9.4. ndb_drop_index
- 14.9.5. ndb_drop_table
- 14.9.6. ndb_error_reporter
- 14.9.7. ndb_print_backup_file
- 14.9.8. ndb_print_schema_file
- 14.9.9. ndb_print_sys_file
- 14.9.10. ndb_select_all
- 14.9.11. ndb_select_count
- 14.9.12. ndb_show_tables
- 14.9.13. ndb_size.pl ? NDBCluster サイズ仕様エスティメーター
- 14.9.14. ndb_waiter
- 14.10. MySQL Cluster レプリケーション
- 14.11. MySQL Cluster ディスク データ ストレージ
- 14.12. MySQL Cluster での高速インターコネクトを使用する
- 14.13. MySQL Cluster の既知の制限
- 14.14. MySQL Cluster 開発ロードマップ
- 14.15. MySQL Cluster の用語
コンパイル時の不手際のため、MySQL 5.1.12のバイナリ配布にはNDBクラスタやパーティショニングは含まれませんでした。ご不便をお掛けし恐縮です。バージョン5.1.14.へ更新してください。ソースからコンパイルする場合には、--with-ndbcluster、--with-partitionオプションとともにconfigureを実行して下さい。
MySQL Cluster は MySQL
の高可用性、高冗長性バージョンで分散型コンピュータ環境に採用されています。MySQL
Cluster はクラスタで数台の MySQL
サーバーを動作させるための NDB
Cluster ストレージ
エンジンを使用しています。このストレージ
エンジンは MySQL 5.1 バイナリ
リリースおよび最新の Linux 分散型互換の RPM
で利用できます。
MySQL Cluster は現在利用可能で以下のプラットフォームでサポートされています。
Linux:x86、AMD64、EMT64、s/390、PPC、Alpha、SPARC、UltraSparc
Solaris:SPARC、UltraSparc、x86、AMD64、EMT64
BSD (FreeBSD、NetBSD、OpenBSD):x86、AMD64、EMT64、PPC
Mac OS X:PPC
HP-UX:PA-RISC
Tru64:Alpha
OpenVMS:Alpha
IRIX:MIPS
Novell Netware:x86
QNX Neutrino:x86
SCO OpenServer、OpenUnix、UnixWare:x86
特定のオペレーティング システムのバージョンの組み合わせ、、オペレーティング システムの流通、およびハードウェア プラットフォームでの MySQL Cluster の適格なサポート レベルについては、MySQL AB のウェブ サイトの MySQL のサポートチームが維持しているCluster Supported Platforms list を参照してください。
MySQL Cluster は現在 Microsoft Windows ではサポートされて いません。 弊社では MySQL がサポートする Windows を含むすべてのオペレーティング システムでクラスタを利用できるように目指しており、ここに掲載した情報を開発の進捗に応じて更新して参ります。
本章では現在進行中の作業について説明し、その内容は MySQL Cluster の開発の進捗に応じて改訂します。MySQL Cluster に関する詳細は MySQL AB のウェブサイト http://www.mysql.com/products/cluster/ を参照してください。
その他のリソース
クラスタに関するよく出る質問に関する回答は 項A.11. 「MySQL 5.1 FAQ ? MySQL Cluster」 に掲載してあります。
MySQL Cluster のメーリング リスト: http://lists.mysql.com/cluster.
MySQL Cluster フォーラム: http://forums.mysql.com/list.php?25.
多くの MySQL Cluster ユーザーや MySQL Cluster の開発者の中にはクラスタの経験をブログし、それらの経験を PlanetMySQL で共有できるようになっています。
MySQL Cluster を初めてお使いになる場合には、弊社の開発者ゾーンの記事 How to set up a MySQL Cluster for two servers がお役に立つかと思います。
MySQL Cluster は非共有システム (shared-nothing system) での in-memory データベースのクラスタを可能にするテクノロジです。非共有システムのアーキテクチャでは非常に廉価なハードウェアで最低限のハードウェアあるいはソフトウェアの特殊仕様でシステムを構築できます。
MySQL Cluster を使用することで一極集中型不具合(シングル ポイント オブ ファイリュア)を回避できます。これを実現するため、各コンポーネントはそれぞれ自身のメモリとディスクを持ち、ネットワーク共有、ネットワーク ファイルシステム、および SAN などの共有ストレージに使用は推奨もしくはサポートしていません。
MySQL Cluster は NDB と呼ばれる in-memory
のクラスタ ストレージ エンジンで標準の MySQL
サーバーを統合しています。弊社の説明資料では、NDB
という用語はストレージ
エンジンに特化した設定を意味し、そこでは
「MySQL Cluster」 は MySQL および
NDB ストレージ
エンジンの組み合わせを意味しています。
MySQL Cluster は MySQL サーバー、データノード、マネジメント サーバー、および(多分に)特定のデータ アクセス プログラムを含む 1つあるいはそれ以上のプロセスをそれぞれ動作させるコンピュータの組み合わせで構築されます。以下にクラスタでのこれらのコンポーネントの関係を示します。
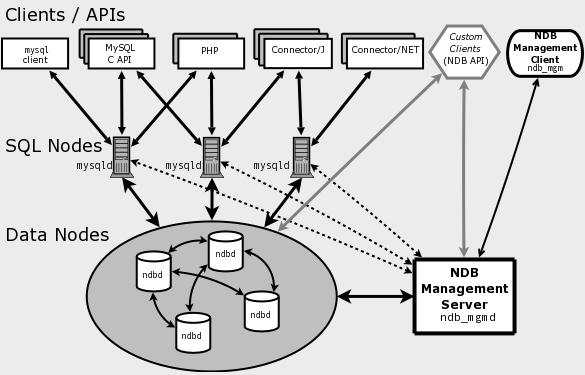
これらのすべてのプログラムは一緒に動作して
MySQL Cluster を構築します。データが NDB
Cluster ストレージ
エンジンに保持されると、テーブルはデータノードに保持されます。それらのテーブルはクラスタのすべての他の
MySQL
サーバーから直接アクセスできます。このように、クラスタに保持された給料計算のアプリケーションでは、一つのアプリケーションで一人の社員の給料を更新すると、このデータをクエリする他のすべての
MySQL サーバーで瞬時のこの変更を表示できます。
MySQL Cluster のデータノードに保持されたデータはミラーされます。クラスタはトランザクションの状態を見失うことによる少数のトランザクションの失敗以外影響を受けずに個々のデータノードの不具合を処理します。なぜなら、トランザクション関係のアプリケーションはトランザクション処理がその目的にあるため、これは問題の根源にはなり得ないからです。
NDB
は高可用性およびデータ堅牢性を提供する
in-memory のストレージ エンジンです。
NDB ストレージ
エンジンは一定のフェールオーバーおよび負荷分散の環境で構築できますが、ストレージ
エンジンをクラスタ
レベルで始めるのが無難です。MySQL Cluster の
NDB ストレージ
エンジンは完全なデータセットを含み、クラスタ内の他のデータのみに依存します。
MySQL Cluster のクラスタ部分は現在 MySQL サーバーとは個別に設定されています。MySQL Cluster では、クラスタの各部を ノード と呼んでいます。
注:多くの説明書では、用語の 「ノード」 はコンピュータに意味に使われていますが、MySQL Cluster の説明ではノードは プロセス を意味します。一台のコンピュータでのノードは幾つも操作できるので、弊社では クラスタ ホスト を用語に使用しています。
(しかし、MySQL は現在は生産環境の設定ではまだ一台のコンピューターで複数のデータノードをサポートしていませんのでその点ご留意ください。詳細は、Issues exclusive to MySQL Clusterを参照してください。)
クラスタ ノードは 3 種類あり、最小の MySQL Cluster の設定では、最低 3 台のノードを使用し、以下の種類になります。
マネジメント ノード (MGM ノード):この種のノードはの役割は MySQL Cluster 内の他のノードを管理し、設定データなどの機能を実行し、ノードを起動あるいは停止したりバックアップなどを行います。この種のノードは他のノードの設定を管理するため、この種のノードは他のノードより先に起動する必要があります。MGM ノードは コマンド ndb_mgmd で起動します。
データノード:この種のノードはクラスタのデータを保持します。レプリカにフラグメントを乗算した分の多くのデータノードがあります。例えば、2 つのレプリカがあれば、各レプリカには 2 つのフラグメントがあるため、4 つのデータノードが必要になります。1 つ以上のレプリカを持つ必要はありません。データノードはコマンド ndbd で起動します。
SQL ノード:これはクラスタ データにアクセスするノードです。MySQL Cluster の場合、SQL ノードは
NDB Clusterストレージ エンジンを使用した従来の MySQL サーバーです。SQL ノードは一般的には mysqld --ndbcluster または、my.cnfに追加したndbclusterオプションとで mysqld を使用して起動します。SQL ノードは実際は単に API ノード の特化版でクラスタ データにアクセスするアプリケーションを意味します。API ノードの一つの例としてはクラスタのバックアップの保持に使用される ndb_restore ユーティリティがあります。NDB API を使用してそのようなアプリケーションを記述できます。
重要生産環境では 3 台のノード設定の使用を期待するのは現実的ではありません。そのような設定は冗長性に欠け、MySQL Cluster の高可用性の機能を活かすには、複数のデータノードおよび SQL ノードを使用する必要があります。複数のマネジメント ノードの使用も強くお勧めします。
MySQL Cluster のノード、ノード グループ、レプリカ、およびパーテッションの関係に関する概説は、項14.2.1. 「MySQL Cluster ノード、ノード グループ、レプリカ、およびパーテッション」 を参照してください。
クラスタの構築にはクラスタの各個々のノードの設定およびノード間の個々の通信リンクの設定が含まれます。MySQL Cluster は現在データノードがプロセッサの性能、メモリ スペース、および帯域において均一になるよう開発しています。さらに、一元管理の設定を提供するために、クラスタのすべての設定データは全体として一つの設定ファイルに格納されています。
マネジメント サーバー (MGM ノード) はクラスタの設定ファイルおよびクラスタ ログを管理します。クラスタの各ノードはマネジメント サーバーから設定データを取り出し、マネジメント サーバーが常駐する場所を決める方法を要求します。データノードで何か珍しいイベントが発生すると、ノードはこれらのイベントの情報をマネジメント サーバーに伝送し、マネジメント サーバーがその情報をクラスタ ログに書き込みます。
さらに、クラスタのクライアント プロセスおよびアプリケーションはどんな数でも利用できます。これらには 2 種類あります。
標準の MySQL クライアント:標準 (非クラスタ)の MySQL 以外の違いは MySQL Cluster でもありません。換言すれば、MySQL Cluster は PHP、Perl、C、C++、Java、Python、Ruby などで記述された既存の MySQL アプリケーションからアクセスできます。
マネジメント クライアント:これらのクライアントはマネジメント サーバーと接続してノードを厳かに始動・停止し、メッセージの追跡(デバッグ バージョンのみ)を始動・停止し、ノードのバージョンおよび状態を表示し、バックアップを始動・停止しするなどのコマンドを提供します。
この項では MySQL Cluster によるストレージ用のデータの分割または複製方法について説明します。
この件で特に理解していただきたいのは以下のコンセプトで、簡単な定義と共にここに一覧にまとめました。
(データ) ノード:ndbd プロセスは レプリカ ?を保持します。つまり そのノードが構成要素であるノード グループに割り当てられた パーテッション (以下参照) のコピーです。
各データノードは個別のコンピューターに配置される必要があります。1 台のコンピューターで複数の ndbd プロセスをホストできますが、そのような設定はサポートしていません。
用語の 「ノード」 や 「データノード」 のは一般的には ndbd プロセスを意味する場合にはどちらも使用できますが、マネジメント (MGM) ノード (ndb_mgmd プロセス) および SQL ノード (mysqld プロセス) はこの説明ではそのように指定されます。
ノード グループ:ノードグループは 1 つ以上のノードで構成され、パーテッション、あるいはレプリカ (次のアイテム参照) のセットを保持します。
注:現在は、クラスタのすべてのノード グループは同数のノードを持つ必要があります。
パーテッション:これはクラスタで保持されているデータの一部です。クラスタのノードのパーテッション数ほどのクラスタのパーテッション数があります。各ノードはクラスタで利用できるノードに割り当てられた少なくともパーテッションのコピー 1 つ (つまり、少なくても 1 つのレプリカ) を維持する役目があります。
レプリカはすべて 1 つのノードに属します。ノードはいくつかのレプリカを保持(通常保持する)できます。
レプリカ:これはクラスタのパーテッションのコピーです。ノード グループの各ノードはレプリカを 1 つ保存します。パーテッション レプリカと呼ばれる場合もあります。ノードグループ毎のレプリカの数はノードの数に一致します。
以下はそれぞれ 2 つのノードを持つ 2 つのノード グループを配置した 4 つのデータノードを持つ MySQL Cluster の図です。ノード 1 およびノード 2 はノード グループ 0 に属し、ノード 3 とノード 4 はノード グループ 1 に属します。ここではデータ (ndbd) ノードのみ示しています。実際に使用されるクラスタではクラスタの管理に ndb_mgm プロセスとクラスタに保持されているデータにアクセスするための少なくとも 1 つの SQL ノードが必要ですが、分かり易くするためにここでは省略しています。
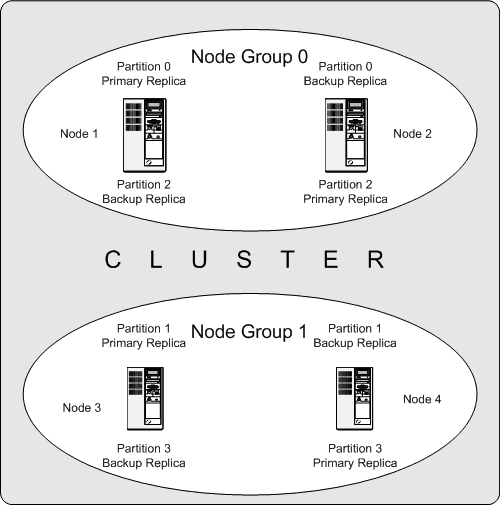
クラスタが保持するデータは 0、1、2、3 の番号を付いた 4 つのパーテッションに分割されます。各パーテッションは同じノード グループの?複数のコピー?に保持されます。パーテッションは交互にノードグループに保持存されます。
パーテッション 0 はノードグループ 0 に保持されます。プライマリ レプリカ (プライマリ コピー) はノード 1 に保持されます。バックアップ レプリカ (パーテッションのバックアップ コピー) はノード 2 に保持されます。
パーテッション 1 は別のノード グループ(ノード グループ 1) に保持されます。このパーテッションのプライマリ レプリカはノード 3、そのバックアップ レプリカはノード 4 の保持されます。
パーテッション 2 はノードグループ 0 に保持されます。しかし、2 つのレプリカの配置はパーテッション 0 と逆になります。パーテッション 2 では、プライマリ レプリカはノード 2 に保持され、バックアップはノード 1 に保持されます。
パーテッション 3 はノードグループ 1 に保存され、その 2 つのレプリカの配置はパーテッション 1 のそれと逆になります。つまり、プライマリ レプリカはノード 4 に配置され、バックアップはノード 3 に配置されます。
MySQL Cluster の継続的なオペレーションに関してこの意味するところは以下のようになります。クラスタで使用される各ノード グループが動作している少なくとも 1 つのノードを持つ限り、クラスタはすべてのデータの完全なコピーを持ち実行可能であり続けます。これを次の図に示します。
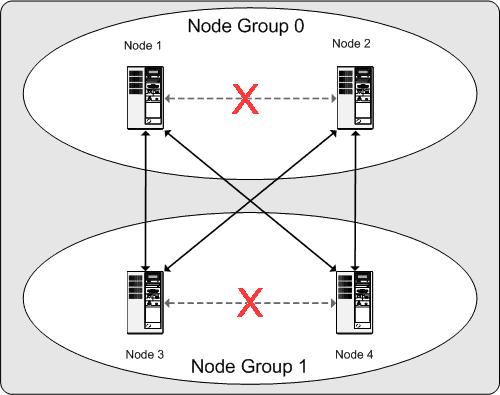
この例では、クラスタがそれぞれ 2 つのノードを持つ 2 つのノード グループで構成されている場合、すくなくともノード グループ 0 に 1 つのノードおよび少なくともノード グループ 1 の 1 つのノードの組み合わせでクラスタを 「有効」 に維持します(図の矢印で示した部分)ことができます。しかし、どちらかのノードグループの両方のノードが失敗した場合、残りの 2 つのノードでは不十分(X の印の付いた矢印)です。どちらの場合も、クラスタは全体のパーテッションを失いすべてのクラスタのデータの完全なセットのアクセスを提供できなくなります。
この項は「手引書」 で MySQL Cluster の計画、インストール、設定、および運営に関して説明します。その一方で 項14.4. 「MySQL Cluster の設定」 の例では様々なクラスタの構築および設定について詳しく説明します。ここで説明するガイドラインおよびプロシージャを実行することによって可用性およびデータの安全に必要な 最低の条件を満たした運用可能な MySQL Cluster を構築できます。
この項ではハードウェアおよびソフトウェア要件;ネットワークの問題、MySQL Cluster のインストール、設定の問題、起動、停止、およびクラスタの再起動;サンプル データベースのローディング、並びにクエリの実行について説明します。
基本的な仮定条件
この手引書は以下の仮定条件に基づいています。
クラスタの設定には 4 台のノードを使用し、それぞれ個別のホストで、以下に示すように一般的な Ethernet 上の固定ネットワーク アドレスを持っていいます。
ノード IP アドレス マネジメント (MGM) ノード 192.168.0.10 MySQL サーバー (SQL) ノード 192.168.0.20 データ (NDBD) ノード "A" 192.168.0.30 データ (NDBD) ノード "B" 192.168.0.40 以下の図で詳しく説明します。
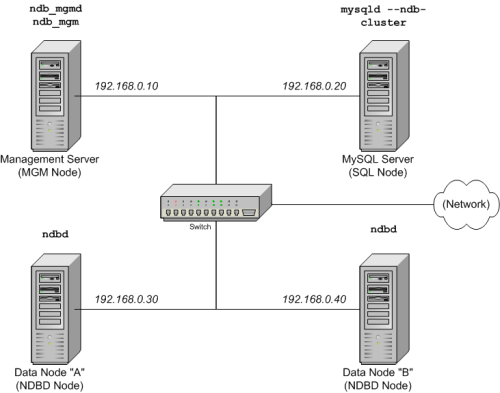
注:分かり易く (および信頼性) するのために、この手引書では数値の IP アドレスのみ使用しています。しかし、お客様のネットワークの DNS 分割が可能な場合、クラスタを設定する際に IP アドレスの代わりホスト名を使用することができます。また、
/etc/hostsファイルあるいは利用可能な場合お客様のオペレーティング システム相当するものを使用してホストの自動照合を行う手段を提供することもできます。このシナリオの各ホストはインテル ベースのディスクトップ PC で、標準設定の不必要なサービスの要らないディスクにインストールした一般的な Linux 分散型で行っています。標準の TCP/IP ネットワーク機能を備えたコアの OS で十分です。簡略化するために、すべてのホストのファイルシステムは全く同じものを使用しています。ファイルシステムが同じでない場合、以下の指示に従がう必要があります。
標準の 100 Mbps あるいは 1 ギガビットの Ethernet カードをそのカードの適切なドライバを使用して各マシンにインストールしています。4 台のすべてのホストはスイッチなどの標準の Ethernet ネットワーク機器を使用して接続しています。(すべてのマシンは同じスループットのネットワーク カードを使用する必要があります。つまり、クラスタの 4 台のすべてのマシンは 100 Mbps カードあるいは 4 台のすべてのマシンは 1 Gbps カードを使用する必要があります。)MySQL Cluster は 100 Mbps のネットワークで動作します。しかし、ギガビットの Ethernet を使用するとパフォーマンスが向上します。
MySQL Cluster は 100 Mbps 以下のスループットのネットワークで使用されるようには設計されて おりませんのでこの点ご留意願います。このため(とりわけ)、MySQL Cluster をインターネットなどの公共のネットワークを使用しても多分うまく行かないし、またまた推奨していません。
サンプルのデータ用に、弊社では
worldデータベースを使用します。それは MySQL AB のウェブ サイトからダウンロードできます。このデータベースは比較的スペースが小さいので、弊社では各マシンは 256MB RAM あれば、オペレーティング システム、ホスト NDB プロセス、および(データノード用)データベースの保持に十分であると考えています。
この手引書では Linux オペレーティング システムにを採り上げていますが、ここでの説明およびプロシージャは他のサポートしているオペラーティング システムにも転用できます。弊社ではお客様が既にネットワーク機能を備えたオペレーティング システムの最低限のインストールおよび設定をご存知で、必要に応じてこの件に関する支援をどこからでも得られるものであるという前提で説明しています。
次項では MySQL Cluster のハードウェア、ソフトウェア、およびネットワーク要件についてさらに突っ込んだ説明をします。(項14.3.1. 「ハードウェア、ソフトウェア、およびネットワークの構築」 参照。)
MySQL Cluster の利点の 1 つは通常のハードウェアで動作し、すべての生きたデータ ストレージは in-memory で行われるので、大容量の RAM 以外にこの点に関し特別な仕様を必要としないということです。(これはディスク データ テーブルには適用されません。? この点に関する詳細は 項14.11. 「MySQL Cluster ディスク データ ストレージ」 を参照してください。)当然のことながら、マルチの高速 CPU はパフォーマンスを強化します。他のクラスタ プロセスで必要なメモリは比較的小さくて済みます。
クラスタに必要なソフトウェア要件もまた穏やかなものです。MySQL Cluster をサポートするホストのオペレーティング システムには特別なモジュール、サービス、アプリケーション、あるいは設定の必要はありません。サポートしているオペレーティング システムには、標準のインストールで十分です。MySQL のソフトウェア要件は簡素です。今必要なものはクラスタをサポートした量産用の SQL 5.1 のリリースだけです。単にクラスタに使用するためにだけにお客様ご自身で MySQL をコンパイルする必要はありません。この手引書では、MySQL ソフトウェア ダウンロード ページ http://dev.mysql.com/downloads/ で入手可能なお客様のオペレーティング システムに適したサーバー バイナリを使用しているものとしてこの説明を続けます。
ノード間通信には、クラスタは TCP/IP ネットワークを標準のトポロジでサポートしており、各ホストに必要な最低条件は標準の 100 Mbps Ethernet カード、それにクラスタ全体の接続を提供するスイッチ、ハブ、あるいはルータです。弊社では以下の理由により MySQL Cluster が非クラスタ マシンを共有していない個別のサブネットで実行されることを強くお勧めします。
セキュリティ:クラスタ ノード間の通信は暗号化あるいはシールドされていません。MySQL Cluster 内での伝送保護の唯一の方法はお客様のクラスタを保護されたネットワークで運用することです。MySQL Cluster をウェブ アプリケーションに使用する場合には、クラスタは必ずファイアウォールの内側に常駐させ、ネットワークの のDe-Militarized (DMZ) ゾーンあるいはそのような場所に常駐させないでください。
効率:MySQL Cluster をプライベートあるいは保護されたネットワークに設定することでクラスタのホスト間の帯域を排他的に使用できます。個別のスイッチを MySQL Cluster の使用することでクラスタのデータへの無許可のアクセスから保護するだけでなく、ネットワーク上の他のコンピュータ間の伝送による干渉からクラスタ ノードをシールドできます。信頼性を向上させるには、デュアルのスイッチおよびデュアルのカードを使用して一極集中型不具合 (シングル ポイントのファイリュア) からネットワークを守ることがでます。多くのデバイス ドライバがそのような通信リンクのフェールオーバーをサポートしています。
MySQL Cluster に高速のスケーラブル コヒーラント インターフェース (SCI) を使用することもできます。これは必要条件ではありません。このプロトコルおよびその MYSQL Cluster での使用方法については 項14.12. 「MySQL Cluster での高速インターコネクトを使用する」 を参照してください。
データあるいは SQL ノードを実行する各 MySQL Cluster のホスト コンピュータには MySQL サーバーバイナリをインストールする必要があります。マネジメント ノードには MySQL サーバーバイナリをインストールする必要はありませんが、MGM サーバーデーモンおよびクライアント バイナリ (それぞれ ndb_mgmd および ndb_mgm) をインストールする必要があります。この項では各種のクラスタ ノードに適切なバイナリをインストールするために必要なステップについて説明します。
MySQL AB
ではクラスタをサポートするコンパイル済みのバイナリを提供していますので、通常これらをお客様ご自身でコンパイルする必要はありません。ですから、各クラスタ
ホストのインストール
プロセスの最初のステップはファイル
mysql-5.1.15-beta-pc-linux-gnu-i686.tar.gz
を MySQL downloads
area
からダウンロードすることです。それを各マシン
/var/tmp
ディレクトリに配置したものと想定します。(カスタムのバイナリが必要な場合には、
項2.9.3. 「開発ソース ツリーからのインストール」
を参照してください。)
RPM も 32 ビットおよび 64 ビットの Linux プラットフォームに利用できます。MySQL Cluster 1 台につき 4 つのRPM が必要です。
サーバー RPM (例えば、
MySQL-server-5.1.15-beta-0.glibc23.i386.rpm) は、 MySQL サーバーの動作に必要なコア ファイルを提供します。サーバー/Max RPM (例えば、
MySQL-Max-5.1.15-beta-0.glibc23.i386.rpm) は、MySQL サーバーにクラスタをサポートしたバイナリを提供します。NDB Cluster - ストレージ エンジン RPM (例えば、
MySQL-ndb-storage-5.1.15-beta-0.glibc23.i386.rpm) は、MySQL Cluster にデータノード バイナリ (ndbd) を提供します。NDB Cluster - ストレージ エンジン マネジメント RPM (例えば、
MySQL-ndb-management-5.1.15-beta-0.glibc23.i386.rpm) は MySQL Cluster にマネジメント サーバーバイナリ (ndb_mgmd) を提供します。
さらに、NDB Cluster
を取得する必要があります - ストレージ
エンジンの基本ツール RPM
(例えば、MySQL-ndb-tools-5.1.15-beta-0.glibc23.i386.rpm)
は、MySQL Cluster
で使用するいくつかの有用なアプリケーションを提供します。これらのうちで重要なものは
MySQL Cluster マネジメント クライアント
(ndb_mgm) です。NDB
Cluster - ストレージ エンジン予備ツール
RPM
(例えば、MySQL-ndb-extra-5.1.15-beta-0.glibc23.i386.rpm)
は、いくつかの追加テストおよびモニタリングのプログラムが含まれていますが、MySQL
Cluster
のインストールには必要ありません。(これらの追加プログラムの詳細に関しては、項14.9. 「クラスタ ユーティリティ プログラム」
を参照してください。)
RPM ファイル名 (5.1.15-beta
として表示) の MySQL
のバージョン番号は実際に使用するバージョンによって変わります。インストールするすべてのクラスタ
RPM の MySQL
バージョン番号が同じであることが非常に重要です。glibc
バージョン番号 (使用している場合 ?
glibc23
として表示)、およびアーキテクチャ名
(i386 として表示) は RPM
をインストールするマシンに適したものであることが必要です。
MySQL AB 供給の RPM を使用した MySQL をインストールに関する一般情報は、 項2.4. 「Linux に MySQL をインストールする」 を参照してください。
RPM のパッケージをインストールした後、さらに 項14.3.3. 「マルチ コンピュータの設定」 で説明するクラスタを設定する必要があります。
注:インストールを完了しても、まだどのバイナリも起動しないでください。すべてのノードの設定が終了した段階で、起動の仕方を説明します。
データおよび SQL
ノードのインストール ?
.tar.gz バイナリ
データあるいは SQL
ノードのホスト用の各マシンで、システム
root
ユーザーとして以下のステップを踏みます。
/etc/passwdおよび/etc/groupファイル (あるいはユーザーおよびグループを管理のためのお客様のオペレーティング システムで提供されたツール) をチェックし、mysqlグループおよびmysqlユーザーがシステムに既に用意されているか確認します。OS の ディストリビューションの中にはこれらをオペレーティング システムのインストール プログラムとして作成している場合もあります。それらがまだ作成されていない場合、新たにmysqlユーザーグループを作成し、mysqlユーザーをこのグループに追加します。shell>
groupadd mysqlshell>useradd -g mysql mysqluseradd および groupadd の文法は Unix のバージョンによって多少異なる場合があり、またadduser および addgroup などの別な名前を使用している場合もあります。
ダウンロードしたファイルを含むディレクトリにロケーションを変更し、アーカイブを開いて、
mysqlに symlink を作成します。実際のファイル名およびディレクトリ名は MySQL のバージョン番号によって異なる場合があります。shell>
cd /var/tmpshell>tar -C /usr/local -xzvf mysql-5.1.15-beta-pc-linux-gnu-i686.tar.gzshell>ln -s /usr/local/mysql-5.1.15-beta-pc-linux-gnu-i686 /usr/local/mysqlロケーションを
mysqlディレクトリに変更し、供給されたスクリプトを実行してシステムのデータベースを作成します。shell>
cd mysqlshell>scripts/mysql_install_db --user=mysqlMySQL サーバーおよびデータ ディレクトリに必要な許可を設定します。
shell>
chown -R root .shell>chown -R mysql datashell>chgrp -R mysql .データノードをホストしている各マシンのデータ ディレクトリは
/usr/local/mysql/dataであることを確認します。マネジメント ノードを設定する際にこの情報が必要になります。(項14.3.3. 「マルチ コンピュータの設定」 参照。)適切なディレクトリに MySQL 起動スクリプトをコピーし、実行できる状態にし、オペレーティング システムがブートしたときに起動できるように設定します。
shell>
cp support-files/mysql.server /etc/rc.d/init.d/shell>chmod +x /etc/rc.d/init.d/mysql.servershell>chkconfig --add mysql.server(起動スクリプトのディレクトリはオペレーティング システムおよびバージョンによって異なる場合があり? 例えば、 いくつかの Linux ディストリビューションの場合、それは
/etc/init.dとなります。)ここでは起動スクリプトのリンクの作成に Red Hat の chkconfig を使用します。Debian の update-rc.d などお客様のオペレーティング システムおよびディストリビューションでこの目的に適切と思われるものを使用します。
データノードおよび SQL ノードが常駐する各マシンで前に説明したステップを個別に実行する必要がありますので忘れずに実行してください。
SQL ノードのインストール ? RPM ファイル
クラスタ SQL ノードをホストに使用する各マシンで、以下のコマンドをシステムのルート ユーザーとして実行して MySQL Max RPM をインストールし、RPM に表示された名前を必要に応じて MySQL AB のウェブサイトからダウンロードした RPM に一致する名前に置き換えます。
shell>rpm -Uhv MySQL-server-5.1.15-beta-0.glibc23.i386.rpmshell>rpm -Uhv MySQL-Max-5.1.15-beta-0.glibc23.i386.rpm
これによりインストールに必要なすべての MySQL
サポート ファイルおよび MySQL
サーバーバイナリ (mysqld) を
/usr/sbin
ディレクトリにインストールします。これにより
mysql.server および
mysqld_safe 起動スクリプトもまた
/usr/share/mysql および
/usr/bin
にそれぞれインストールします。RPM
インストーラが一般的な設定の操作を
(必要に応じて mysql
ユーザーおよびグループの作成)
を自動的に実行します。
データノードのインストール ? RPM ファイル
クラスタのデータノードをホストするコンピュータには NDB Cluster - ストレージ エンジン RPM のみをインストールする必要があります。インストールするには、この RPM をデータノードのホストにコピーし、以下のコマンドをシステム ルートのユーザーとして実行し、RPM に表示された名前を必要に応じて MySQL AB のウェブサイトからダウンロードした RPM に一致する名前に置き換えます。
shell> rpm -Uhv MySQL-ndb-storage-5.1.15-beta-0.glibc23.i386.rpm
前のコマンドで MySQL Cluster データノード
バイナリ (ndbd) を
/usr/sbin
ディレクトリにインストールします。
マネジメント
ノードのインストール ?
.tar.gz バイナリ
(MGM) ノードのインストールには
mysqld
バイナリをインストールする必要はありません。MGM
サーバーとクライアントにのみバイナリが必要で、それはダウンロードしたアーカイブにあります。再度このファイルを
/var/tmp
に配置したか確認します。
システム root
(つまり、sudo、su
root、あるいはお客様のシステムで相当するものを一時的にシステムの管理者のアカウント権限として)として、
以下のステップを実行して ndb_mgmd
および ndb_mgm を Cluster
マネジメント
ノードのホストにインストールします。
ロケーションを
/var/tmpディレクトリに変更して、ndb_mgm および ndb_mgmd をアーカイブから/usr/local/binなどの適切なディレクトリに抽出します。shell>
cd /var/tmpshell>tar -zxvf mysql-5.1.15-beta-pc-linux-gnu-i686.tar.gzshell>cd mysql-5.1.15-beta-pc-linux-gnu-i686shell>cp /bin/ndb_mgm* /usr/local/bin(ダウンロードしたアーカイブを開いたときに作成されたディレクトリとそれが含んでいるファイルを
/var/tmpから、 ndb_mgm および ndb_mgmd が実行可能なディレクトリにコピーされたら削除できます。ファイルをコピーしたディレクトリにロケーションを変更し、次にその両方を実行出来るようにします。
shell>
cd /usr/local/binshell>chmod +x ndb_mgm*
マネジメント ノードのインストール ? RPM ファイル
MySQL Cluster マネジメント サーバーをインストールするには、NDB Cluster - ストレージ エンジン マネジメント RPM のみを使用する必要があります。この RPM をマネジメント ノードをホストするコンピュータにコピーし、次にそれを以下のコマンドをシステム ルートのユーザー(RPM に表示された名前を必要に応じて MySQL AB ウェブサイトからダウンロードしたストレージ エンジン マネジメント RPM に一致する名前に置き換えます) としてインストールします。
shell> rpm -Uhv MySQL-ndb-management-5.1.15-beta-0.glibc23.i386.rpm
これによりマネジメント サーバーバイナリ
(ndb_mgmd) を /usr/sbin
ディレクトリにインストールします。
また ストレージ
エンジン基本ツール RPM で供給された
NDB マネジメント
クライアントをインストールする必要があります。この
RPM をマネジメント
ノードと同じコンピュータにコピーし、次にそれを以下のコマンドをシステム
ルートのユーザー(再度、RPM
に表示された名前を必要に応じて MySQL AB ウェブ
サイトからダウンロードしたストレージ
エンジン基本ツール RPM
に一致する名前に置き換えます)
としてインストールします。
shell> rpm -Uhv MySQL-ndb-tools-5.1.15-beta-0.glibc23.i386.rpm
ストレージ
エンジンの基本ツール RPM は MySQL Cluster
マネジメント クライアント
(ndb_mgm) を /usr/bin
ディレクトリにインストールします。
項14.3.3. 「マルチ コンピュータの設定」 で、弊社の参考クラスタですべてのノードに設定ファイルを作成します。
4 ノード、4 ホスト MySQL Cluster には ノード毎に 1 つずつ 4 つの設定ファイルを書く必要があります。
各データ ノードあるいは SQL ノードは 2 種類の情報を提供する
my.cnfファイルが必要です。ノードに MGM ノードの所在を知らせる接続文字列、および NDB モードでこのホスト(データノードをホストしているマシン)の MySQL サーバーに実行を告げる行。接続文字列に関する詳細は、項14.4.4.2. 「クラスタの
接続文字列」 を参照してください。マネジメント ノードは維持するレプリカの数量、各データ ノードのデータおよびインデックスのメモリ容量、データ ノードをどこで探すか、各データ ノードのディスクのデータの保存場所、どこで SQL ノードを探すかなどを告げる
config.iniファイルが必要とします。
ストレージおよび SQL ノードの設定
データ ノードが必要とするmy.cnf
ファイルはかなり簡素です。設定ファイルは
/etc
ディレクトリにあり、テキスト
エディタで編集できることが必要です。(ない場合にはファイルを作成します。)例えば:
shell> vi /etc/my.cnf
ここではファイルを作成するために vi が使用しますが、どのテキスト エディタも同様に機能する必要があります。
弊社の模範設定での各データノードおよび SQL
ノードに対し my.cnf
は以下のようになります。
# Options for mysqld process: [MYSQLD] ndbcluster # run NDB storage engine ndb-connectstring=192.168.0.10 # location of management server # Options for ndbd process: [MYSQL_CLUSTER] ndb-connectstring=192.168.0.10 # location of management server
上記の情報を入力後、このファイルを保存しテキスト エディタを終了します。これをデータノード 「A」、データ ノード 「B」、および SQL ノードをホストしているマシンに行います。
重要前述のように
mysqld プロセスを
my.cnf の [MYSQLD]
にある ndbcluster および
ndb-connectstring
パラメータで実行すると、CREATE
TABLE あるいは ALTER TABLE
ステートメントをクラスタを実際に起動するまで実行できなくなります。または、これらのステートメントはエラーが表示されて失敗します。これは設計によります。
マネジメント ノードの設定
MGM
ノードを設定する最初のステップは、設定ファイルを格納するディレクトリを作成し、次にファイルそのものを作成します。例えば
(root としてを実行する):
shell>mkdir /var/lib/mysql-clustershell>cd /var/lib/mysql-clustershell>vi config.ini
弊社の見本設定では、config.ini
ファイルは以下のようになります。
# Options affecting ndbd processes on all data nodes:
[NDBD DEFAULT]
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
# TCP/IP options:
[TCP DEFAULT]
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: It is recommended beginning with MySQL 5.0 that
# you do not specify the portnumber at all and simply allow
# the default value to be used instead
# Management process options:
[NDB_MGMD]
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node log files
# Options for data node "A":
[NDBD]
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's data files
# Options for data node "B":
[NDBD]
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's data files
# SQL node options:
[MYSQLD]
hostname=192.168.0.20 # Hostname or IP address
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
(注:world
データベースは http://dev.mysql.com/doc/ の
「例題設定」
のリストからダウンロードできます。)
すべての設定ファイルを作成してこれらの最低限のオプションを指定すると、クラスタを実行する準備が整い、すべてのプロセスが動作していることを検証できます。これをどのように行うか 項14.3.4. 「最初の起動」 で説明します。
利用できる MySQL Cluster の設定パラメータおよびその使用方法の詳細については 項14.4.4. 「設定ファイル」、および 項14.4. 「MySQL Cluster の設定」 を参照してください。バックアップに関する MySQL Cluster の設定については、項14.8.4. 「クラスタ バックアップの設定」 を参照してください。
注:クラスタ マネジメント ノードのデフォルトのポートは 1186で、データ ノードのデフォルトのポートは 2202 です。MySQL 5.0.3 以降ではこの制限が解除されており、クラスタはすでにフリーになっているものから自動的にデータ ノードにポートを割り当てます。
設定後のクラスタの稼動はそれほど難しくありません。各クラスタ ノードはクラスタが常駐するホストで個別に起動します。マネジメント ノードを最初に起動し、次にデータノード、最後に SQL ノードを起動します。
マネジメント ホストでシステム シェルから以下のコマンドを発行し、MGM ノード プロセスを実行します。
shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.inindb_mgmd に
-fあるいは--config-fileオプションを使用して設定ファイルの場所を知らせる必要があります。(詳細は 項14.6.3. 「ndb_mgmd、マネジメント サーバープロセス」 を参照してください。)各データ ノードのホストで、このコマンドを実行して最初の ndbd プロセスを始めます。
shell>
ndbd --initial--initialパラメータのみを ndbd を最初に実行するとき、あるいはバックアップ/復旧作業あるいは設定変更後に起動したときに使用することが非常に重要ですのでこの点留意してください。これは--initialオプションによってノードがリカバリのログファイルを含むリカバリに必要な ndbd インスタンスで以前作成したファイルを削除するからです。この例外は
--initialは ディスク データ ファイルは削除しないということです。クラスタの最初の再起動を実行する必要がある場合、既存のディスク データのログファイルおよびデータ ファイルを手動で削除する必要があります。SQL ノードが常駐するクラスタのホストに MySQL をインストールするために RPM ファイルを使用した場合には、SQL ノードで MySQL サーバープロセスを実行するには供給された起動スクリプトを使用(する必要がある)できます。
すべてが上手くいってクラスタが正しく設定できたら、この段階でクラスタを使用できます。ndb_mgm マネジメント ノード クライアントを起動してこれをテストできます。その出力は以下になる必要があります。使用している MySQL のバージョンによって出力が多少異なる場合もあります。
shell>ndb_mgm-- NDB Cluster -- Management Client -- ndb_mgm>SHOWConnected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 5.1.15-beta, Nodegroup: 0, Master) id=3 @192.168.0.40 (Version: 5.1.15-beta, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 5.1.15-beta) [mysqld(SQL)] 1 node(s) id=4 (Version: 5.1.15-beta)
注:SQL
ノードはここでは [mysqld(API)]
として使用しています。これは完全に通常で、mysqld
プロセスがクラスタ API
ノードの役割を果たしていることを表しています。
この段階でMySQL クラスタのデータベース、テーブル、およびデータを使用できる準備ができました。簡単な説明については、項14.3.5. 「サンプル データのローディングとクエリの実行」 を参照してください。
MySQL Cluster のデータの作業はクラスタ無しの MySQL で行うのとそれほど違いはありません。考慮すべき点が 2 点あります。
クラスタでコピーするテーブルはには、
NDB Clusterストレージ エンジンを使用する必要があります。これを指定するにはENGINE=NDBあるいはENGINE=NDBCLUSTERテーブル オプションを使用します。テーブルを作成する際にこのオプションを追加できます。CREATE TABLE
tbl_name( ... ) ENGINE=NDBCLUSTER;代わりに、異なるストレージ エンジンを使用している既存のテーブルに対して、
ALTER TABLEを使用してテーブルを変更してNDB Clusterを使用できます。ALTER TABLE
tbl_nameENGINE=NDBCLUSTER;各
NDBテーブルにはプライマリ キーが必要です。ユーザーがテーブルを作成したときにプライマリ キーを定義しなかった場合、NDB Clusterストレージ エンジンが自動的に非表示のテーブルを生成します。(注:この非表示のテーブルは他のテーブル インデックスと同じスペースを使用します。メモリ不足のためにこれらの自動的に作成されたインデックスを使用する際に問題に遭遇することは普通ではありません。
mysqldump
の出力を使用して既存のデータベースからテーブルをインポートする場合、テキスト
エディタの SQL
スクリプトを開きテーブルの作成ステートメントに
ENGINE
オプションを追加します。あるいは既存の
ENGINE (あるいは TYPE)
オプションを置き換えます。MySQL Cluster
をサポートしていない別の MySQL サーバーに
world
サンプルのデータベースを持っていて、City
テーブルをエクスポートするとします。
shell> mysqldump --add-drop-table world City > city_table.sql
その結果の city_table.sql
ファイルはテーブルの作成ステートメント(およびテーブル
データをインポートするために必要な
INSERT ステートメント)
を含みます。
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(remaining INSERT statements omitted)
MySQL が NDB ストレージ
エンジンをこのテーブルに使用していることを確認する必要があります。この確認の方法は
2 つあります。その 1 つは Cluster
データベースにインポートする前
before
にテーブルの定義を変更することです。例として
City
テーブルを使用し、以下のように定義の
ENGINE オプションを変更します。
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(remaining INSERT statements omitted)
クラスタ
テーブルの一部になる各テーブルの定義にこれを行う必要があります。これを行うための最も簡単な方法は定義を含むファイルに検索および置き換えを実行し、TYPE=
あるいは
engine_nameENGINE=
のすべてのインスタンスを
engine_nameENGINE=NDBCLUSTER
で置き換えることです。ファイルの変更を希望しない場合には、変更していないファイルを使用してテーブルを作成し、次に
ALTER TABLE を使用してストレージ
エンジンを変更します。この項の後で詳細を説明します。
クラスタの SQL ノードで world
と呼ばれるデータベースを既に作成したとして、mysql
コマンド ライン クライアントを使用して
city_table.sql
を読み込み、そして次にいつもの方法で相当するテーブルを作成して移植します。
shell> mysql world < city_table.sql
前述のコマンドを SQL
ノードを実行している(この場合、IP
アドレスが 192.168.0.20 のマシンで)
ホストで忘れないで実行することが非常に重要です。
SQL ノードで world
全体のデータベースのコピーを作成するには、非クラスタ
サーバーの mysqldump
を使用してデータベースをファイル名
world.sql
にエクスポートします。例えば、/tmp
のティレクトりで行います。次にテーブルの定義を今説明したように変更し、以下のようにクラスタの
SQL ノードにそのファイルをインポートします。
shell> mysql world < /tmp/world.sql
ファイルを別のロケーションに保存した場合、前述の説明をしかるべく調整します。
MySQL の NDB Cluster が 5.1
データベースのオートディスカバリをサポートしていないことを忘れずに覚えておくことがが重要です。(項14.13. 「MySQL Cluster の既知の制限」
参照。)このことは、データ
ノードでworld
データベースおよびそのテーブルを作成したら、CREATE
SCHEMA world
ステートメントを発行する必要があることを意味しています。
SELECT クエリを SQL
ノードで実行することは MySQL
サーバーの他のインスタンスで実行するのと違いはありません。。コマンドラインからクエリを実行するには、最初に
MySQL Monitor にいつもの方法 (root
パスワードを Enter
password:プロンプトで指定します)
でログインします。
shell> mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 5.1.15-beta
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
弊社では単純に MySQL サーバーの
root
アカウントを使用していますが、お客様は My SQL
サーバーのインストールの際は堅固な
root
パスワードの設定を含む標準的なセキュリティ対策を講じているものと想定しています。詳細は
項2.10.3. 「最初の MySQL アカウントの確保」
を参照してください。
クラスタ ノードがお互いにアクセスするときに
MySQL
権限システムを使用しないことを考慮する必要があります。MySQL
ユーザーアカウント(root
アカウントを含む)の設定あるいは変更によって、ノード間のインターラクションに影響を及ぼさず、SQL
ノードにアクセスするアプリケーションにのみ影響を及ぼします。
SQL
スクリプトのインポートに先立ちテーブル定義の
ENGINE
節を変更しなかった場合、この時点で以下のステートメントを実行する必要があります。
mysql>USE world;mysql>ALTER TABLE City ENGINE=NDBCLUSTER;mysql>ALTER TABLE Country ENGINE=NDBCLUSTER;mysql>ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
データベースを選択してそのデータベースのテーブルに対する SELECT クエリの実行も既存の MySQL Monitor と同様に通常の方法で実現できます。
mysql>USE world;mysql>SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5;+-----------+------------+ | Name | Population | +-----------+------------+ | Bombay | 10500000 | | Seoul | 9981619 | | Sao Paulo | 9968485 | | Shanghai | 9696300 | | Jakarta | 9604900 | +-----------+------------+ 5 rows in set (0.34 sec) mysql>\qBye shell>
MySQL を使用しているアプリケーションは標準の
API で NDB
テーブルにアクセスします。Iお客様のアプリケーションが、MGM
あるいはデータノードではなく SQL
ノードにアクセスすることを憶えておくことが重要です。この簡単な例ではネットワーク上の
Web サーバーで動作している PHP 5 の
mysqli
拡張を使用した場合のようにどのように
SELECT
ステートメントを実行するかを示しています。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=iso-8859-1">
<title>SIMPLE mysqli SELECT</title>
</head>
<body>
<?php
# connect to SQL node:
$link = new mysqli('192.168.0.20', 'root', 'root_password', 'world');
# parameters for mysqli constructor are:
# host, user, password, database
if( mysqli_connect_errno() )
die("Connect failed: " . mysqli_connect_error());
$query = "SELECT Name, Population
FROM City
ORDER BY Population DESC
LIMIT 5";
# if no errors...
if( $result = $link->query($query) )
{
?>
<table border="1" width="40%" cellpadding="4" cellspacing ="1">
<tbody>
<tr>
<th width="10%">City</th>
<th>Population</th>
</tr>
<?
# then display the results...
while($row = $result->fetch_object())
printf(<tr>\n <td align=\"center\">%s</td><td>%d</td>\n</tr>\n",
$row->Name, $row->Population);
?>
</tbody
</table>
<?
# ...and verify the number of rows that were retrieved
printf("<p>Affected rows: %d</p>\n", $link->affected_rows);
}
else
# otherwise, tell us what went wrong
echo mysqli_error();
# free the result set and the mysqli connection object
$result->close();
$link->close();
?>
</body>
</html>
Web サーバー上で実行されているプロセスが SQL ノードの IP アドレスにアクセスできるものとします。
同様に、MySQL C API、Perl-DBI、Python-mysql、あるいは MySQL AB の自身のコネクタを使用してデータ定義および操作のタスクを MySQL で行うのと同様に実行できます。
クラスタをシャットダウンするには、MGM ノードをホストしているマシンのシェルに以下のコマンドを入力します。
shell> ndb_mgm -e shutdown
ここの-e
オプションがコマンドをシェルから
ndb_mgm
クライアントに渡すために使用されます。項3.3.1. 「コマンドラインにおけるオプションの使用」
参照。そのコマンドが
ndb_mgm、ndb_mgmd、および他の
ndbd プロセスを終了させます。SQL
ノードは mysqladmin shutdown
および他の方法でショットダウンできます。
クラスタを再起動するには、これらのコマンドを使用します。
マネジメント ホスト (
192.168.0.10サンプル設定):shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.ini各データ ノードのホスト (
192.168.0.30および192.168.0.40):shell>
ndbdNDBD ノードを通常に再起動する際にはこのコマンドを
--initialオプションで実行しない ことを憶えておいてください。SQL ホスト (
192.168.0.20):shell>
mysqld &
クラスタのバックアップを取るには 項14.8.2. 「バックアップを作成するためのマネジメント クライアントの使用」 を参照してください。
クラスタをバックアップから復旧するには ndb_restore コマンドを使用する必要があります。これは 項14.8.3. 「クラスタのバックアップの復旧方法」 で説明しています。
MySQL Cluster の設定の詳細は 項14.4. 「MySQL Cluster の設定」 で入手できます。
MySQL Cluster を構成する MySQL サーバーが通常
(非クラスタ) の MySQL サーバーと 1
点異なります。それは NDB Cluster
ストレージ
エンジンを搭載していることです。このエンジンは単に
NDB とも言われ、その 2
つの名前は同じ意味です。
リソースの不必要な割り当てを避けるために、サーバーはデフォルトで
NDB ストレージ
エンジンを無効に設定しています。NDB
を有効にするには、サーバーの
my.cnf
設定ファイルを変更するか、またはサーバーを
--ndbcluster オプションで起動します。
MySQL
サーバーはクラスタの構成要素の一部ですので、クラスタの設定データを取得するには
MGM
ノードへのアクセス方法を知る必要があります。デフォルトでは
MGM ノードを localhost
で探します。しかし、そのロケーションの場所を指定する必要がある場合には、my.cnf、
あるいは MySQL
サーバーのコマンドラインでできます。NDB
ストレージ
エンジンを使用する前に、所望のデータ
ノードはもとより少なくとも MGM ノードを 1
つ動作できるようにしておく必要があります。
NDB、つまりクラスタ ストレージ
エンジンはバイナリのディストリビューションで
Linux、Mac OS X、および Solaris
で利用できます。現在 Windows を含む MySQL
でサポートするすべてのオペレーティング
システムでクラスタを動作できるように作業しています。
ソース tarball あるいは MySQL 5.1 BitKeeper
ツリーからの構築を選択する場合、--with-ndbcluster
オプションを configure
を実行する際必ず使用してください。BUILD/compile-pentium-max
ビルド
スクリプトを使用することもできます。このスクリプトは
OpenSSL
が含まれているため、構築を成功裏に終わるにはオープン
SSL
を使用するかあるいは取得する必要があります。あるいは、compile-pentium-max
を変更して要件を外します。勿論、ご自身のバイナリにコンパイルするには標準の手順に説明書に従い、次に通常のテストおよびインストール
プロシージャを実行します。項2.9.3. 「開発ソース ツリーからのインストール」
参照。
次の数項で MySQL のインストール方法には習熟されると思いますので、ここでは MySQL Cluster の設定および非クラスタの MySQL の違だけにいつて説明します。(後者について詳細は、章?2. MySQL のインストールと更新 を参照してください。)
すべてのマネジメント
ノードおよびデータノードを最初に起動しているとクラスタの設定が非常に簡単だということが分かります。これは設定の中でもっとの時間にかかる部分です。my.cnf
ファイルの編集はとても簡単です。この項では非クラスタの
MySQL の設定との違いについてのみ説明します。
基本に習熟して頂くために、最も簡単な MySQL Cluster の実用面の設定について説明します。これが終了すると、本章の関連する項で提供された情報に従ってお客様のご所望の設定が出来るようになります。
最初に、/var/lib/mysql-cluster
のような設定ディレクトリを作成する必要があります。それを作成するには以下のコマンドをシステム
root ユーザーとして実行します。
shell> mkdir /var/lib/mysql-cluster
このディレクトリで以下の情報を含む
config.ini
と呼ばれるファイルを作成します。必要に応じてお客様のシステムに適切な値を
HostName および DataDir
に入力します。
# file "config.ini" - showing minimal setup consisting of 1 data node, # 1 management server, and 3 MySQL servers. # The empty default sections are not required, and are shown only for # the sake of completeness. # Data nodes must provide a hostname but MySQL Servers are not required # to do so. # If you don't know the hostname for your machine, use localhost. # The DataDir parameter also has a default value, but it is recommended to # set it explicitly. # Note: DB, API, and MGM are aliases for NDBD, MYSQLD, and NDB_MGMD # respectively. DB and API are deprecated and should not be used in new # installations. [NDBD DEFAULT] NoOfReplicas= 1 [MYSQLD DEFAULT] [NDB_MGMD DEFAULT] [TCP DEFAULT] [NDB_MGMD] HostName= myhost.example.com [NDBD] HostName= myhost.example.com DataDir= /var/lib/mysql-cluster [MYSQLD] [MYSQLD] [MYSQLD]
ndb_mgmd この段階でマネジメント
サーバーを起動できます。デフォルトでは
config.ini
ファイルを現在動作しているディレクトリから読み込もうとしますので、ファイルが存在するディレクトリに変更して、ndb_mgmd
を起動します。
shell>cd /var/lib/mysql-clustershell>ndb_mgmd
次に ndbd
を実行してシングルのデータ
ノードを起動します。ndbd
を所定のデータノードにまさに初めて起動するには、以下のに示す
--initial
オプションを使用する必要があります。
shell> ndbd --initial
その後の ndbd
の起動では、普通は--initial
オプションを省き
たいと思うでしょう
shell> ndbd
--initial
をその後の再起動で省く理由はこのオプションでは
ndbd
がこのデータノードの既存のすべてのデータおよびログ
ファイルを削除し、新たにそれらを作成するからです。--initial
を最初の ndbd
起動以外に使用しないこの規則の例外はそれをクラスタを起動するときに使用し、新しいデータ
ノードを追加した後にバックアップから保存することです。
デフォルトでは、ndbd
はマネジメント サーバーをポート 1186 の
localhost で探します。
注:MySQL をバイナリの
tarball
からインストールした場合には、ndb_mgmd
および ndbd
サーバーのパスを明示的に指定する必要があります。(通常、これらは
/usr/local/mysql/bin にあります。)
最後に、ロケーションを MySQL データ
ディレクトリ (通常 /var/lib/mysql
あるいは /usr/local/mysql/data)
に変更し、my.cnf ファイルが NDB
ストレージ
エンジンに起動に必要なオプションが含まれているか確認します。
[mysqld] ndbcluster
この段階で MySQL サーバーを従来通りに起動できます。
shell> mysqld_safe --user=mysql &
MySQL
サーバーが適切に動作しているか確認するために少し待ちます。mysql
ended
との通知が表示された場合には、サーバーの.err
ファイルをチェックして何が間違っているか調べます。
ここまですべてが問題なく動作した場合、この段階でクラスタを使用して起動できます。サーバーに接続して
NDBCLUSTER ストレージ
エンジンが有効であることを確認します。
shell>mysqlWelcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 to server version: 5.1.15-beta Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>SHOW ENGINES\G... *************************** 12. row *************************** Engine: NDBCLUSTER Support: YES Comment: Clustered, fault-tolerant, memory-based tables *************************** 13. row *************************** Engine: NDB Support: YES Comment: Alias for NDBCLUSTER ...
前述の参考例の出力で表示された行番号はサーバーの設定によってお客様のシステムに表示されたものと異なる場合があります。
NDBCLUSTER テーブルの作成
shell>mysqlmysql>USE test;Database changed mysql>CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER;Query OK, 0 rows affected (0.09 sec) mysql>SHOW CREATE TABLE ctest \G*************************** 1. row *************************** Table: ctest Create Table: CREATE TABLE `ctest` ( `i` int(11) default NULL ) ENGINE=ndbcluster DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
お客様のノードが適切に設定されているか確認するには、マネジメント クライアントを起動します。
shell> ndb_mgm
クラスタのステータスのレポートを取得するにはマネジメント クライアントの SHOW コマンドを使用します。
NDB> SHOW
Cluster Configuration
---------------------
[ndbd(NDB)] 1 node(s)
id=2 @127.0.0.1 (Version: 3.5.3, Nodegroup: 0, Master)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @127.0.0.1 (Version: 3.5.3)
[mysqld(API)] 3 node(s)
id=3 @127.0.0.1 (Version: 3.5.3)
id=4 (not connected, accepting connect from any host)
id=5 (not connected, accepting connect from any host)
この段階で、実働可能な MySQL Cluster
の設定を完了しました。ここで
ENGINE=NDBCLUSTER あるいはその別名
ENGINE=NDB
で作成されたテーブルを使用してクラスタのデータを保存できます。
MySQL を設定には 2 つのファイルの作業が伴います。
my.cnf:すべての MySQL Cluster 実行ファイルにオプションを指定します。このファイルは MySQL のこれまでの説明で既に習熟していると思いますが、クラスタで使用されている各実行ファイルからアクセスできる必要があります。config.ini:このファイルは MySQL Cluster マネジメント サーバーによってのみ読み込まれ、クラスタで使用されているすべてのプロセスにそこに含まる情報を配布します。config.iniにはクラスタに使用されている各ノードの説明が含まれます。これにはデータ ノードの設定パラメータおよびクラスタのすべてのノード間接続の設定パラメータが含まれています。このファイルに表示されるセクションを素早く参照したり、各セクションにどんな種類の設定パラメータが含まれているを調べるにはconfig.iniFile を参照してください。
弊社では継続的にクラスタの設定を改善しており、また現在このプロセスを簡素化する作業に携わっています。弊社では以前のバージョンとの互換性維持に努めていますが、互換性の無い変更が行われる場合もあります。そのような場合には弊社では変更によって以前のバージョンとの互換性が無くなる旨を事前niクラスタのユーザーに連絡するつもりです。お客様がそのような変更に気付いても弊社で文書化していない場合、項1.7. 「質問またはバグの報告」 にある指示に従ってそれを MySQL のバグ データベースに報告お願いします。
MySQL Cluster をサポートするには
my.cnf
を以下の例に基づいて更新する必要があります。ここに示すオプションを
config.ini
ファイルに使用したオプションと混同しないように注意してくだささい。実行ファイルを実行する際にコマンドラインでこれらのパラメータを指定することもっできます。
# my.cnf # example additions to my.cnf for MySQL Cluster # (valid in MySQL 5.1) # enable ndbcluster storage engine, and provide connectstring for # management server host (default port is 1186) [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com # provide connectstring for management server host (default port: 1186) [ndbd] connect-string=ndb_mgmd.mysql.com # provide connectstring for management server host (default port: 1186) [ndb_mgm] connect-string=ndb_mgmd.mysql.com # provide location of cluster configuration file [ndb_mgmd] config-file=/etc/config.ini
(接続文字列に関する詳細は、項14.4.4.2. 「クラスタの 接続文字列」
を参照してください。)
# my.cnf # example additions to my.cnf for MySQL Cluster # (will work on all versions) # enable ndbcluster storage engine, and provide connectstring for management # server host to the default port 1186 [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com:1186
重要前述のように
mysqld プロセスを
my.cnf ファイルの
[MYSQLD] にある
ndbcluster および
ndb-connectstring
パラメータで実行すると、CREATE
TABLE あるいは ALTER TABLE
ステートメントをクラスタを実際に始めるまでは実行できなくなります。または、これらのステートメントはエラーが表示されて失敗します。これは設計によります。
クラスタ のmy.cnf
ファイルの個別の [mysql_cluster]
セクションを使用して設定を読み込んですべての実行ファイルで使用することもできます。
# cluster-specific settings [mysql_cluster] ndb-connectstring=ndb_mgmd.mysql.com:1186
my.cnf
ファイルで設定できる他の NDB
変数については
項4.2.3. 「システム変数」
を参照してください。
設定ファイルはデフォルトで
config.ini
の名前になっています。設定ファイルは起動時に
ndb_mgmd
で読み込まれどこにでも配置できます。そのロケーションと名前は
ndb.mgmd のコマンドラインにある
--config-file=
を使用して指定できます。設定ファイルが指定されていない場合、ndb_mgmd
がデフォルトで現在の動作中のディレクトリにある
path_nameconfig.ini
ファイルを読み込もうとします。
現在設定ファイルは INI
フォーマットで、最初にセクションの見出しのあるセクション(角括弧で括られている)で構成され、その後に適切なパラメータ名や値が続きます。標準の
INI
フォーマットと違うところはパラメータ名や値がコロン
(‘:’) および等号記号
(‘=’)
で分離できることです。もう一箇所違うところはセクションがセクション名で独自に認識されないことです。その代わり、独自のセクション
(同じ種類の異なる 2 つのノードなど)
はセクション内のパラメータとして指定された独自の
ID で認識されます。
デフォルト値は殆どのパラメータに定義され、config.ini
で指定することもできます。デフォルト値のセクションを作成するには、単に単語
DEFAULT
をセクション名に追加するだけです。例えば、[NDBD]
セクションは特定のデータノードに適用されるパラメータを含み、[NDBD
DEFAULT]
セクションはすべてのデータノードに適用されるパラメータを含みます。すべてのデータノードが同じデータのメモリ容量を使用するものと仮定します。それらをすべて設定するには、DataMemory
ラインを含む [NDBD DEFAULT]
セクションを作成してデータのメモリ容量を指定します。
最低の設定でも、設定ファイルはクラスタに使用されるコンピュータやノードを定義し、それらのコンピュータのこれらのノードが属します。1 台のマネジメント サーバー、2 台のデータノードおよび 2 台の MySQL サーバーで構成した簡素な設定ファイルの例をここに示します。
# file "config.ini" - 2 data nodes and 2 SQL nodes # This file is placed in the startup directory of ndb_mgmd (the # management server) # The first MySQL Server can be started from any host. The second # can be started only on the host mysqld_5.mysql.com [NDBD DEFAULT] NoOfReplicas= 2 DataDir= /var/lib/mysql-cluster [NDB_MGMD] Hostname= ndb_mgmd.mysql.com DataDir= /var/lib/mysql-cluster [NDBD] HostName= ndbd_2.mysql.com [NDBD] HostName= ndbd_3.mysql.com [MYSQLD] [MYSQLD] HostName= mysqld_5.mysql.com
各ノードはそれぞれ独自のセクションを
config.ini
に持つ必要があります。例えば、このクラスタには
2
台のデータノードがあるので、前述の設定ファイルにはこれらのノードを定義する
2 つの [NDBD]
セクションがあります。
以下のリストに示すように、config.ini
設定ファイルで使用できる異なる 6
つのセクションがあります。
[COMPUTER]:クラスタのホストを定義します。これは実際の MySQL クラスタの設定には必要ありませんが、大きなクラスタを設定する際に使用すると便利です。詳細については、項14.4.4.3. 「クラスタ コンピュータの定義」 をご参照してください。[NDBD]:クラスタ データノード (ndbd プロセス) の定義します。詳細は、項14.4.4.5. 「Defining Data Nodes」 を参照してください。[MYSQLD]:クラスタ MySQL サーバーノード (SQL または API ノードとも呼ばれている) を定義します。SQL ノード設定の説明については 項14.4.4.6. 「SQL および他の API ノードの定義」 を参照してください。[MGM]あるいは[NDB_MGMD]:クラスタ マネジメント サーバー (MGM) ノードを定義します。MGM ノードの設定に関する情報は 項14.4.4.4. 「マネジメント サーバーの定義」 を参照してください。[TCP]:TCP/IPがデフォルトの接続プロトコルの場合のクラスタ ノード間の TCP/IP 接続を定義します。通常、[TCP]あるいは[TCP DEFAULT]セクションは、クラスタが自動的にこれを行うので MySQL Cluster の設定には必要はありませんが、クラスタにより提供されたデフォルトをオーバーライドする際に必要になる場合があります。利用できる TCP/IP の設定パラメータおよびその使用方法については 項14.4.4.7. 「Cluster TCP/IP Connections」 を参照してください。(項14.4.4.8. 「直接接続を使用した TCP/IP の接続」 にもこのTCP/IP に関する情報を載せてあります。)[SHM]:ノード間の共有メモリの接続を定義します。MySQL 5.1 では、それはデフォルトで有効になっていますが現在はまだ試験段階です。SHM のインターコネクトの説明に付いては 項14.4.4.9. 「共有メモリ接続」 を参照してください。[SCI]:クラスタノード間のスケーラブル コヒーラント インターフェースの接続を定義します。そのような接続に MySQL Sluster のディストリビューションには含まれていないが、自由に入手できるソフトウェアと特定のハードウェアが必要です。SCI のインターコネクトに関する詳細は 項14.4.4.10. 「SCI トランスポート接続」 を参照してください。
各セクションに対して DEFAULT
の値を定義できます。すべてのクラスタのパラメータは重要なパラメータで、my.cnf
あるいは my.ini
ファイルで指定されたパラメータとは異なります。
MySQL Cluster マネジメント サーバー (ndb_mgmd) を除いて、MySQL Cluster の一部を構成する各ノードはマネジメント サーバーのロケーションをポイントする接続文字列 が必要です。この接続文字列はマネジメント サーバーへの接続の確立およびクラスタのノードの役割に基づいた他のタスクの実行に使用されます。接続文字列の構文は以下のようになります。
<connectstring> :=
[<nodeid-specification>,]<host-specification>[,<host-specification>]
<nodeid-specification> := node_id
<host-specification> := host_name[:port_num]
node_id は 1 より大きい整数で
config.ini
のノードを認識します。host_name
は文字列で有効なインターネットのホスト名あるいは
IP
アドレスを表します。port_num
は整数で TCP/IP ポート番号を意味します。
example 1 (long): "nodeid=2,myhost1:1100,myhost2:1100,192.168.0.3:1200" example 2 (short): "myhost1"
すべてのノードは localhost:1186
を他に無い場合デフォルトの接続文字列として使用します。port_num
が接続文字列に無い場合、デフォルトのポートは
1186 です。このポートはこの目的のために IANA
に割り当てられているので、常にネットワークで利用できる状態でなければなりません(詳細は
http://www.iana.org/assignments/port-numbers
参照 )。
複数の <host-specification>
値を入力すると、いくつかの冗長マネジメント
サーバーを指定できます。クラスタのノードは指定された順序で各ホストのマネジメントサーバーに接続が確立されるまで接続を試みます。
接続を指定する多くの異なる方法があります。
各実行ファイルにはそれ自身のコマンドラインのオプションがあり、起動時にマネジメント サーバーを指定します。(それぞれの実行ファイルについてはその説明書を参照してください。)
接続文字列をマネジメント サーバー
my.cnfファイルの[mysql_cluster]セクションに置くことで接続文字列をクラスタのすべてのノードに一度に設定することもできます。以前のバージョンへの互換性につい打ては、同じ構文を使用して他の 2 つのオプションが利用できます。
NDB_CONNECTSTRING環境変数を設定して接続文字列を含みます。各実行ファイルに接続文字列を書きそれを
Ndb.cfg名のテキスト ファイルに入れこのファイルを実行ファイルの起動ディレクトリに入れます。
しかし、これらは現在あまり利用されていないため新しいインストールには使用されません。
接続文字列の指定で推奨している方法は接続文字列をコマンドラインに設定するかあるいは各実行ファイルの
my.cnf ファイルで設定します。
[NDB_MGMD]
セクションはマネジメント
サーバーの振る舞いを設定するために使用します。[MGM]
が別名として使用されます。この 2
つのセクション名は同じです。以下のリストのすべてのパラメータはオプションで省略されるとデフォルトの値になります。注:ExecuteOnComputer
または HostName
パラメータのどちらも存在しない場合、デフォルトの値
localhost
がその両方の値に使用されます。
クラスタの各ノードにはそれぞれ一意の ID があり、1 〜63 の整数値で表されます。この ID はすべての内部のクラスタ メッセージでノードを示すために使用されます。
これは
config.iniファイルの[COMPYUTER]セクションで定義されたコンピュータの中の 1 台の コンピュータのidセットの意味します。これはポート番号でこれによりマネジメント サーバーが設定要求およびマネジメント コマンドを受け取ります。
このパラメータを指定するとマネジメント ノードが常駐するコンピュータのホスト名を定義します。
localhost以外のホスト名を指定するには、このパラメータあるいはExecuteOnComputerのいずれかが必要です。このパラメータはクラスタのログインの情報をどこに送るかを指定します。この点に関しては ?
FILEをデフォルトとしてCONSOLE、SYSLOG? およびFILEの 3 つのオプションがあります。CONSOLEはログをstdoutに出力します。CONSOLE
SYSLOGはログをsyslogファシリティに送ります。可能な値はこれらauth、authpriv、cron、daemon、ftp、kern、lpr、mail、news、syslog、user、uucp、local0、local1、local2、local3、local4、local5、local6あるいはlocal7の内の1つです。注:すべてのファシリティが必ずしもすべてのオペレーティング システムでサポートされる必要はありません。
SYSLOG:facility=syslog
FILEクラスタのログ出力を同じマシンの通常のファイル送ります。以下の値を指定できます。filename:ログ ファイルの名前です。maxsize:ファイルがロールオーバーして新しいファイルに切り替わる前の最大サイズ (バイト表示)。これが起こると、古いログ ファイルはファイル名に.Nが付いたファイル名に変わります。Nはこの名前でまだ使用されていない次の番号になります。maxfiles:ログ ファイルの最大数です。
FILE:filename=cluster.log,maxsize=1000000,maxfiles=6
FILEパラメータのデフォルトの値はFILE:filename=ndb_です。node_id_cluster.log,maxsize=1000000,maxfiles=6node_idはノードの ID です。
以下に示すようにセミコロンで区切って複数のログ ディスティネーションを指定できます。
CONSOLE;SYSLOG:facility=local0;FILE:filename=/var/log/mgmd
このパラメータはどのノードがアービトレーターとしての役割を果たすかを定義します。MGM ノードおよび SQL ノードのみがアービトレーターになれます。
ArbitrationRankは以下の値の 1 つを取ることができます。0: このノードはアービトレーターとしては使用されません。1: このノードは優先度が高く、つまり、低い優先度のノードに対してアービトレーターとしての優先されます。2: は優先度の低いノードを意味し、優先度の高いノードがその目的に利用できないときにのみアービトレーターとして使用されます。
通常、マネジメント サーバーはその
ArbitrationRankで 1 (デフォルトの値) でアービトレーターとして設定され、SQL ノードは 0 に設定されます。マネジメント サーバーのアービトレーションの要求への応答をミリセカンドの数値で遅延させる整数値ですデフォルトではこの値は 0 です。通常はこの値を変更する必要はありません。
これはマネジメント サーバーの出力ファイルを格納するディレクトリを指定します。これらのファイルはクラスタ ログ ファイル、プロセス出力ファイル、およびデーモンのプロセス ID (PID) ファイルを含んでいます。(ログ ファイルでは、このロケーションはこの項で以前説明したように
FILEパラメータをLogDestinationに設定すると書き換えらえます。このパラメータのデフォルトの値はディレクトリで、その中に ndb_mgmd があります。
[NDBD] および [NDBD DEFAULT]
セクションはクラスタのデータノードの振る舞いを設定するために使用されます。バッファ
サイズ、プール
サイズ、タイムアウトなどを管理する多くのパラメータがあります。唯一必須のパラメータは:
ExecuteOnComputerあるいはHostNameのいずれかは、[NDBD]セクションで定義される必要があります。パラメータ
NoOfReplicasはそれがすべてのクラスタ データ ノードに共通なため、 [NDBD DEFAULT] セクションで定義する必要があります。
ほとんどのデータ ノードのパラメータは
[NDBD DEFAULT]
セクションで設定されます。ローカル値を設定できる明示的に指定されたパラメータのみが
[NDBD]
セクションで変更できます。存在する場合、HostName、Id
および ExecuteOnComputer
はローカルの [NDBD]
セクションで定義され、config.ini
の他のセクションでは定義されません。換言すれば、これらのパラメータは
1 つのデータ ノード固有のものです。
メモリの使用およびバッファ
サイズに影響を及ぼすパラメータは、K、M、あるいはG
を 1024、1024×1024、あるいは
1024×1024×1024
の単位を示す接尾辞として使用できます。
(例えば、100K は 100 × 1024 =
102400
の意味です。)パラメータ名および値は現在ケース
センシティブです。
Id 値 (つまり、データ
ノードの識別子)
はノードが起動されたときあるいは設定ファイルでコマンドラインに割り当てることができます。
これはすべてのクラスタの内部メッセージのノードのアドレスとして使用されるノード ID です。これは 1 〜 63 までの整数です。クラスタの各ノードは一意の ID を持つ必要があります。
これは
[COMPUTER]セクションで定義されたコンピュータのldセットです。このパラメータを指定するとデータ ノードが常駐するコンピュータのホスト名を定義します。
localhost以外のホスト名を指定するには、このパラメータあるいはExecuteOnComputerのいずれかが必要です。クラスタの各ノードは他のノードに接続するためにポートを使用しています。このポートはまた接続設定段階の非 TCP トランスポーターに使用されています。デフォルトのポートは同じコンピュータ上の 2 つのノードが同じポート番号を受信しないようにダイナミックに割り当てられているため、通常このパラメータの値を指定する必要はありません。
このグローバル パラメータは
[NDBD DEFAULT]セクションでのみ設定され、クラスタに保持された各テーブルのレプリカを番号を定義します。このパラメータはまたノード グループのサイズを指定します。ノード グループはすべて同じ情報を保持した一連のノードです。ノード グループは明示的に形成されます。最初のノード グループは最も低いノード ID を持つデータ ノードのセットで形成され、次のノード グループは次に最も低いノード ID のデータ セットで形成されます。参考例として、
NoOfReplicasが 2 に設定された 4 つのデータ ノードがあるとします。その 4 つのデータ ノードのノード ID を 2, 3, 4 および 5 とします。すると最初のノード グループはノードの 2 および 3 から形成され、2 番目のノード グループのノードは 4 と 5 になります。同じノード グループのノードは同じコンピュータには使用しないようにクラスタを設定する必要があります。というのは、1 つのハードウェアの不具合がクラスタ全体のクラッシュにつながるからです。ノード ID が提供されていない場合、データノードの順序はノード グループの決定要素になります。明示の割り当てがされるされないに拘わらす、それらはマネジメント クライアントの
SHOWステートメントの出力に表示されます。NoOfReplicasにはデフォルトの値はありません。最大の可能な値は 4 です。重要このパラメータの値はクラスタのデータ ノード数に同等に分けられる必要があります。例えば、2 つのデータ ノードがあるとすると、
NoOfReplicasは 1 あるいは 2 のいずれかに同じで、2/3 および 2/4 は両方とも機能的な値になります。4 つのデータ ノードがあるとすると、NoOfReplicasは 1、2、あるいは 4 に同じになります。このパラメータはトレース ファイル、pid ファイルおよびエラーファイルを格納するディレクトリを指定します。
このパラメータはメタデータ、REDO ログ、UNDO ログおよびデータ ファイルに作成されたすべてのファイルを格納するディレクトリを指定します。デフォルトは
DataDirで指定されたディレクトリです。注:このディレクトリは ndbd プロセスが実行される前に存在する必要があります。MySQL Cluster の推奨されるディレクトリの階層には
/var/lib/mysql-clusterが含まれます。そこでノードのファイル システムのディレクトリが作成されます。このサブディレクトリの名前にはノード ID が含まれます。例えば、ノード ID が 2 の場合、このサブディレクトリの名前はndb_2_fsとなります。このパラメータはバックアップを格納するディレクトリを指定します。省略された場合、デフォルトのバックアップ ロケーションは
FileSystemPathパラメータで指定されたロケーションの下のBACKUPの名前のディレクトリになります。(上記参照。)
DataMemory および
IndexMemory は [NDBD]
パラメータで、実際のレコードおよびそれらのインデックスを保持するメモリ
シグメントのサイズを指定します。これらの値を設定する際に、DataMemory
および IndexMemory
がどのように使われるかを知っておくことが重要です。なぜなら、それらはクラスタの実際の使用を反映して更新される必要があるからです。
このパラメータはデータベースのレコードを保持するスペース(バイト表示)を定義します。この値で指定される全体量はメモリで割り当てられます。ですからマシンにそれを収容できる十分な物理メモリがあることが非常に重要です。
DataMemoryで割り当てられたメモリは実際のレコードおよびインデックスの保持に使用されます。各レコードには 16 バイトのオーバーヘッドがあります。各レコードはそれが 32KB ページで 128 バイト ページのオーバーヘッドに保持されるのでさらに使用できないスペースが増えます。 (下参照)。各レコードは 1 ページにしか保存されないので、各ページ毎に使用できないスペース少しずつあります。MySQL 5.1 の可変サイズ テーブル属性により、データは
DataMemoryから割り当てられた個別のデータページに保持されます。可変長レコードには 4 バイトのオーバーヘッドの固定サイズ部分を使用し可変サイズ部分を参照します。可変サイズ部分には 2 バイトのオーバーヘッドと属性毎に 2 バイトのオーバーヘッドがあります。最大のレコード サイズは現在 8052 バイトです。
DataMemoryで定義されたメモリ スペースは、レコード毎に 10 バイトを使用する順序付けされたインデックスの保持にも使用されます。各テーブル行は順序づけされたインデックスで表されます。ユーザー間での共通のエラーはすべてのインデックスはIndexMemoryで割り当てられたメモリに保持されるためと想定できるが、これがすべてではありません。プライマリ キーと一意のハッシュ インデックスのみがこのメモリを使用します。順序付けされたインデックスはDataMemoryで割り当てられたメモリを使用します。しかし、プライマリ キーあるいは一意のハッシュ インデックスを作成すると インデックス作成ステートメントのUSING HASHを指定しない限り同じキーで順序付けされたインデックスも作成されます。これはマネジメント クライアントの ndb_desc -ddb_nametable_nameを実行してと検証できます。DataMemoryで割り当てられたメモリ スペースはテーブル フラグメントに割り当てられた 32KB のページで構成されます。各テーブルはクラスタにデータ ノードがあるため通常同じ数のフラグメントにパーテッションされます。このように、各ノードに対して、NoOfReplicasで設定された同数のフラグメントがあります。ページが割り当てられると、テーブルを削除する以外にフリーページのプールに戻すことは現在できません。(このことは
DataMemoryページが一度所定のテーブルに割り当てられると他のテーブルで使用できないということを意味しています。)すべてのレコードが他の生きたノードから空のパーティッションに挿入されるため、ノードのリカバリを実行するとパーテッションを圧縮します。DataMemoryメモリ スペースはまた UNDO 情報を含んでいます。更新毎に、変更されないレコードのコピーがDataMemoryで割り当てられます。順序付けされたテーブル インデックスに各コピーの参照があります。一意のハッシュ インデックスは一意のインデックスのカラムが更新されたときのみ更新されます。その場合、インデックス テーブルでの新しいエントリが挿入されその挿入によって古いエントリは削除されます。このため、クラスタを使用したアプリケーションの大きなトランザクションを扱うのに十分なメモリを割り当てることも重要です。いずれにしても、いくつかの大きなトランザクションを実行することは、以下の理由によって多くの小さなトランザクションを実行するのに対して優位性がある訳ではありません。大きなトランザクションは小さなトランザクションより早い訳ではない
大きなトランザクションは失われるオペレーション数が増えるので、トランザクションが失敗した場合には繰返す必要がある
大きなトランザクションは多くのメモリを使用する
DataMemoryのデフォルトの値は 80MBです。最小は 1 MB です。最大サイズはありませんが、現実的には制限に達したときプロセスがスワップしないように最大サイズを決める必要があります。制限はマシンで利用できる物理 RAM の容量およびオペレーティング システムがプロセスの実行に必要な容量によって決まります。32 ビットのオペレーティング システムは一般的にはプロセス毎では 2?4GB ですので、64 ビットのオペレーティング システムはさらに多くのメモリを使用できます。この理由により大きなデータベースの場合、64 ビットのオペレーティング システムの使用が望まれます。このメモリは MySQL のハッシュ インデックスに使用されるストレージ量を管理します。ハッシュ インデックスは常にプライマリ キーのインデックス、独自のインデックス、および独自の制約に使用されます。プライマリ キーおよび独自のインデックスを定義する際、2 つのインデックスが作成され、その 1 つがすべての tuple アクセスおよびロックの取扱いに使用されるハッシュのインデックスです。それはまた独自の制約の強化にも使用されます。
ハッシュ インデックスのサイズはレコード毎に 25 バイトで、それにプライマリ キーのサイズが加わります。32 バイト以上のプライマリ キーには別に 8 バイト追加されます。
IndexMemoryのデフォルトの値は 18MB です。最低は 1MB です。このパラメータは例えばテーブル名などの文字列に使用されるメモリ容量に割り当てを決定し、
config.iniの[NDBD]あるいは[NDBD DEFAULT]セクションで指定されます。0および100の間の値は最大のデフォルトの値のパーセントで、テーブル数、最大のテーブル名のサイズ、最大の.FRMファイル、MaxNoOfTriggers、最大のカラム名のサイズ、および最大のデフォルトのカラムの値などを含む多くの要素に基づいて算出されます。一般的には1000 のテーブルを持つ MySQL Cluster の場合の最大のデフォルト値はおよそ 5 MB にすると安全です。100より大きい値はバイト数を意味します。デフォルトの値が
5? の場合、つまりデフォルトの最大の 5 パーセントあるいはおよそ 5 KB です。(これが MySQL Cluster の以前のバージョンからの変更点です。)ほとんどの環境で、そのデフォルト値で十分ですが、非常に大きなクラスタ テーブル (1000 あるいはそれ以上) の場合、エラー 773 が出る場合があります。文字列メモリで、StringMemory config のパラメータを変更してください。恒久的なエラー:スキーマのエラー で、この場合この値を「増やします。
25(25 パーセント) でも良いでしょう。これですべてのしかも最も極端が場合のエラーの再発を妨げる必要があります。
以下の例でテーブルにメモリがどのように使用され手いるか説明します。このテーブルの定義を考慮します。
CREATE TABLE example ( a INT NOT NULL, b INT NOT NULL, c INT NOT NULL, PRIMARY KEY(a), UNIQUE(b) ) ENGINE=NDBCLUSTER;
各レコードには 12 バイトのデータと 12
バイトのオーバーヘッドがあります。無効なカラムを無くすと
4
バイトのオーバーヘッドを節約できます。さらに、カラム
a と b
にレコード毎におよそ 10
バイト使用する順序付けされた 2
つのインデックスがあります。ベース
テーブルにレコード毎におよそ 29
バイト使用するプライマリ キーのハッシュ
インデックスがあります。独自の制約はプライマリ
キーとして b
およびカラムとして a
を持つ個別のテーブルにより課されます。この他のテーブルは
example
テーブルでさらにレコード毎に 29
バイトのインデックス メモリおよびレコード
データに 8 バイトおよびオーバーヘッドに 12
バイト使用します。
このように、100 万のレコードでは、プライマリ キーと独自の制約のハッシュ インデックス処理に 58MB のインデックス メモリが必要です。さらに、ベース テーブルと独自のインデックス テーブル、および 2 つの順序付けされたインデックス テーブルのレコードに 64MB 必要です。
この様にハッシュ インデックスはかなりのメモリ スペースを必要としますが、その代わりに高速のデータ アクセスを提供します。それらはまた独自の制約を処理するために MySQL で使用されています。
現在、パーテッション アルゴリズムはハッシュのみで順序付けされたインデックスは各ノードに対してローカルです。このように、順序付けされたインデックスは一般的には独自の制約の処理には使用できません。
IndexMemory および
DataMemory
の重要な点は、各ノード
グループのデータベース
サイズの合計はすべてのデータ
メモリおよびすべてのインデックス
メモリの合計であるということです。各ノード
グループはレプリケート (複製)
された情報の保持に使用されますので、 2
つのレプリカを持つ 4 つのノードがあれば、2
つのノード
グループがあることになります。このように、利用可能なデータ
メモリの合計は各データ ノードに対して 2
× DataMemory です。
DataMemory と
IndexMemory
を全てのノードに対して同じ値で設定するよう強くお勧めします。クラスタではデータの配布はすべてのノードで同一ですので、各ノードの最大利用可能スペースはクラスタで一番小さいノード スペースより大きくなることはできません。
DataMemory と
IndexMemory
は変更できますが、これらのいずれかを少なくすることは危険で、そうすることによってノードあるいは
MySQL Cluster 全体がメモリ
スペースの不足によって再起動できなくなります。これらの値を増やすことは容認できますが、そのようなアップグレードをする場合にはソフトウェアのアップグレードと同じ方法で、つまり設定ファイルのアップグレード、次に各データ
ノードを順番に再起動してからマネジメント
サーバーを再起動するようお勧めします。
アップグレードによって使用できるインデックス メモリの量は増えません。挿入は直ぐできます。しかし、行はトランザクションが実施されるまで実際は削除されません。
これから説明する次の 3 つの
[NDBD]
パラメータは重要です。なぜなら、それらはシステムが処理する並列トランザクション数およびトランザクションのサイズに影響を及ぼすからです。MaxNoOfConcurrentTransactions
はノードで可能な並列トランザクション数を設定します。MaxNoOfConcurrentOperations
は更新段階およびあるいは同時ロック時のレコード数を設定します。
これらのパラメータはどちらも (特に
MaxNoOfConcurrentOperations は)
特定の値をしかもデフォルトの値を使用しないで設定する
ユーザーにとっては目標値になると思われます。デフォルトの値はこれらの値が過剰なメモリを使用しないように確認するために、小さなトランザクションを使用してシステムに設定されます。
クラスタのアクテイブなそれぞれトランザクションはクラスタ ノードの 1 つにレコードを持つ必要があります。協調的なトランザクションはノード間で実行されます。クラスタのトランザクション レコードの合計数はクラスタの所定のノードのトランザクション数にノードを乗算した数になります。
トランザクション レコードは個々の MySQL サーバーに割り当てられます。通常は、少なくてもクラスタのテーブルを使用している少なくても 1 つのトランザクション レコードが接続毎に割り当てられます。このため、クラスタのトランザクション レコード数がクラスタの すべての MySQL サーバーに同時接続している数よりも多いことを確認する必要があります。
このパラメータは全てのクラスタ ノードに対し同じ値を設定する必要があります。
このパラメータを変更することは安全ではなく、変更することによってクラスタがクラッシュする場合があります。ノードがクラッシュすると、ノードの 1 つ (実際は一番最後までクラッシュしないで残ったノード) がクラッシュしたときにクラッシュしたノードで進行中のすべてのトランザクションの状態に戻します。ですからこのノードが失敗したノードの出来るだけ多くのレコードを持っていることが重要です。
デフォルトの値は 4096 です。
このパラメータの値をトランザクション数やサイズに基づいて調整することはいい考えです。少数のオペレーションをそれぞれあまり多くのレコードを使用しないでトランザクションを実行するときには、このパラメータを高く設定する必要はありません。多くのレコードを含む大きなトランザクションを実行するするときにはこのパラメータを高く設定する必要があります。
レコードは各トランザクション毎に記録され、トランザクション コーディネーターおよび実際の更新が行われるノードでクラスタのデータを更新します。このレコードにはロールバック、ロック キュー、およびその他の目的のための UNDO レコードの検索に必要なステート情報が含まれます。
このパラメータはクラスタのデータ ノード数で除算した、トランザクションで同時に更新されるレコードの数に設定する必要があります。例えば、4 つのデータ ノードを持ち 1,000,000 の同時更新をトランザクションで処理するクラスタでは、この値を 1000000 / 4 = 250000 に設定する必要があります。
ロックを設定するクエリの読み込みでもオペレーション レコードが作成されます。ノードへの配布が完全でない場合にそれに対処するためにいくつかの予備のスペースが個々のノード内で割り当てられます。
クエリが独自のハッシュ インデックスを使用する場合、 トランザクションで実際にレコード毎に使用される 2 つのオペレーション レコードがあります。最初のレコードはインデックス テーブルの読み込みを行い、2 番目はベース テーブルのオペレーションを処理します。
デフォルトの値は 32768 です。
このパラメータは個別に設定される 2 つの値を扱います。これらの最初の値はトランザクション コーディネーターに配置するトランザクション レコード数を指定します。2 番目の値はデータベースに対してローカルにするオペレーション レコード数を指定します。
8 つのノードを使用したクラスタで実行される非常に大きなトランザクションのトランザクション コーディネーターにはトランザクションでの読み込み、更新、削除に相当するオペレーション レコードが必要です。しかし、オペレーション レコードは 8 つのノードすべて使用されます。このように、システムを 1 つの非常に大きなトランザクションに設定する必要がある場合には、2 つの部分を個別に設定するほうが良いでしょう。
MaxNoOfConcurrentOperationsはトランザクション コーディネーターのノード部分のオペレーション レコード数の算出に使用されます。オペレーション レコードにはメモリ要件を考慮に入れることも重要です。これらはレコード毎に約 1KB 使用します。
デフォルトでは、このパラメータは 1.1 ×
MaxNoOfConcurrentOperationsで算出されます。これはトランザクションがそれほど大きくない多くのトランザクションを同時に行うシステムに向いています。一度に非常に大きなトランザクションを扱う必要がある場合には、このパラメータを明示的に指定してデフォルト値をオーバーライドするのがいいでしょう。
次の [NDBD] パラメータ
セットはクラスタ
トランザクションの一部のステートメントを実行する際のテンポラリのストレージを決定するために使用されます。すべてのレコードがステートメントが完了しクラスタが実行あるいはロールバックを待っているときにリリースされます。
これらのパラメータのデフォルト値で殆どの状況をカバーします。しかし、多くの行数やオペレーションが絡むトランザクションのサポートが必要なユーザーはシステムの並列効果を高めるためにこれらの値を増やす必要がある場合があります。一方、トランザクション数が少ないアプリケーションのユーザーはメモリを節約するためにその値を下げることができます。
MaxNoOfConcurrentIndexOperations独自のハッシュ インデックスを使用したクエリでは、オペレーション レコードの別のテンポラリ セットがクエリの実行フェーズで使用されます。このパラメータセットはレコードのプール サイズを設定します。このように、レコードはクエリの一部を実行中にのみ割り当てられます。この部分が実行されるとすぐ、レコードがリリースされます。失敗や実行の処理に必要なステートは通常おオペレーション レコードで扱われ、プール サイズはパラメータ
MaxNoOfConcurrentOperationsで設定されます。このパラメータのデフォルトの値は 8192 です。ごく稀に独自のハッシュ インデックスを使用した極端に高い並列仕様においてはこの値を上げる必要があります。DBA がクラスタに高度な並列が要求されないことを確認できる場合、小さい値が可能でメモリを節約できます。
MaxNoOfFiredTriggersのデフォルトの値は 4000 です。これで殆どの状態に十分です。DBA がクラスタの並列仕様が高くないと確認できた場合、場合によっては値を下げることもできます。独自のハッシュ インデックスに影響を及ぼすオペレーションが実行されるとレコードが作成されます。独自のハッシュ インデックスでテーブルにレコードを挿入あるいは削除するあるいは独自のハッシュ インデックスの一部のカラムを更新するとインデックス テーブルの挿入や削除が無効になります。その結果のレコードは完了するためにオペレーションを無効にした元のオペレーションを待つ間にこのインデックス テーブルのオペレーションを代わりをするために使用されます。このオペレーションは短命ですが、それでも一連の独自のハッシュ インデックスのを含むベース テーブルで多くの並列書き込みオペレーションに対応するプールで多数のレコードを必要とします。
このパラメータで影響を受けたメモリはインデックス テーブルの更新や独自にインデックスを読み込むときに無効になったオペレーションの追跡に使用されます。このメモリはこれらのオペレーションのキーおよびカラムの情報を保持するために使用されます。このパラメータの値をデフォルトの値からの変更を必要とするケースは非常に稀です。
TransactionBufferMemoryのデフォルトの値は 1MB です通常の読み込み書き込みのオペレーションは同様のバッファを 1 つ使用します。その使用はもっと短命です。コンパイル時間のパラメータ
ZATTRBUF_FILESIZE(ndb/src/kernel/blocks/Dbtc/Dbtc.hppに表示) は 4000 × 128 バイト (500KB) に設定します。キー情報の同様のバッファは、ZDATABUF_FILESIZE(Dbtc.hppに表示) は 4000 × 16 = 62.5KB のバッファ スペースを含みます。Dbtcはトランザクションのコーディネーションを扱うモジュールです。
Dblqh モジュール
(ndb/src/kernel/blocks/Dblqh/Dblqh.hpp
にあります)
に読み込みと更新に影響を及ぼす追加の
[NDBD]
パラメータがあります。これらはデフォルトで
10000 × 128 バイト (1250KB) および
ZDATABUF_FILE_SIZE 、デフォルトで
10000*16 バイト (およそ 156KB) のバッファ
スペースに設定された
ZATTRINBUF_FILESIZE
を含みます。現在までのところ、これらのコンパイル時間制限を増やすべきだという弊社のユーザーおよび弊社の広範なテストでの結果もありません。
このパラメータはクラスタで実行される並列スキャン数の管理のために使用されます。各トランザクション コーディネーターはこのパラメータに定義された数の並列スキャンを処理します。各スキャンのクエリは並列の全てのパーティションをスキャンすることで実行できます。各パーティション スキャンはパーティションがあるノードのスキャン レコード、このパラメータの値であるレコード数にノード数を乗算したレコード数を使用します。クラスタは
MaxNoOfConcurrentScansスキャンをクラスタの全てのノードと同時に維持する必要があります。スキャンは実際には 2 つのケースで実行されます。この最初のケースはクエリを扱うハッシュあるいは順序付けされたインデックスが存在しないとき、クエリがテーブルのフル ャンを実行することで実行されます。2 番目のケースはクエリをサポートするハッシュ インデックスが無くて順序付けされたインデックスがある場合にスキャンが実行されます。順序付けされたインデックスを使用するということは並列の範囲スキャンを実行することを意味します。その順序はローカルのパーティッションにのみ維持されるので、すべてのパーティッションにインデックスのスキャンが行う必要があります。
MaxNoOfConcurrentScansのデフォルトの値は 256 です。最大値は 500 です。このパラメータはトランザクションのコーディネーターでの可能なスキャン数を指定します。ローカル スキャン数が提供されていない場合、
MaxNoOfConcurrentScansおよびシステムのデータ ノード数の積にによって計算されます。多くのスキャンが完全に並列化されない場合にローカルのスキャン レコード数を指定します。
このパラメータは多くの同時スキャン オペレーションを扱うロック レコード数の計算に使用されます。
デフォルトの値は 64 です。この値は SQL ノードで定義された
ScanBatchSizeと強い関連があります。これは内部のバッファーで個々のノード内およびノード間でメッセージを渡すために使用されます。これを変更する必要は殆ど考えられませんが、設定はできます。デフォルトでは 1MB に設定されます。
これらの [NDBD]
パラメータはログおよびチェックポイントの振る舞いを管理します。
このパラメータはノードの REDO (やり直し) ログ ファイル数を設定し、この様にREDO ロギングにスペースが割り当てられます。REDO ログ ファイルはリングに環状に構成されますので、そのセットの最初および最後のログ ファイル (それぞれ 「頭」 および 「尻尾」 ログ ファイルとも呼ばれる)が一致しないように設定することが非常に重要です。これらが互いにあまりも近づくと、新しいログ レコードのスペースが足りないためにノードが更新に関わるすべてのトランザクションを中断させる場合があります。
REDOログ ファイルはそのログ レコードが挿入されてから 3 回のローカル チェックポイントが完了するまで削除できません。チェックポイントの頻度はこの章の別の場所で説明したように、それ自身の一連の設定パラメータで決定されます。これらのパラメータの相互作用およびその設定については 項14.4.6. 「ローカル チェックポイントのパラメータの設定」 で説明しています。
デフォルトのパラメータ値は 8 ですので 8 セットの 4 16MB ファイルで合計 512MB になります。換言すれば、REDO ログ スペースは 64MB のブロックに割り当てられる必要があります。非常に多くの更新が要求される場合には、REDO ログに十分なスペースを提供するには
NoOfFragmentLogFilesの値は 300 あるいはそれ以上に高く設定する必要があります。チェックポイントが遅く、データベースへの書き込み数がログ ファイルが一杯になりログの尻尾がリカバリの悪化なしにカットできなくなるほど多い場合、すべての更新トランザクションは内部のエラーコード 410 (
Out of log file space temporarily) によって中断されます。この状態はチェックポイントが完了しログの尻尾が前進できるようになるまで続きます。重要このパラメータは 「稼働中」 には変更できません。
--initialを使用してノードを再起動する必要があります。この値をクラスタの稼働中の変更を希望する場合には、動作中のノードを再起動します。このパラメータはオープン ファイルに内部スレッド割り当て上限を設定します。このパラメータの変更が必要な状況が発生した場合にはバグ として報告お願いします。
デフォルトの値は 40 です。
このパラメータは古い値が書き換えられるまでのトレース ファイルの最大数を設定します。トレース ファイルは、どのような理由であれ、ノードがクラッシュすると生成されます。
デフォルトは 25 トレース ファイルです。
次の [NDBD] パラメータ
セットはメタデータ オブジェクトのプール
サイズを定義し、インデックス、イベント、およびクラスタ間のレプリケーションに使用される属性、テーブル、インデックス、およびトリガ
オブジェクトの最大数の定義に使用されます。これらはクラスタへの単なる
「助言」
で、ここに指定されない値は以下のデフォルトの値になります。
クラスタで定義される属性数を定義します。
デフォルトの値は 1000 で、最大の可能な値は 32 です。最大は 4294967039。すべてのメタデータはサーバーで完全にレプリケート (複製) されるため各属性はノード毎に約 200 バイトのストレージを使用します。
MaxNoOfAttributesを設定する前に、将来実行を希望するであろうALTER TABLEステートメントを事前に用意することが重要です。これは クラスタ テーブルでALTER TABLEを実行中に、元のテーブル 3 倍の属性が使用されるからです例えば、テーブルが 100 の属性を必要し、その変更を後で希望する場合、MaxNoOfAttributesの値を 300 に設定する必要があります。希望するすべてのテーブルを問題無く作成できるとして、経験則では念のために一番大きなテーブルで 2 倍の属性をMaxNoOfAttributesに追加します。パラメータを設定した後に実際のALTER TABLEを試してこの数字が十分であるか検証できます。その数字でうまくいかない場合、MaxNoOfAttributesを元の値の数倍に増やしてももう一度試してみます。各テーブル、独自のハッシュ インデックス、および順序付けられたインデックスにテーブル オブジェクトを割り当てられます。このパラメータは全体としてクラスタにテーブル オブジェクトの最大数を設定します。
BLOBのデータ タイプを持つ各属性に対して、ほとんどのBLOBデータを保持するために予備のテーブルが使用されます。これらのテーブルはテーブルの合計数を決める場合に考慮する必要があります。このパラメータのデフォルトの値は 128 です。最小は 8 で最大は 1600 です。各テーブル オブジェクトはおよそノード毎に 20KB を使用します。
クラスタの順番付けされたインデックスに対し、何にインデックスするかおよびそのストレージ セグメントを記述したオブジェクトが 1 つ割り当てられます。デフォルトでは、そのように定義された各インデックスはまた順番付けされたインデックスを定義します。それぞれの独自のインデックスおよびプライマリ キーは順序付けされたインデックスおよびハッシュ インデックスの両方を持っています。
このパラメータのデフォルトの値は 128 です。各オブジェクトはノード毎におよそ 10KB のデータを使用します。
プライマリ キー以外の各独自のインデックスに対して、独自のキーをインデックスの付いたテーブルのプライマリ キーマップする特別なテーブルが割り当てられます。デフォルトでは、順序付けされたインデックスもまた各独自のインデックスに定義されます。これを防ぐには、独自のインデックスを定義する際に
USING HASHオプションを指定する必要があります。デフォルトの値は 64です。各インデックスはノード毎におよそ 15KB 使用します。
内部のトリガの更新、挿入、および削除が各独自のハッシュ インデックスに割り当てられます。(これは 3 つのトリガが各独自のハッシュ インデックスに作成されることを意味します。)しかし、順序付けされた インデックスにはシングルのトリガ オブジェクトのみ必要です。バックアップもまた 3 つのトリガ オブジェクトをクラスタの各通常のテーブルに使用します。
クラスタ間のレプリケーションもまた内部のトリガを使用します。
このパラメータはクラスタのトリガ オブジェクトの最大数を設定します。
デフォルトの値は 768 です。
このパラメータは MySQL 5.1 は使用されない方向にあります。代わりに
MaxNoOfOrderedIndexesおよびMaxNoOfUniqueHashIndexesを使用する必要があります。このパラメータは独自のハッシュ インデックスのみで使用されます。このプールではクラスタで定義された各独自のインデックスに対しレコードが 1 つ必要です。
このパラメータのデフォルトの値は 128 です。
データ ノードの振る舞いも boolean
値に使用された [NDBD]
パラメータ
セットの影響を受けます。これらのパラメータはそれそれ
1 あるいは Y
に設定すると TRUE、および
0 あるいは N
に設定すると FALSE
を指定できます。
Solaris および Linux を含む多くのオペエーティング システムで、プロセスをメモリにロックしてディスクへのスワップを回避することができます。これはクラスタのリアルタイム特性を保証するために使用されます。
MySQL 5.1.15 以降の場合、このパラメータは
0、1、あるいは2のいずれかの整数値を取ります。それぞれ以下の役割があります。0: ロックを無効にします。これはデフォルトの値です。1: メモリをプロセスに割り当てた後にロックを実行します。2: メモリをプロセスに割り当てる前にロックを実行します。
以前は、このパラメータは Boolean でした。
0あるいはfalseはデフォルトに設定で、ロックを無効にしました。1あるいはtrueはメモリが割り当てられたあとのプロセスのロックを有効にしました。重要MySQL 5.1.15 以降では、trueあるいはfalseをもはやこのパラメータに使用できません。以前のバージョンからアアップグレードする場合には、その値を0、1、あるいは2に変更する必要があります。このパラメータはエラーが発生した場合に ndbd プロセスを終了するかあるいは自動的に再起動させるかを指定します。
この機能はデフォルトで有効になっています。
MySQL クラスタのテーブルを テーブルがディスクにチェックポイントされずロギングも発生しないDisklessに指定できます。そのようなテーブルは主メモリにのみ存在します。ディスク無しのテーブルを使用することによってそれらのテーブルのテーブルあるいはレコードのどちらもクラッシュの影響を受けないことを意味しています。.しかし、ディスク無しモードを起動中に、ディスク無しコンピュータで ndbd を実行できます。
重要この機能によりクラスタ 全体 をディスク無しモードで稼動できます。
この機能を有効にすると、クラスタのオンラインバックアップは無効になります。さらに、クラスタの部分的な起動が出来なくなります。
Disklessはデフォルトで無効になっています。この機能はデバッグ バージョンを作成中にのみアクセスでき、そこでエラーをコードの個々のブロックにテストの一部として挿入できます。
この機能はデフォルトで無効になっています。
タイムアウト、インターバル、およびディスク ページングの管理
クラスタ データ
ノードの様々な操作でのタイムアウトやインターバルを指定する多くの
[NDBD]
パラメータがあります。ほとんどのタイムアウトの値はミリセカンドで指定されます。値がミリセカンドでない場合にはその都度説明します。
主スレッドの無限ループのある地点でのスタックを避けるために、「監視」 スレッドが主スレッドをチェックします。このパラメータはチェック間のミリセカンド数を指定します。プロセスが 3 回のチェックの後でも同じ状態が続くようであれば、監視スレッドがそれを停止します。
パラメータは試験用あるいはローカル条件を採用するために簡単に変更できます。それは特にノード単位で指定する意味もないのだがノード単位で指定できます。
デフォルトのタイムアウトは 4000 ミリセカンド (4 秒) です。
このパラメータはクラスタの初期化ルーチンが起動される前のクラスタのすべてのノードが起動するまでの待機時間を指定します。このタイムアウトは必要に応じてクラスタの部分的起動を避けるために使用されます。
デフォルトの値は 30000 ミリセカンド(30 秒) です。0 でタイムアウトを無効にします。この場合クラスタはすべてのノードが利用できる段階で起動します。
クラスタが
StartPartialTimeoutミリセカンドの待機後に起動の用意が出来ても、まだパーティションの状態である場合、クラスタはこのタイムアウトが経過するまで待ちます。デフォルトのタイムアウトは 60000 ミリセカンド (60 秒) です。
データノードがこのパラメータで指定された時間内にその起動シーケンスを完了できない場合、そのノードの起動は失敗します。このパラメータを 0 (デフォルトの値) に設定するとデータ ノードのタイムアウトが適用されないことを意味します。
0 以外の値の場合、このパラメータはミリセカンドで測定されます。極端い大きな量のデータを含むデータ ノードには、このパラメータを大きくします。例えば、数ギガ バイトのデータを含むデータノードの場合、ノードの再起動を実行するには 10?15 分 (つまり、600000 から 1000000 ミリセカンド) が必要になります。
失敗したノードを見つける主な方法の 1 つにハートビートを使用する方法があります。このパラメータはハートビート信号の送受信の頻度を指定します。続けて 3 回ハートビート インターバルに失敗した場合、そのノードはデッドを宣言されます。このように、ハートビート メカニズムを使用した不具合発見の最大の回数はハートビート インターバルの 4 倍です。
デフォルトのハートビート インターバルは 1500 ミリセカンド (1.5 秒) です。.このパラメータを大幅に変更したりまたはノード間で大きく違わないようにします。1 つのノードが 5000 ミリセカンドを使用しそれを監視するノードが 1000 ミリセカンドを使用した場合、明らかにノードは直ちにデッドを宣言されます。このパラメータはオンラインのソフトウェアのアップグレード時に変更できますが、ほんの小さな増分だけです。
各データノードはハートビート信号を各 MySQL サーバー (SQL ノード) に送って接続されていることを確認します。MySQL サーバーがハートビートを時間内に送信できない場合 「デッド」 を宣言され、その場合すべての実行中のトランザクションは完了してすべてのリソースがリリースされます。SQL ノードは以前の MySQL インスタンスで始められたすべての操作が完了するまで再接続できません。この測定の 3 回のハートビート基準は
HeartbeatIntervalDbDbの説明と同じです。デフォルトのインターバルは 1500 ミリセカンド (1.5 秒) です。インターバルは個々のデータ ノード別にすることも出来ます。というのは、各ノードは接続された MySQL サーバーを監視し、他のすべてのデータ ノードから独立しているからです。
このパラメータはその例外で新しいローカルチェックポイントの起動までの待機時間を設定しません。これはむしろ、ローカルチェックポイントは比較的少ない更新が実行されるクラスタでは実行されないことを確認するために使用されます。更新回数が多い多くのクラスタでは、おそらく新しいローカル チェックポイントは前のチェックポイントが完了すると直ぐに開始されるからです。
前のローカル チェックポイントが開始されてから実行されたすべての書き込み操作のサイズが追加されます。このパラメータもその例外で 4 バイトの単語の基数 2 対数で指定されますので、デフォルト値の 20 は 4MB (4 × 220) の書き込み操作を意味し、21 は 8MB で、8 GB の書き込み操作に相当する最大値 31 まで続きます。
クラスタのすべての書き込み操作はが一緒に追加されます。
TimeBetweenLocalCheckpointsを 6 あるいはそれ以下に設定することはローカルのチェックポイントが、クラスタの負荷に関係なく休みなく継続的に実行されることを意味します。トランザクションがコミットされると、データがミラーされているすべてのノードの主メモリでコミットされます。しかし、トランザクションのルグ レコードはそのコミットの一部としてディスクにフラッシュされません。この振る舞いの背後にある論法はトランザクションを少なくとも 2 台の自律型ホスト マシン上で成功裏に実行するには持続性に於ける合理的な基準を満たす必要があるからです。
最悪の場合?クラスタの完全なクラッシュ?でも適切に処理されることを確認することも重要です。これを保証するには、所定のインターバル内に実行されるすべてのトランザクションをグローバル チェックポイントに設定すると、それがディスクにフラッシュされコミットされたとトランザクションのセットとして考慮されます。換言すれば、コミット プロセスの一部として、トランザクションがグローバル チェックポイントに組み入れられます。後でこのグループのログ レコードがディスクにフラッシュされ、トランザクション グループ全体がクラスタのすべてのコンピュータ上のディスクでコミットされます。
このパラメータはグローバル チェックポイント間のインターバルを定義します。デフォルトは 2000 ミリセカンドです。
TimeBetweenInactiveTransactionAbortCheckタイムアウトの処理はこのパラメータで指定されたインターバル毎に各トランザクションのタイマーを一度チェックすることで実行されます。この様に、このパラメータを 1000 ミリセカンドに設定すると、すべてのトランザクションは 1 秒毎にタイムアウトをチェックします。
デフォルトの値は 1000 ミリセカンド (1 秒) です。
このパラメータはトランザクションが中断される前の同じトランザクションのオペレーション間に許容された最大の経過時間を表します。
このパラメータのデフォルトはゼロ (タイムアウト無し) です。トランザクションのロックをあまり長くしないことを確認する必要のあるリアルタイムのデータベースでは、このパラメータは非常に小さい値に設定する必要があります。単位はミリセカンドです。
TransactionDeadlockDetectionTimeoutノードがトランザクションに関わるクエリを実行するとき、そのノードは継続する前にクラスタの他のノードが応答するまで待ちます。応答の失敗は以下の理由のいずれかで起こります。
そのノードが 「デッド」状態にある
オペレーションがロック キュウーの状態にある
アクションの実行をリクエストしたノードが過負荷にある
このタイムアウトのパラメータはトランザクション コーディネーターがトランザクションの中断にいたるまでの別のノードによるクエリを実行するまでの待機時間を示したもので、ノードの中断処理およびデッドロック検知の両方に重要です。その設定が高すぎるとデッドロックおよびノード中断を含む状態において望まない振る舞いを引き起こします。
デフォルトのタイムアウトは 1200 ミリセカンド (1.2 秒) です。
データをローカルのチェックポイント ファイルにフラッシュする前に保持するする最大バイト数です。
デフォルトの値は 4M (4 メガバイト) です。
このパラメータは MySQL 5.1.12 に追加されています。
ローカル チェックポイント中に転送されるデータ量をバイト/秒で表したものです。
デフォルトの値は 10M (10 メガバイト/秒) です。
このパラメータは MySQL 5.1.12 に追加されています。
ローカル チェックポイント中に再起動の操作の一部とし転送されるデータ量をバイト/秒で表したものです。
デフォルトの値は 100M (100 メガバイト/秒) です。
このパラメータは MySQL 5.1.12 に追加されています。
NoOfDiskPagesToDiskAfterRestartTUPローカル チェックポイント実行中に、アルゴリズムがすべてのデータページをディスクにフラッシュします。軽減策なしで単にそのように素早く行うのは過剰な負荷をプロセッサ、ネットワーク、およびディスクにかける場合があります。書き込み速度を管理するために、このパラメータは 100 ミリセカンド毎の書き込みページ数を指定します。ここでは 1 「 ページ」 は 8KB に定義されています。このパラメータは 80KB/秒単位で指定され、
NoOfDiskPagesToDiskAfterRestartTUPを20の値に設定するとローカル チェックポイント中のデータページでのディスクへの書き込み速度 1.6MB/秒を意味します。この値には UNDO ログ レコードのデータ ページへの書き込みが含まれています。つまり、このパラメータはデータ メモリの書き込み数の制限を扱っています。インデックス ページの UNDO ログ レコードはパラメータNoOfDiskPagesToDiskAfterRestartACCで処理されます。(インデックス ページに関する情報IndexMemoryは入力を参照してください。)要するに、このパラメータはローカル チェックポイントをどれだけ速く実施するかを指定します。それは
NoOfFragmentLogFiles、DataMemory、およびIndexMemoryと一緒に使用されます。これのパラメータのインターラクションおよびそれらの適切な値の選択肢に関する情報は、項14.4.6. 「ローカル チェックポイントのパラメータの設定」 を参照してください。
デフォルトの値は 40 (3.2MB/秒のデータ ページ) です。
注:このパラメータは MySQL 5.1.6 では使用頻度が下がっています。それはMySQL 5.1.12 およびそれ以降のバージョンは、 DiskCheckpointSpeed および DiskSyncSize を使用しているからです。.
NoOfDiskPagesToDiskAfterRestartACCこのパラメータは
NoOfDiskPagesToDiskAfterRestartTUPと同じ単位を使用し同じ役割を果たしますが、インデックス メモリからインデックス ページの書き込み速度を制限します。このパラメータのデフォルト値は 20 (1.6MB/秒 のインデックス メモリ ページ)。
注:このパラメータは MySQL 5.1.6 では使用頻度が下がっています。それはMySQL 5.1.12 およびそれ以降のバージョンは、 DiskCheckpointSpeed および DiskSyncSize を使用しているからです。.
NoOfDiskPagesToDiskDuringRestartTUPこのパラメータは
NoOfDiskPagesToDiskAfterRestartTUPおよびNoOfDiskPagesToDiskAfterRestartACCと同じ役割を果たしますが、ノードが再起動されて時にノードで実行されるローカルのチェックポイントに関してのみそのように振舞います。ローカル チェックポイントは常にすべてのノードの再起動の一部として実行されます。ノードの再起動中にはノードで実行される作業量が少ないため他の場合より高速でディスクに書き込みできます。このパラメータはデータ メモリで書き込まれたページをカバーしています。
デフォルトの値は 40 (3.2MB/秒) です。
注:このパラメータは MySQL 5.1.6 では使用頻度が減っています。それはMySQL 5.1.12 およびそれ以降のバージョンは、 DiskCheckpointSpeedInRestart および DiskSyncSize を使用しているからです。.
NoOfDiskPagesToDiskDuringRestartACCノードの再起動時のローカル チェックポイント中にディスク書き込まれるインデックスのメモリ ページ数を管理します。
NoOfDiskPagesToDiskAfterRestartTUPおよびNoOfDiskPagesToDiskAfterRestartACCと同じで、このパラメータ値は 100 ミリセカンド (80KB/秒) で書き込まれた 8KB ページを表します。デフォルトの値は 20 (1.6MB/秒) です。
注:このパラメータは MySQL 5.1.6 では使用頻度が減っています。。それは MySQL 5.1.12 およびそれ以降のバージョンは、 DiskCheckpointSpeedInRestart および DiskSyncSize を使用しているからです。.
このパラメータはデータ ノードのアービトレーターからアービトレーション メッセージへの応答の待機時間を指定します。この待機時間を過ぎると、ネットワークは切断されたものとみなされます。
デフォルトの値は 1000 ミリセカンド (1 秒) です。
すべての更新はログに記録する必要があります。REDO ログはこれらの更新をシステムが再起動されたときにはいつでも実行できるようにします。NDB リカバリ アルゴリズムはデータの 「ファジー」 チェックポイントを UNDO ログと一緒に使用し、REDO ログを使用してすべての変更を修復ポイントまで再現します。
RedoBuffer は REDO
ログが書き込まれるバッファのサイズを設定します。デフォルトでは
8MB です。このバッファは REDO
ログのレコードをディスクに書き込む際のファイル
システムへのフロント
エンドとして使用されます。このバッファが小さ過ぎると、NDB
ストレージ エンジンがエラーコード 1221
(REDO log buffers overloaded
を発行します)。
最小値は 1MB
です。ノードがディスク無しの状態で実行されると、ディスクの書き込みが
NDB ストレージ
エンジンのファイルシステム抽出レイヤによって
「フェイク」
されるため、これらのパラメータはペナルティ無しで最小値に設定されます。
重要ローリングの再起動時にこのパラメータを下げることは安全ではありません。
注:MySQL
の以前のバージョンの
UndoIndexBuffer および
UndoDataBuffer パラメータは MySQL 5.1
ではもはや必要なくなりました(あったにしても)。
クラスタの管理においては、様々なイベントに関して
stdout に送られたログ
メッセージ数を管理できることが非常に重要です。各イベント
カテゴリでは、16 の実行可能なイベント
レベル (0〜15 番まで)
あります。イベントのレポートを所定のイベント
カテゴリのレベル 15
設定するとそのカテゴリのすべてのイベント
レポートが stdout
に送られます。0
に設定するとそのカテゴリにはイベント
レポートが無いことを意味します。
デフォルトでは、起動メッセージのみが
stdout
に送られます。残りのイベントレポート
レベルのデフォルトは 0
に設定されます。この理由はこれらのメッセージもまたマネジメント
サーバーのクラスタ
ログに送られるからです。
相似性のレベルをマネジメント クライアントに設定してどのイベント レベルをクラスタ ログでレコードするかを決めることができます。
プロセスの起動時に生成されたイベントのレポート レベルです。
デフォルトのレベルは 1 です。
ノードの優雅なシャットダウンの一部として生成されたイベントのレポート レベルです。
デフォルトのレベルは 0 です。
プライマリ キーの読み込み、更新数、挿入数、バッファ使用に関する情報など統計的なイベントのレポート レベルです。
デフォルトのレベル 0 です。
ローカルおよびグローバル チェックポイントにより生成されたイベントのレポート レベル。
デフォルトのレベルは 0 です。
ノード再起動時に生成されたイベントのレポート レベルです。
デフォルトのレベルは 0 です。
クラスタ ノード間の接続で生成されたイベントのレポート レベルです。
デフォルトのレベル 0 です。
全体としてクラスタによるエラーおよび警告により生成されたイベントのレポート レベルです。これらのエラーはノード障害に結びつくものではないが報告すべきだ思われるエラーです。
デフォルトのレベルは 0 です。
クラスタの一般的な状態に関する情報に生成されたイベントのレポート レベルです。
デフォルトのレベルは 0 です。
この項で説明した[NDBD]
パラメータはオンライン
バックアップの実行用に確保するメモリ
バッファを定義します。
バックアップの作成においては、データをディスクに転送する 2 種類のバッファがあります。バックアップのデータ バッファはノード テーブルのスキャンにより記録されたデータを書き込みむために使用されます。このバッファが
BackupWriteSize(以下参照) で指定されたレベルまで書き込まれると、そのページはディスクに転送されます。データをディスクに書き込んでいる間に、バックアップ プロセスではスペースがなくなるまでこのバッファに書き込みを続けます。スペースが無くなると、バックアップ プロセスがスキャンを停止し、ディスクへに書き込みによってメモリが増えてスキャンを継続できるようになるまで待ちます。デフォルトの値は 2MB です。
バックアップ ログのバッファはバックアップの実行中にそれがすべてのテーブルの書き込みのログ生成に使用されることを除いてバックアップ データ バッファと同様の役割を果たします。同様の原則が、バックアップ ログ バッファにスペースが無いときを除いてバックアップ データ バッファと同じようにこれらの ページの書き込みに適用されて、そのバックアップは失敗します。その理由により、バックアップ ログ バッファのサイズはバックアップ中の書き込みの負荷を処理するだけの十分な大きさが必要です。項14.8.4. 「クラスタ バックアップの設定」 参照。
このパラメータのデフォルトの値は殆どのアプリケーションに十分なものでなければなりません。実際のところ、バックアップの失敗はディスクへの書き込み速度が遅いよりはバックアップ ログ バッファが満杯になることによりよく起こります。ディスクのサブシステムがアプリケーションによる書き込み負荷対応するように設定されていない場合、クラスタは所定の作業を実行できなくなります。
クラスタ ノードの設定ではディスクあるいはネットワーク接続をボトルネックにするよりはプロセッサがボトルネックになるように構成するほうが望まれます。
デフォルトの値は 2MB です。
このパラメータは単純に
BackupDataBufferSizeとBackupLogBufferSizeの合計です。デフォルトの値は 2MB + 2MB = 4MB です。
重要
BackupDataBufferSizeおよびBackupLogBufferSizeの合計が 4MB 以上の場合、このパラメータはconfig.iniファイルでその合計として明示的に設定される必要があります。このパラメータはバックアップ ログおよびバンクアップ データ バッファによってディスクに書き込まれたメッセージのデフォルトサイズを指定します。
デフォルトの値は 32KB です。
このパラメータはバックアップ ログおよびバンクアップ データ バッファによってディスクに書き込まれたメッセージの最大サイズを指定します。
デフォルトの値は 256KB です。
重要これらのパラメータを指定する際は、以下の関係が真であることが必要です。そうでない場合、データ ノードは起動しません。
BackupDataBufferSize >= BackupWriteSize + 188KBBackupLogBufferSize >= BackupWriteSize + 16KBBackupMaxWriteSize >= BackupWriteSize
config.ini ファイルの
[MYSQLD] および [API]
のセクションは MySQL サーバー (SQL ノード)
およびクラスタ
データへのアクセスに使用される他のアプリケーション
(API ノード)
を定義します。表示されたパラメータのどれも必要ありません。コンピュータ名およびホスト名の提供が無い場合、ホストのいずれかが
SQL あるいは API ノードを使用できます。
一般的には、[MYSQLD]
セクションは SQL
インターフェースをクラスタに提供している
MySQL
サーバーを示すために使用され、[API]
セクションはクラスタのデータにアクセスしている
mysqld
プロセスよりはアプリケーションに使用されますが、2
つの名前は実際は同義語です。例えば、[API]
セクションの SQL
サーバーとしての役割を果たしている MySQL
サーバーにパラメータを記入できます。
Id値はすべてのクラスタの内部メッセージのノードを識別するために使用されます。それは 1 〜 63 の整数で、クラスタ無いのすべてのノード ID に対して一意出なければなりません。これは
config.iniファイルの[COMPYUTER]セクションで定義されたコンピュータ (ホスト) のidセットのことを意味します。このパラメータを指定することで SQL ノード (API ノード) が常駐するコンピュータのホスト名を定義します。
localhost以外のホスト名を指定するには、このパラメータあるいはExecuteOnComputerのいずれかが必要です。このパラメータはどのノードがアービトレーターとしての役割を果たすかを定義します。MGM ノードおよび SQL ノードの両方がアービトレーターになれます。0 の値は所定のノードがアービトレータとして使用されないことを意味し、1 の値はアービトレーターとしての優先度が高く、2 の値は優先度が低いことをいみします。通常の設定ではマネジメント サーバーをアービトレーターとして使用し、
ArbitrationRankを 1 (デフォルトt) に、すべての SQL ノードに対しては 0 に設定します。この値を 0 (デフォルト) 以外に設定するとアービトレーション要求に対するアービトレーターの応答は指定されたミリセカンド数によって遅延されます。通常この値を変更する必要はありません。
インデックスのフル テーブルあるいは範囲スキャンに翻訳されたクエリに対しては、レコードを適切なサイズで取り出すことがベスト パフォーマンスには重要です。適切なサイズをレコード数 (
BatchSize) およびバイト (BatchByteSize) の両方で設定できます。実際のバッチ サイズは両方のパラメータで制限されます。クエリが実行去れる速度はこのパラメータの設定によって 40% 以上変化します。今後のリリースでは、MySQL Server にクエリのの種類に基づいた適切なバッチ サイズに関するパラメータの設定を取り入れます。
このパラメータはバイト数で測定され、そのデフォルトの値は 32KB です。
このパラメータはレコード数で測定されそのデフォルトの設定値は 64 です。最大サイズは 992 です。
バッチ サイズは各データ ノードから送られる各バッチのサイズです。多くのスキャンは MySQL Server を並列の多くのノードからデータを余り多く受け取らないようにするために並列で行われます。このパラメータはすべてのノードに対してバッチの合計を制限します。
このパラメータのデフォルトの値は 256KB です。最大のサイズは 16MB です。
ここに表示しているmySQL
クライアントの SHOW STATUS
を使用して Cluster SQL として実行されている
MySQL サーバーから情報を入手できます。
mysql> SHOW STATUS LIKE 'ndb%';
+-----------------------------+---------------+
| Variable_name | Value |
+-----------------------------+---------------+
| Ndb_cluster_node_id | 5 |
| Ndb_config_from_host | 192.168.0.112 |
| Ndb_config_from_port | 1186 |
| Ndb_number_of_storage_nodes | 4 |
+-----------------------------+---------------+
4 rows in set (0.02 sec)
これらの Cluster システムのステータス変数に関する情報は、項4.2.5. 「ステータス変数」 を参照してください。
TCP/IP は MySQL Cluster
の接続を確立するデフォルトのトランスポート
メカニズムです。通常はCluster
が自動的に各ノード間、各データ
ノード間および MySQL
サーバーノード、および各データ
ノード間さらには各データ
ノードとマネジメント
サーバーの接続を設定しますので接続を定義する必要はありません。(この規則に対する
1 つの例外については、
項14.4.4.8. 「直接接続を使用した TCP/IP の接続」
を参照)config.ini ファイルの
[TCP]
セクションでクラスタのノード間の TCP/IP
接続を明示的に定義しています。
デフォルトの接続パラメータをオーバーライドするときにのみ接続を定義する必要があります。そのような場合、少なくとも
NodeId1、NodeId2、および変更するパラメータを定義する必要があります。
これらのパラメータのデフォルトの値を
[TCP DEFAULT]
セクションで設定することで変更することもできます。
2 つのノード間での接続を認識するには設定ファイルの
[TCP]セクションでそれらのノード ID を提供します。これらは 項14.4.4.6. 「SQL および他の API ノードの定義」 の説明にあるようにそれぞれのこれらのノードに対して同じ一意Id値をしています。TCP トランスポーターはオペレーティング システムに送信呼び出しを実行する前にバッファを使用してすべてのメッセージを保存します。このバッファが 64KB になると、そのコンテンツを送信します。これらはまた一通りのメッセージが完了すると送信されます。一時的な過負荷状態を処理するために、大きな送信バッファを定義することも出来ます。送信バッファのデフォルトのサイズは 256KB です。
配布されたメッセージのダイアグラムを調べるには、各メッセージを認識する必要があります。このパラメータを
Yに設定すると、メッセージ ID がネットワーク上に転送されます。この機能は生産ビルドでデフォルトによって無効にできます。-debugビルドで有効にします。このパラメータはブール パラメータ (
Yあるいは1に設定して有効にする。無効にするにはNあるいは0) に設定します。デフォルトでそれを無効に出来ます。有効にすると、すべてのメッセージのチェックサムが送信場ファに格納される前に計算されます。この機能によりメッセージが送信バッファで待機している間に、あるいは転送メカニズムで転化してないか確認します。これは他のノードの接続の確認に使用されるポート番号を正式に指定します。このパラメータはもはや使用されません。
データを TCP/IP ソケットから受信するときにバッファのサイズを指定するために使用されます。メモリを節約するとき以外に、このパラメータをそのデフォルトの値の 64KB からめったに変更する必要はありません。
データノード間の直接接続を使用してクラスタを設定するにはクラスタ
config.ini の [TCP]
セクションで接続されているデータノードの交差
IP
アドレスを明示的に指定する必要があります。
以下の例では、それぞれマネジメント
サーバー、SQL ノード、および 2
つのデータノードを持つ少なくとも 4
台のホストを持つクラスタを説明します。そのクラスタは全体として
LAN の172.23.72.*
サブネットに常駐します。通常のネットワーク接続に加えて、2
つのデータノードを標準の交差ケーブルを使用して直接接続し、以下の範囲の
1.1.0.* の IP
アドレスを使用して直接お互いに通信します。
# Management Server [NDB_MGMD] Id=1 HostName=172.23.72.20 # SQL Node [MYSQLD] Id=2 HostName=172.23.72.21 # Data Nodes [NDBD] Id=3 HostName=172.23.72.22 [NDBD] Id=4 HostName=172.23.72.23 # TCP/IP Connections [TCP] NodeId1=3 NodeId2=4 HostName1=1.1.0.1 HostName2=1.1.0.2
HostName
パラメータ、そこでは NN
は整数で、TCP/IP
の直接接続を指定する際にのみに使用されます。
データノード間の直接接続を使用することによってデータノードをスイッチ、ハブ、ルータなどの Ethernet デバイスを経由できるのでクラスタの全体的な効率が改善され、よってクラスタのレーテンシーを下げます。2 つ以上のデータノードでの直接接続の利点をこのように最大限に活用するには、同じノードグループの各データノードとそれぞれの他のデータノードを直接接続することが重要です。
MySQL Cluster
は共有メモリの転送を試みて可能であればそれを自動的に設定します。config.ini
ファイルの [SHM]
セクションでクラスタのノード間の共有メモリの接続を明示的に定義します。
共有メモリを接続方法として明示的に定義する際は、少なくとも
NodeId1、NodeId2
および ShmKey
を定義する必要があります。すべての他のパラメータには殆どのケースでよく動作するデフォルトの値があります。
重要SHM 機能は現在まだ実験的なものです。.それは正式には これまでリリースされた 5.1 を含む MySQL シリーズではサポートされていません。このことはその使用はお客ご自身の決断であるいは弊社のフリーのリソース (フォーラム、メールリスト) を使用してお客様の特定のケースに適切に使用できるか決める必要があります。
2 つのノード間の接続を識別するには、
NodeId1およびNodeId2としてそれぞれにノード識別子を提供する必要があります。共有メモリのセグメントを設定する場合には、整数として表されるノード ID を使用して個別に共有メモリのセグメントを通信に使用するために認識します。デフォルトの値はありません。
各 SHM 接続には共有メモリのセグメントがあり、ノード間のメッセージは送信者のよって送られ受信者によって読まれます。このセグメントのサイズは
ShmSizeによって認識されます。デフォルトの値は 1MB です。配布したメッセージのパスを辿るには、各メッセージに一意の識別子を付ける必要があります。このパラメータを
Yに設定するとこれらのメッセージ ID をネットワーク上でも転送できます。この機能は生産ビルドでデフォルトによって無効にできます。-debugビルドで有効にします。このパラメータは boolean (
Y/N) パラメータでデフォルトで無効にできます。有効にすると、すべてのメッセージのチェックサムが送信バッファ格納される前に計算されます。この機能により送信バッファで待機中のメッセージの破損を防ぎます。またそれによって転送中のデータの破損をチェックすることもできます。
config.ini ファイルの
[SCI] でセクションで クラスタ
ノード間の SCI (Scalable Coherent Interface)
接続を明示的に定義しています。MySQL での SCI
トランスポーターの使用は
--with-ndb-sci=
を使用して MySQL
バイナリがビルドされたときのみサポートされています。/your/path/to/SCIpath
は最低の lib を含みSISCI
バイナリおよびヘッダーファイルを含む
include
ディレクトリを含んだディレクトリを指す必要がります。(SCI
の詳細は 項14.12. 「MySQL Cluster での高速インターコネクトを使用する」
を参照してください。)
その他に、SCI には特別なハードウェアが必要です。
ndbd プロセス間の通信のときのみ SCI トランスポートを使用するよう強くお勧めします。またSCI トランスポーターを使用する際は ndbd プロセスが有効であること確認します。このため、SCI トランスポーターは少なくとも ndbd プロセスによる 2 つの専用の CPU を搭載したマシン上でのみ使用する必要があります。少なくとの ndbd プロセス毎に少なくとも 1 つの CPU を使用し、オペレーティング システムを動作させるための少なくとも 1 つのCPU 予備として残しておきます。
2 つのノード間の接続を識別するには、
NodeId1およびNodeId2としてそれぞれにノード識別子を提供する必要があります。これにより最初のクラスタ ノード (
NodeId1 による識別) 上で SCI ノード ID を識別します。SCI トランスポーターをノード間の個別のネットワークを使用する 2 枚の SCI カード間のファールオーバーに設定できます。これによってノード ID および最初のノードに使用される 2 番目の SCI カードを認識します。
これにより 2 番目のクラスタ ノード (
NodeId2により識別される) の SCI ノード ID を認識します。フェールオーバーを提供するために 2 つの SCI カードを使用する時は、このパラメータが 2 番目のノードに使用される 2 番目の SCI カードを認識します。
各 SCI トランスポートにはノード間の通信に使用される共有メモリのセグメントがあります。このセグメントのサイズをフォルト値の 1MB に設定すると殆どのアプリケーションに十分です。その値を小さく設定すると並列で多くの挿入を行う場合問題が出る場合があります。共有バッファが小さ過ぎると ndbd プロセスでクラッシュする場合があります。
SCI メディアの前にある小さなバッファが SCI ネットワークにメッセージを転送する前にメッセージを保存します。デフォルトでは 8KB に設定されています。弊社のベンチマークでは 64KB でパフォーマンスはベストですが、16KB ではこの数パーセントにしか届きませんが、それを 8KB 以上にした場合でも殆ど利点はありませんでした。
配布したメッセージをトレースするには各メッセージを独自に認識する必要があります。このパラメータを
Yに設定すると、メッセージ ID がネットワーク上に転送されます。この機能は生産ビルドでデフォルトによって無効にできます。-debugビルドで有効にします。このパラメータは boolean 値で、デフォルトで無効にできます。
Checksumが有効にすると、チェックサムは送信バッファに格納される前にすべてのメッセージに対して計算されます。この機能により 2 番目の送信バッファで待機中のメッセージの破損を防ぎます。またそれによって転送中のデータの破損をチェックすることもできます。
次の 3 項ではクラスタの機能を管理する
config.ini ファイルに使用される
MySQL Cluster
の設定パラメータの概要テーブルを提供します。各テーブルでは、パラメータの種類およびその利用できるデフォルト、最小、および最大クラスタ
ノードを含むプロセスの種類
(ndbd、ndb_mgmd、および
mysqld) の 1
つのパラメータを説明します。
またどのような再起動
(ノードの再起動あるいはシステムの再起動)
?
が必要で、所定の設定パラメータの値を変更するために
--initial ?
の再起動しなければならないかどうかに付いて述べます。このパラメータは各テーブルの
Restart Type
カラムにあり、リストにある値の 1
つを含んでいます。
N:ノードの再起動IN:最初のノードの再起動S:システムの再起動IS:最初のシステムの再起動
ノードを再起動あるいは最初のノードの再起動には、すべてのクラスタのデータノードが順番に再起動
(ルーリング再起動 とも言う)
する必要があります。N あるいは
IN
の印の付いたクラスタの設定パラメータををオンラインで
?
変更できます。つまり、クラスタをシャットダウンしないで?
変更できます。最初のノードの再起動をするには各
ndbd プロセスを
--initial
オプションで再起動する必要があります。
システムの再起動にはシステムを完全にシャットダウンしクラスタ全体を再起動します。最初のシステムの再起動する際はクラスタのバックアップを取り、シャットダウンした後にクラスタのファイルシステムを消去し、次に再起動の後にバックアップを保存します。
どのクラスタを再起動する場合でも、クラスタの更新された設定パラメータの値を読ませるために、すべてのクラスタ マネジメント サーバーを再起動する必要があります。
重要数値クラスタのパラメータは一般的には問題なく上げることができます。しかし、それらを上げる場合には比較的に小さな増分で調整しながら徐々に上げるのがよいでしょう。しかし、そのようなパラメータの値を下げる場合には? 特にメモリの使用およびディスク スペース? に関わるものは簡単に変更しないで、慎重に計画してテストをした上で変更することをお勧めします。さらに、簡単なノードの再起動を使用して上げられるメモリおよびディスクの使用に関するパラメータ一般的には最初のノードの再起動を下げる必要があります。
なぜなら、これらのパラメータの中には 1 つ以上のクラスタの設定に使用されるものがあり、1 つ以上のテーブルに使用されている場合があるからです。
(これらのテーブルの最大値として使用される
4294967039 ?? は
232 ?
28 ? 1
と等価です。)
以下のテーブルは MySQL Cluster
のデータノードを設定する
config.ini
ファイルの[NDBD] あるいは
[NDB_DEFAULT]
セクションで使用されるパラメータに関する情報を提供します。これらのパラメータの詳細な説明および補足情報に関しては、項14.4.4.5. 「Defining Data Nodes」
を参照してください。
再起動のタイプ カラム値
N:ノードの再起動IN:最初のノードの再起動S:システムの再起動IS:最初のシステムの再起動
これらの略語の説明は 項14.4.5. 「クラスタ設定パラメータの概要」 を参照してください。
| パラメータ名 | タイプ/単位 | デフォルト値 | 最小値 | 最大値 | 再起動のタイプ |
ArbitrationTimeout | ミリセカンド | 1000 | 10 | 4294967039 | N |
BackupDataBufferSize | バイト | 2M | 0 | 4294967039 | N |
BackupDataDir | 文字列 | | N/A | N/A | IN |
BackupLogBufferSize | バイト | 2M | 0 | 4294967039 | N |
BackupMemory | バイト | 4M | 0 | 4294967039 | N |
BackupWriteSize | バイト | 32K | 2K | 4294967039 | N |
BackupMaxWriteSize | バイト | 256K | 2K | 4294967039 | N |
BatchSizePerLocalScan | 整数 | 64 | 1 | 992 | N |
DataDir | 文字列 | /var/lib/mysql-cluster | N/A | N/A | IN |
DataMemory | バイト | 80M | 1M | 1024G (利用できるシステムの RAM および
IndexMemory のサイズによる) | N |
Diskless | true|false (1|0) | 0 | 0 | 1 | IS |
ExecuteOnComputer | 整数 | ? | ? | ? | ? |
FileSystemPath | 文字列 | DataDir に指定された値 | N/A | N/A | IN |
HeartbeatIntervalDbApi | ミリセカンド | 1500 | 100 | 4294967039 | N |
HeartbeatIntervalDbDb | ミリセカンド | 1500 | 10 | 4294967039 | N |
HostName | 文字列 | localhost | N/A | N/A | S |
Id | 整数 | なし | 1 | 63 | N |
IndexMemory | バイト | 18M | 1M | 1024G (利用できるシステムの RAM および
DataMemory のサイズによる) | N |
LockPagesInMainMemory | MySQL 5.1.15の場合:整数;
以前の:true|false
(1|0) | 0 | 0 | 1 | N |
LogLevelCheckpoint | 整数 | 0 | 0 | 15 | IN |
LogLevelConnection | 整数 | 0 | 0 | 15 | N |
LogLevelError | 整数 | 0 | 0 | 15 | N |
LogLevelInfo | 整数 | 0 | 0 | 15 | N |
LogLevelNodeRestart | 整数 | 0 | 0 | 15 | N |
LogLevelShutdown | 整数 | 0 | 0 | 15 | N |
LogLevelStartup | 整数 | 1 | 0 | 15 | N |
LogLevelStatistic | 整数 | 0 | 0 | 15 | N |
LongMessageBuffer | バイト | 1M | 512K | 4294967039 | N |
MaxNoOfAttributes | 整数 | 1000 | 32 | 4294967039 | N |
MaxNoOfConcurrentIndexOperations | 整数 | 8K | 0 | 4294967039 | N |
MaxNoOfConcurrentOperations | 整数 | 32768 | 32 | 4294967039 | N |
MaxNoOfConcurrentScans | 整数 | 256 | 2 | 500 | N |
MaxNoOfConcurrentTransactions | 整数 | 4096 | 32 | 4294967039 | N |
MaxNoOfFiredTriggers | 整数 | 4000 | 0 | 4294967039 | N |
MaxNoOfIndexes
(専用 ?
代わりに MaxNoOfOrderedIndexes
あるいは
MaxNoOfUniqueHashIndexes
を使用する) | 整数 | 128 | 0 | 4294967039 | N |
MaxNoOfLocalOperations | 整数 | UNDEFINED | 32 | 4294967039 | N |
MaxNoOfLocalScans | 整数 | UNDEFINED | 32 | 4294967039 | N |
MaxNoOfOrderedIndexes | 整数 | 128 | 0 | 4294967039 | N |
MaxNoOfSavedMessages | 整数 | 25 | 0 | 4294967039 | N |
MaxNoOfTables | 整数 | 128 | 8 | 4294967039 | N |
MaxNoOfTriggers | 整数 | 768 | 0 | 4294967039 | N |
MaxNoOfUniqueHashIndexes | 整数 | 64 | 0 | 4294967039 | N |
NoOfDiskPagesToDiskAfterRestartACC
(減少 MySQL 5.1.6 の場合) | 整数 (8KB ページ数/100 ミリセカンド) | 20 (= 20 * 80KB = 1.6MB/秒) | 1 | 4294967039 | N |
NoOfDiskPagesToDiskAfterRestartTUP
(減少 MySQL 5.1.6 の場合) | 整数 (8KB ページ数/100 ミリセカンド) | 40 (= 40 * 80KB = 3.2MB/秒) | 1 | 4294967039 | N |
NoOfDiskPagesToDiskDuringRestartACC
(減少 MySQL 5.1.6 の場合) | 整数 (8KB ページ数/100 ミリセカンド) | 20 (= 20 * 80KB = 1.6MB/秒) | 1 | 4294967039 | N |
NoOfDiskPagesToDiskDuringRestartTUP
(減少 MySQL 5.1.6 の場合) | 整数 (8KB のページ数/100 ミリセカンド) | 40 (= 40 * 80KB = 3.2MB/秒) | 1 | 4294967039 | N |
DiskCheckpointSpeed
(MySQL 5.1.12 に追加) | 整数 (バイト数/秒) | 10M | 1M | 4294967039 | N |
DiskCheckpointSpeedInRestart
(MySQL 5.1.12 に追加) | 整数 (バイト数/秒) | 100M | 1M | 4294967039 | N |
DiskSyncSize
(MySQL 5.1.12 に追加) | 整数 (バイト数) | 4M | 32K | 4294967039 | N |
NoOfFragmentLogFiles | 整数 | 8 | 1 | 4294967039 | IN |
NoOfReplicas | 整数 | なし | 1 | 4 | IS |
RedoBuffer | バイト | 8M | 1M | 4294967039 | N |
RestartOnErrorInsert
(デバッグ ビルドのみ) | true|false (1|0) | 0 | 0 | 1 | N |
ServerPort
(廃版) | 整数 | 1186 | 0 | 4294967039 | N |
StartFailureTimeout | ミリセカンド | 0 | 0 | 4294967039 | N |
StartPartialTimeout | ミリセカンド | 30000 | 0 | 4294967039 | N |
StartPartitionedTimeout | ミリセカンド | 60000 | 0 | 4294967039 | N |
StopOnError | true|false (1|0) | 1 | 0 | 1 | N |
TimeBetweenGlobalCheckpoints | ミリセカンド | 2000 | 10 | 32000 | N |
TimeBetweenInactiveTransactionAbortCheck | ミリセカンド | 1000 | 1000 | 4294967039 | N |
TimeBetweenLocalCheckpoints | 整数 (ベース 2 対数としての 4 バイトの単語数) | 20 (= 4 * 220 = 4MB
書き込み) | 0 | 31 | N |
TimeBetweenWatchDogCheck | ミリセカンド | 4000 | 70 | 4294967039 | N |
TransactionBufferMemory | バイト | 1M | 1K | 4294967039 | N |
TransactionDeadlockDetectionTimeout | ミリセカンド | 1200 | 50 | 4294967039 | N |
TransactionInactiveTimeout | ミリセカンド | 0 | 0 | 4294967039 | N |
以下のテーブルは MySQL Cluster マネジメント
ノードを設定するためにconfig.ini
ファイルの [NDB_MGMD] あるいは
[MGM]
セクションで使用されるパラメータに関する情報を提供します。これらのパラメータの詳細な説明および補足情報に関しては、項14.4.4.4. 「マネジメント サーバーの定義」
を参照してください。
再起動タイプの カラム値
N:ノードの再起動IN:最初のノードの再起動S:システムの再起動IS:最初のシステムの再起動
これらの略語の説明は 項14.4.5. 「クラスタ設定パラメータの概要」 を参照してください。
| パレメータ名 | タイプ/単位 | デフォルト値 | 最小値 | 最大値 | 再起起動タイプ |
ArbitrationDelay | ミリセカンド | 0 | 0 | 4294967039 | N |
ArbitrationRank | 整数 | 1 | 0 | 2 | N |
DataDir | 文字列 | ./ (ndb_mgmd ディレクトリ) | N/A | N/A | IN |
ExecuteOnComputer | 整数 | ? | ? | ? | ? |
HostName | 文字列 | localhost | N/A | N/A | IN |
Id | 整数 | なし | 1 | 63 | IN |
LogDestination | CONSOLE, SYSLOG、あるいは
FILE | FILE (項14.4.4.4. 「マネジメント サーバーの定義」
参照) | N/A | N/A | N |
以下のテーブルは MySQL Cluster SQL ノードおよび
API ノードを設定する config.ini
ファイルの [SQL] および
[APl]
セクションで使用されるパラメータに関する情報を提供します。これらのパラメータの詳細な説明および補足情報に関しては、項14.4.4.6. 「SQL および他の API ノードの定義」
を参照してください。
再起動タイプの カラム値
N:ノードの再起動IN:最初のノードの再起動S:システムの再起動IS:最初のシステムの再起動
これらの略語の説明は 項14.4.5. 「クラスタ設定パラメータの概要」 を参照してください。
| パラメータ名 | タイプ/単位 | デフォルト値 | 最小値 | 最大値 | 再起動タイプ |
ArbitrationDelay | ミリセカンド | 0 | 0 | 4294967039 | N |
ArbitrationRank | 整数 | 1 | 0 | 2 | N |
BatchByteSize | バイト | 32K | 1K | 1M | N |
BatchSize | 整数 | 64 | 1 | 992 | N |
ExecuteOnComputer | integer | ? | ? | ? | ? |
HostName | 文字列 | localhost | N/A | N/A | IN |
Id | 整数 | なし | 1 | 63 | IN |
MaxScanBatchSize | バイト | 256K | 32K | 16M | N |
MySQL Cluster のローカル
チェックポイントの設定に使用される
Logging
and Checkpointing および
Data
Memory, Index Memory, and String Memory
は分離しては存在しませんが、むしろお互い非常に依存しています。このセクションでは?
DataMemory、IndexMemory、NoOfDiskPagesToDiskAfterRestartTUP、NoOfDiskPagesToDiskAfterRestartACC、および
NoOfFragmentLogFiles ?
を含むこれらのパラメータがどのように実際のクラスタでお互いに関連しているかについて説明します。
重要NoOfDiskPagesToDiskAfterRestartTUP
および NoOfDiskPagesToDiskAfterRestartACC
のパラメータは MySQL 5.1.6
では少なくなっています。MySQL 5.1.6 から 5.1.111
では、LCP
の際のディスクの書き込みは可能な最高速度で行われます。MySQL
5.1.12 からは、LCP
の速度およびスループットはパラメータ
DiskSyncSize、DiskCheckpointSpeed、および
DiskCheckpointSpeedInRestart
を使用して管理しています。項14.4.4.5. 「Defining Data Nodes」
参照。
この例では、弊社のアプリケーションは以下のオペレーションの種類を毎時実行すると想定しています。
50000 選択
15000 挿入
15000 更新
15000 削除
弊社ではまたアプリケーションで使用されるデータについては以下想定しています。
40 カラムを持つ1 つのテーブルを現在開発中です。
各カラムは 32 バイトのデータを保持できます。
アプリケーションによる一般的な
UPDATEの実行では 5 カラムの値に影響します。アプリケーションでは
NULLの値は挿入されません。
よい出発点はローカル チェックポイント (LCP) 間の経過時間を決定することです。システムの再起動時には何の価値もありませんが、REDO ログを実行するためにこのインターバルの 40-60 パーセントを使います。 ? 例えば、LCP 間の時間が 5 分 (300 秒) だとすると、REDO の読み込みに 2 〜 3 分 (120 〜 180 秒) かかります。
ノード毎の最大データ量は
DataMemory
パラメータのサイズによって想定できます。この例では、それは
2 GB
と想定しています。NoOfDiskPagesToDiskAfterRestartTUP
パラメータはユニット時間でのデータがチェックポイントされる量を表します。?
しかし、このパラメータは実際は 100
ミリセカンドでチェックポイントされる 8K
メモリのページ数で表されます。300 秒で 2 GB
がおよそ 1 秒間に 6.8 MB、あるいは 100
ミリセカンドで 700 KB では 100
ミリセカンドでおよそ 85 ページです。
同様に、NoOfDiskPagesToDiskAfterRestartACC
をインデックスに必要なローカルのチェックポイントに時間およびメモリの量で計算できます。?
つまり、IndexMemory
です。インデックスに 512 MB
を用意すると、このパラメータに対しこれはおよそ
100 ミリセカンドで 20 8-KB ページになります。
次に、必要なREDO ログ
ファイル数を決める必要があります。?
つまり、フラグメント ログ ファイル?
相当するパラメータであるNoOfFragmentLogFiles。少なくとも
3 つのローカル
チェックポイントの記録を維持できる十分な
REDO ログ
ファイルがあることを確認する必要があります。生産の設定では、常に不安定要素?
例えばディスクが常に最高速度あるいは最大のスループットで動作するのかわかりません。このため、最悪の状況をを想定しte仕様を強化し、6
つのローカル
チェックポイントをカバーしたレコードを十分に維持できるフラグメント
ログ ファイルを計算します。
ディスクが REDO ログ および UNDO
ログへの書き込みもまた処理していることを忘れないことも大切です。ディスクに書き込まれているデータ量が
NoOfDiskPagesToDiskAfterRestartACC および
NoOfDiskPagesToDiskAfterRestartTUP
の値で決められた量がディスクの利用できる帯域量に近づいたら、ローカル チェックポイント間の時間を長くしたくなるかもしれません。
ローカル ポイント毎に 5 分 (300 秒) とすると、書き込みログ レコードを最大速度 6 * 300 = 1800 秒でサポートする必要があります。REDO ログ レコードのサイズは 72 バイトに更新されカラム値毎に 4 バイト、それに更新されたカラムの最大サイズを加えると、それにトランザクションで更新された各テーブル レコードに 1 つの REDO ログ レコード、データが常駐する各ノードにあります。このセクションで以前設定したオペレーション数を使用すると、以下が得られます。
毎時 50000 選択オペレーションで 0 のログ レコード (よって 0 バイト) ですので、
SELECTステートメントは REDO ログには記録されません。毎時 15000
DELETEステートメントはおよそ 毎秒 5 削除オペレーションです。(見積もりにおいては控えめにしたいので、ここでまとめると、以下の計算になります。)カラムが削除によって更新されませんので、これらのステートメントはオペレーションごとに 5 オペレーション * 72 バイト = 毎秒 360 バイトになります。毎時 15000
UPDATEステートメントはおよそ毎秒 5 回の更新に相当します。各更新に 72 バイト、それにカラム毎に 4バイト * 5 カラムの更新、さらにカラム毎に 32 バイト * 5 カラム? つまりオペレーション毎に 72 + 20 + 160 = 252 バイトになります。これを毎秒 5 オペレーションを乗算すると毎秒 1260 バイトになります。毎秒 15000
INSERTステートメントは毎秒 5 挿入オペレーションに相当します。各挿入は REDO ログ スペース 72 バイトが必要で、それに レコード * 40 カラム毎に 4 バイト、およびカラム * 40 カラム毎に 32 バイトで 72 + 160 + 1280 = 1512 バイト/オペレーションになります。これに 5 オペレーション/秒で 7560 バイト/秒になります。
ですから 1 秒に書き込まれる REDO
ログの合計はおよそ 0 + 360 + 1260 + 7560 = 9180
バイトになります。これを 1800 秒で換算すると
16524000 バイトが REDO
ロギングに必要になります。およそ 15.75
MB です。NoOfFragmentLogFiles
に使用される単位は 4 16-MB ログ ファイル?
つまり、64 MB
になります。このように、パラメータの最小値
(3)
はこの例で示したシナリオに十分で、ですから
64 の 3 倍 = 192 MB、あるいは 12
倍が要求された場合、デフォルトの 8 (あるいは
512 MB)
はこのケースでは必要を満たすに十分です。
変更したテーブルのレコードのコピーは UNDO ログにあります。上記で説明したシナリオでは、UNDO ログはデフォルトの設定で提供された以上のスペースは必要ありません。しかしながら、ディスクのサイズの場合には少なくとも 1 GB 割り当てるのが賢明です。
MySQL Cluster の章のこの部分では MySQL の 1 つのリリースから他の MySQL Cluster へのアップグレードおよびダウングレードについて説明します。ここでは異なるタイプのクラスタのアップグレードを取り上げ、クラスタのアップグレード/ダウングレードの互換性マトリックス (項14.5.2. 「クラスタのアップグレードおよびダウングレードの互換性」 参照) について説明します。
重要MySQL Cluster のアップグレードおよびダウングレードに先立ち、ここではお客様がすでに MySQL Cluster のインストールおよびその設定についてご理解頂いているものとしてここで説明します。項14.4. 「MySQL Cluster の設定」 参照。
このセクションはまだ開発中で、今後アップグレードおよび拡張が行われます。
このセクションでは MySQL Cluster のインストールの ローリング再起動 の実行の仕方について説明します。そのように呼ばれているのはローリング再起動には各ノードを順番に停止および起動(あるいは再起動)するからで、クラスタそのものは常に稼動しています。これは ローリング アップグレード あるいは ローリング ダウングレードの一部としてよく行われ、そこではクラスタの高可用性が必須でクラスタ全体のダウンタイムは許されません。ここでアップグレードについて言及した情報は、一般的にはダウングレードにも同様に適用できます。
ローリング再起動が必要な理由はたくさんあります。
クラスタの設定変更:クラスタの設定を変更するとは、SQL ノードをクラスタに追加したり、設定パラメータを新しい値に変更したりなどあります。
クラスタのソフトウェアのアップグレード/ダウングレード:クラスタを新しいバージョンの MySQL Cluster のソフトウェアにアップグレード (あるいはダウングレード) します。通常これは 「ローリング アップグレード」 (あるいは旧バージョンの MySQL Cluster へ戻す場合は 「ローリング ダウングレード」ting to an older version of MySQL Cluster) と呼ばれています。
ノード ホストの変更:1 つ以上のぅラスタ ノードが稼動しているハードウェアあるいはオペレーティング システムの変更
クラスタの再設定:クラスタが望まない状態に近づいたためにクラスタを再設定します。
リソースの自由化:
INSERTおよびDELETEオペレーションによってテーブルに割り当てられているメモリを他のクラスタ テーブルで使用できるように自由にします。
ローリング再起動のプロセスは以下のように一般化できます。
すべてのクラスタのマネジメント ノード (ndb_mgmd プロセス)を停止し、それらを再設定して再起動します。
停止、再設定、次に各クラスタ ノード (ndbd プロセス) を順番に再起動します。
停止、再設定、次に各クラスタ SQL ノード (mysqld プロセス) を順番に再起動します。
特定のローリング アップグレードを実行する詳細は加える実際の変更によります。ここで詳しいプロセスを説明します。
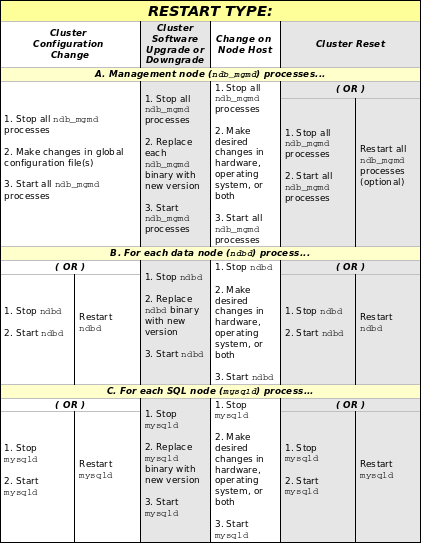
前掲のダイアグラムでは、停止
および 起動
ステップをシェル コマンド (ほとんどの Unix
システムのkill など)
あるいはマネジメント クライアントの
STOP
コマンドを使用して完全に停止して、次に適切な
ndbd あるいは ndb_mgmd
実行ファイルを呼び出してシステムのシェルから再度起動するを説明しました。再起動
はプロセスを ndb_mgm マネジメント
クライアント RESTART
コマンドを使用して再起動することを意味します。
この項ではアップグレードおよびダウングレードを行うための MySQL Serber の異なるバージョン間にクラスタ ソフトウェアおよびテーブル ファイルの互換性に関する情報を提供します。
重要この項では
NDB Cluster に関する MySQL
バージョン間の互換性のみ検討し、他の考慮すべき点にまだあります。他の
MySQL
ソフトウェアのアップグレードあるいはダウングレードと同様に、MySQL
Cluster
のソフトウェアをアップグレードあるいはダウンロードする前に、移行するあるいは移行される
MySQL バージンのMySQL
マニュアルの関連する部分を見直すことを強くお勧めします。.項2.11. 「MySQL のアップグレード」
参照。
以下のテーブルは異なるバージョンの MySQL Server のクラスタのアップグレードおよびダウングレードの互換性を示しています。
注:
4.1 シリーズ:
4.1.8 から 4.1.10 (あるいはそれ以降) に直接アップグレードできません。最初に 4.1.8 をo 4.1.9 に、次に 4.1.10 にアップグレードします。同様に 4.1.10 (あるいはそれ以前) から 4.1.8 にダウングレードできません。最初に 4.1.10 から 4.1.9、次に 4.1.8 にダウングレードします。
MySQL Cluster を 4.1.15 にアップグレードするには、最初に 4.1.14、次に 4.1.15 に、それから 4.1.16 あるいはそれ以降にアップグレードします。
クラスタの 4.1.15 から 4.1.14 (あるいはそれ以前) のダウングレードはサポートされていません。
4.1.8 以前のバージョンへの MySQL Server バージンからのクラスタのアップグレードはサポートされていません。これらからアップグレードするには、すべての
NDBテーブルを一旦ダンプして、新しいバージョンのソフトウェアをインストールして、次にそのダンプからテーブルを再ロードします。。5.0 シリーズ:
このシリーズでは MySQL 5.0.2 が最初の一般へのリリースです。
MySQL 5.0 から MySQL 4.1 へのクラスタのダウングレードはサポートされていません。
5.0.12 から 5.0.11 (あるいは「それ以前への) クラスタのダウンロードはサポートされていません。
ndb_restore を MySQL 5.1 で動作するクラスタのバックアップを使用して MySQL 5.0 Cluster に復旧することはできません。そのような場合には mysqldump を使用する必要があります。
これは MySQL 5.0.23 用には一般にリリースされていません。
5.1 シリーズ:
このシリーズでは MySQL 5.1.3 が最初の一般へのリリースです。
MySQL 5.1.6 あるいはそれ以降をディスク データ テーブルを使用して MySQL 5.1.5 あるいはそれ以前のバージョンにダウングレードするには、すべてのそのようなテーブルを in-memory の Cluster テーブルに最初に変換しない限りダウングレードできません。
MySQL 5.1.8 および MySQL 5.1.10 はリリースされていません。
MySQL 5.1.11 (あるいは以前のバージョン) および 5.1.12 (あるいはそれ以降のバージョン)間でのオンラインでのクラスタのアップグレードおよびダウングレードはクラスタのファイルシステムに大きな変更があるためできません。そのような場合には、バックアップあるいはダンプするか、ソフトウェアをアップグレード(あるいはダウングレード)し、各データ ノードを
--initialで起動し、次にバックアップあるいはダンプから復旧します。これを行うためにNDBバックアップ/復旧あるいは mysqldump を使用できます。
MySQL Cluster の管理を理解するには 4 つの基本的なプロセスに関する知識が必要です。この章の次の数項でクラスタのこれらのプロセスの役割、その使用方法、およびそれらにどのような起動オプションを利用できるかについて説明します。
mysqld は従来の MySQL
サーバーのプロセスです。MySQL Cluster
で使用するには、mysqld は
NDB Cluster ストレージ
エンジンのサポート付きでビルドされる必要があります。それは
http://dev.mysql.com/downloads/
からコンパイルされてバイナリで利用できます。ソースから
MySQL を構築する場合、configure を
--with-ndbcluster
オプションと一緒に起動し NDB
Cluster ストレージ
エンジンをサポートします。
mysqld バイナリが Cluster
サポートするように構築されている場合、NDB
Cluster ストレージ
エンジンはデフォルトはまだ無効です。このエンジンを有効にするために可能なオプションの
2 つのどちらかを使用できます。
--ndbclusterをコマンドラインの起動オプションとして使用 mysqld を起動します。my.cnfファイルの[mysqld]セクションのndbcclusterを含む行を挿入します。
お客さまのサーバーが NDB Cluster
ストレージ
エンジンが有効で稼動していることを検証するには
SHOW ENGINES ステートメントを MySQL
Monitor (mysql)
で発行します。YES が
Support 値として
NDBCLUSTER
の行に表示されます。この行で NO
が表示された場合あるいはそのような行が出力に表示されなかった場合、NDB-が有効なバージョンの
MySQL
が動作していないことになります。この行に
DISABLED
が表示された場合、それを今説明した 2
つの方法のいずれかで有効にする必要があります。
クラスタお設定ファイルを読み込むには、MySQL サーバーは少なくとも 3 件の情報が必要です。
MySQL サーバー自身のクラスタ ノード ID
マネジメント サーバー (MGM ノード) のホスト名あるいは IP アドレス
マネジメント サーバーに接続する TCP/IP のポート番号
ノード ID はダイナミックに割り当てられますので、それらを明示的に指定することは必ずしも必要ありません。
mysqld パラメータ
ndb-connectstring
はコマンドラインでmysqld
を起動するときにあるいはmy.cnf
で接続文字列の指定に使用されます。接続文字列はホスト名あるいはマネジメント
サーバーがある IP およびそれが使用する TCP/IP
ポートを含みます。
以下の例では、ndb_mgmd.mysql.com
はマネジメント
サーバーが常駐するホストで、マネジメント
サーバーはポート 1186 のクラスタ
メッセージを受信します。
shell> mysqld --ndb-connectstring=ndb_mgmd.mysql.com:1186
接続文字列に関する情報は
項14.4.4.2. 「クラスタの 接続文字列」
を参照してください。
この情報を与えられると、MySQL サーバーはクラスタの完全な参加者になります。(このように実行されている mysqld プロセスを SQL ノードとも言います。)それは完全にクラスタ ノードおよびその状態を認識しており、すべてのデータ ノードに接続を確立します。このように、データ ノードをトランザクション コーオーディネータとして使用してデータを読みデータ ノードを更新します。
mysql クライアントで MySQL
サーバーがクラスタに SHOW
PROCESSLIST
を使用して接続されているかどうか表示することができます。MySQL
サーバーがクラスタに接続されていると、お客様にはPROCESS
権限がありますので、出力の最初の行はここに表示されているようになります。
mysql> SHOW PROCESSLIST \G
*************************** 1. row ***************************
Id: 1
User: system user
Host:
db:
Command: Daemon
Time: 1
State: Waiting for event from ndbcluster
Info: NULL
ndbd は NDB Cluster ストレージ エンジンを使用してテーブルのすべてのデータの処理に使用されるプロセスです。これは配布されたトランザクションの処理、ノードのリカバリ、オンラインバックアップ、および関連のタスクを実行するためのデータ ノードに権限を与えるプロセスです。
MySQL Cluster では、一連の ndbd プロセスがデータの処理に協力します。これらのプロセスは同じコンピュータ上あるいは異なるコンピュータ上で実行できます。データ ノードと Cluster ホストとの通信は完全に設定できます。
ndbd generates
はconfig.ini
設定ファイルのDataDir
で指定されたディレクトリにある一連のログ
ファイルを生成します。これらのログ
ファイルを以下に示します。node_id
はノードの一意の識別子を表します。例えば、ndb_2_error.log
はノード ID が 2 のデータ
ノードから生成されたエラーログです。
ndb_は参照された ndbd プロセスが遭遇したすべてのクラッシュのレコードを含むライルです。このファイルの各レコードは簡単なエラー文字列でこのクラッシュのトレースファイルの参照です。このファイルへの一般的なエントリは以下のようになります。node_id_error.logDate/Time: Saturday 30 July 2004 - 00:20:01 Type of error: error Message: Internal program error (failed ndbrequire) Fault ID: 2341 Problem data: DbtupFixAlloc.cpp Object of reference: DBTUP (Line: 173) ProgramName: NDB Kernel ProcessID: 14909 TraceFile: ndb_2_trace.log.2 ***EOM***
注:エラーログの最後のエントリは必ずしも最新のものでない (そうも思われない) ことを忘れずの憶えておいてください。エラーログのエントリは年代順の入力では ありません。むしろ、
ndb_ファイル (以下参照) で決められたようにトレース ファイルの順序に基づいています。エラーログのエントリはこのように周期的に上書きされシーケンシャルではありません。node_id_trace.log.nextndb_はエラーが発生する直ぐ前に起こったことを正確に記述したものです。この情報は MySQL Cluster の開発チームの分析に役にたちます。node_id_trace.log.trace_id多くのこれらのトレース ファイルを古いファイルが上書きされる前に統合することができます。
trace_idは各継続的なトレース ライルを増分した番号です。ndb_は割り当てられる次のトレースファイル番号を追跡したファイルです。node_id_trace.log.nextndb_は ndbd プロセスによるデータ出力を含むファイルです。このファイルは ndbd が daemon として実行されたときのみ作成されます。それはデフォルトの振る舞いです。node_id_out.logndb_は daemon として実行されたときの ndbd プロセスのプロセス ID を含みます。それはまたノードが同じ識別子で起動されるのを避けるためにロック ファイルとして機能します。node_id.pidndb_は ndbd のデバッグ バージョンでのみ使用されるファイルで、すべての受信、送信、およびそのデータをndbd プロセスに持つ内部メッセージをトレースできます。node_id_signal.log
NSF
で搭載したディレクトリを使用しないようお勧めします。なぜなら、環境によってはこのディレクトリが問題を起こし、.pid
ファイルのロックがプロセスが終了しても有効である場合があります。
ndbd を実行するには、マネジメント サーバーのホスト名および接続しているポートを指定する必要があります。オプションで、プロセスが使用するノード ID を指定することもできます。
shell> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"
この件に関する詳細は
項14.4.4.2. 「クラスタの 接続文字列」
を参照してください。項14.6.5. 「MySQL Cluster プロセスのコマンド オプション」
は ndbd
の他のオプションについて説明します。
ndbd が実行されると、それは実際に 2 つのプロセスを始めます。これらのプロセスの最初は 「angel process」 と呼ばれています。その唯一の仕事は実行プロセスがいつ完了したかを突き止めることで、次に ndbd プロセスをそれが統合されている場合に実行します。このように、 ndbd を Unix kill コマンドで無効にする場合、エンジェル プロセスで初めて両方のプロセスを無効にする必要があります。ndbd プロセスを終了させる好ましい方法としてはマネジメント クライアントを使用してそのプロセスをそこで止めることです。
実行プロセスは他の操作同様、読み込み、書き込み、およびデータのスキャンにスレッドを 1 つ使用しています。このスレッドは数千もの同時発生的な操作を容易に処理するために同期的に導入されます。さらに、監視スレッドはそれがエンドレスのループでフリーズしないよう確認するための実行スレッドを管理します。スレッドのループはファイル I/O を取扱い、各スレッドは 1 つのオープン ファイルをそれぞれ扱います。スレッドは ndbd プロセスのトランスポーターによるトランスポーター接続に使用されます。多数のオペレーション(更新を含む)を実行するマルチ プロセッサ システムの場合、ndbd プロセスはそれが可能な場合には 2 つまでの CPU を使用できます。
多くの CPU を使用しているマシンの場合、異なるノード グループに属すいくつかの ndbd プロセスを使用できます。しかし、そのような設定はそれでも実験的なものであり、生産環境では MySQL 5.1 サポートしていません。項14.13. 「MySQL Cluster の既知の制限」 参照。
マネジメント サーバーはクラスタの設定ファイルを読み込みこの情報をそれを要求したクラスタのすべてのノードに配布するプロセスです。それはまたクラスタの活動に関するログを維持します。マネジメント クライアントはマネジメント サーバーに接続してクラスタの状況をチェックします。
マネジメント サーバーを起動するときには接続文字列を指定することは厳密には必要ありません。しかし、1 つ以上のマネジメント サーバーを使用している場合には、接続文字列を提供しクラスタの各ノードはそのノード ID を明示的に指定する必要があります。
接続の字列の使用に関する情報は
項14.4.4.2. 「クラスタの 接続文字列」
を参照してください。項14.6.5. 「MySQL Cluster プロセスのコマンド オプション」
は、ndb_mgmd
の他のオプションについて説明しています。
以下のファイルはその起動ディレクトリにある
ndb_mgmd
によって作成あるいは使用され、cofig.ini
で指定されたように DataDir
に配置されます。その後のリストでは、node_id
は一意のノード識別子です。
config.iniは全体としてはクラスタの設定ファイルです。このファイルはユーザーが作成しマネジメントサーバーが読み込みます。項14.4. 「MySQL Cluster の設定」、はファイルの設定について説明します。ndb_はクラスタのイベント ログ ファイルです。それらのイベントの例としてチェックポイントの起動および完了、ノードの起動イベント、ノードの失敗、およびメモリ使用のレベルを含みます。完全なクラスタ イベントのリストおよびその説明は 項14.7. 「MySQL Cluster の管理」 にあります。node_id_cluster.logクラスタのログ サイズが 100 万バイトになると、そのファイルは
ndb_に名前が変わります。そこではnode_id_cluster.log.seq_idseq_idはクラスタのログ ファイルのシーケンス番号です。(例:シーケンス番号の 1、2、3 の番号の付いたファイルが既に存在する場合には、次のログ ファイルは4の番号の付いた名前になります。)ndb_はnode_id_out.logstdoutおよびstderrに使用されるファイルでマネジメント サーバーが daemon として稼動しているときに使用されます。ndb_はマネジメント サーバーを daemon として使用稼動しているときに使用されるプロセス ID です。node_id.pid
マネジメント クライアントのプロセスは実際はクラスタを稼動させるには必要ありません。その値はクラスタの状態、バックアップの開始、および他の管理機能をチェックするために一連のコマンドを提供します。マネジメント クライアントは C API を使用してマネジメント サーバーにアクセスします。高度なユーザーは専用のマネジメント プロセスをプログラムするためにこの APl を使用し ndb_mgm がの実行に類似したタスクを実行できます。
マネジメント クライアントを起動するには、マネジメント サーバーのホスト名とポート番号を提供する必要があります。
shell> ndb_mgm [host_name [port_num]]
例:
shell> ndb_mgm ndb_mgmd.mysql.com 1186
デフォルトのホスト名とポート番号はそれぞれ
localhost および 1186 です。
ndb_mgm の使用に関する詳細は 項14.6.5.4. 「ndb_mgm のコマンド オプション」、および 項14.7.2. 「マネジメント クライアントのコマンド」 にあります。
MySQL Cluster のすべての実行ファイル
(mysqld を除く)
はこの項で説明したオプションを使用します。MySQL
Cluster
バージョンのユーザーはこれらのオプションの中にはmysqld
同様お互いの一貫性を保つために変更されている場合がありますのでご承知ください。MySQL
Cluster の実行ファイルと一緒に
--help
オプションを使用しそれがサポートするオプションのリストを表示できます。
以下のオプションはすべての MySQL Cluster 実行ファイルに共通です。
--help--usage,-?利用できるコマンド オプションのリストをその説明書と一緒に印刷します。
--connect-string=,connect_string-cconnect_stringconnect_stringは接続文字列をマネジメント サーバーにコマンドオプションとして設定します。shell>
ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"--debug[=options]このオプションはデバッグを有効にしてコンパイルしたバージョンにのみ使用できます。それは mysqld プロセスと同様にデバッグの呼び出しからの出力を可能にするために使用されます。
--execute=,command-ecommandはシステム シェルからコマンドをクラスタの実行ファイルに送るために使用されます。例えば、以下のいずれかになります。
shell>
ndb_mgm -e "SHOW"あるいは
shell>
ndb_mgm --execute="SHOW"は以下に等価
ndb_mgm>
SHOWこれは
--executeあるいは-eオプションが mysql コマンドラインのクライアントとの機能の仕方に類似しています。項3.3.1. 「コマンドラインにおけるオプションの使用」 参照。--version,-V実行ファイルの MySQL Cluster バージョン番号を印刷します。バージョン番号すべてのバージョンが一緒に使用されるとはかぎらなので関連性があります。MySQL Cluster の起動プロセスでは使用されているバイナリのバージョンが同じクラスタの共存できるか検証します。これは MySQL のソフトウェアのアップグレードあるいはダウングレードをオンライン (ローリング) で行う場合にも重要です。(項14.5.1. 「クラスタのローリング再起動の実行」 参照。)
次の数項ではここの NDB
プログラムに特定のオプションについて説明します。
--ndb-connectstring=connect_stringNDB Clusterストレージ オプションを使用する際、このオプションはクラスタの設定データを配布するマネジメント サーバーを指定します。--ndbclusterMySQL を使用するには
NDB Clusterストレージ エンジンが必要です。mysqld バイナリがNDB Clusterストレージ エンジンのサポートを含む場合、このエンジンはデフォルトで無効になります。有効にするには--ndbclusterオプションを使用します。そのエンジンを明示的に無効にするには--skip-ndbclusterを使用します。
すべてのNDB
プログラムに共通のオプションに関しては、項14.6.5. 「MySQL Cluster プロセスのコマンド オプション」
を参照してください。
--bind-addressndbd を特定のネットワーク インターフェースに結合します。このオプションにはデフォルトの値はありません。
このオプションは MySQL 5.1.12 に追加されています。
--daemon,-dndbd に daemon プロセスの実行を指示します。これはデフォルトの振る舞いです。
--nodaemonはプロセスが daemon として実行されないようにします。--initialndbd に初期の実行を指示します。初期の実行により以前の ndbd のインスタンスでリカバリ目的に作成されたファイルを消去します。またリカバリ ログ ファイルを再度作成します。使用しているオペレーティング システムによってはこのプロセスにはかなり長い時間がかかります。
--initialの実行はそれを実行することによって Cluster のファイルシステムのすべてのファイルを削除し、新たにすべての REDO ファイルを作成するため ndbd プロセスが実行される一番最初にのみ使用されます。この規則に対する例外は:ファイルのコンテンツを変更したソフトウェアのアップグレードを行うとき。
ノードを ndbd の新しいバージョンで再起動するとき。
何かの理由でノードあるいはシステムの再起動が繰り返し失敗したときの最後のレポートの方法として。この場合、データ ファイルの破壊によりこのノードはデータの復旧にその後使用できなくなることに注意してください。
このオプションは以下のいずれにも影響は及ぼしません。
影響されたノードにより既に作成されたバックアップ ファイル
Cluster ディスク データ ファイル (項14.11. 「MySQL Cluster ディスク データ ストレージ」 参照)。
そのデータ ノード ? で作成されたバックアップを維持し ndbd を
--initialオプションを使用せずに実行するには、DataDirのBACKUPの可能な例外によってデータ ノードDataDirのすべてのファイルおよびディレクトリを別の方法 (rm -r -f などを使用して) によって削除することで同じ効果を得ることができます。これは Cluster の管理タスクを記述する際に役に立ちます。--initial-startこのオプションはクラスタを部分的に初期起動する際に使用します。各ノードおよび
--no-wait-nodesはこのオプションで起動します。例えば、データ ノードの ID が 2、3、4、および 5 を持つ 4-ノード クラスタを持っているとします。それをノードの 2、4、および 5 のみを使用して部分的な初期の起動をする場合。? つまりノード 3 を除く:
ndbd --ndbd-nodeid=2 --no-wait-nodes=3 --initial-start ndbd --ndbd-nodeid=4 --no-wait-nodes=3 --initial-start ndbd --ndbd-nodeid=5 --no-wait-nodes=3 --initial-start
このオプションは MySQL 5.1.9 に追加されています。
--nowait-nodes=node_id_1[,node_id_2[, ...]]このオプションはクラスタが起動前に待たないデータ ノードのリストを扱っています。
これをクラスタが分割した状態での起動に使用できます。例えば、クラスタを 4-ノード クラスタを稼動しているデータ ノードの半分だけ (ノード 2、3、4、および 5) で起動するには、かく ndbd プロセスを
--nowait-nodes=3,5で実行します。この場合、クラスタはノード 2 および 4 が接続すると直ぐ起動し、ノード 3 および 5 が接続するまでStartPatitionedTimeoutミリセカンドをまちません 。前の例の同じクラスタを 1 つの ndbd ? 無しで起動したい場合、例えば、ノード 3 のホスト マシンのハードウェアに問題があり ? ノード 2、4、および 5 を
--no-wait-nodes=3で起動する場合。次にクラスタが直ぐにノード 2、4、および 5 を接続しノード 3 の起動を待たない場合。このオプションは MySQL 5.1.9 に追加されています。
--nodaemonndbd に daemon プロセスとして実行しないよう指示を出します。これは ndbd がデバッグされて出力を画面に向ける場合に有効です。
--nostart,-nndbd に自動的に実行しないよう指示をだします。このオプションを使用すると、ndbd がマネジメント サーバーに接続して、マネジメント サーバーから設定データを取得し、通信オブジェクトを初期化します。しかし、それはマネジメント サーバーによって特にそうするように要求されるまで実行エンジンを起動しません。これはマネジメント クライアントで適切な
STARTコマンドを出すと実行されます (項14.7.2. 「マネジメント クライアントのコマンド」 参照)。
NDB プログラムに共通のオプションについては、項14.6.5. 「MySQL Cluster プロセスのコマンド オプション」 を参照してください。
--config-file=,filename-ffilenameマネジメント サーバーにその設定ファイルにどのファイルを使用するかを指示します。このオプションは指定する必要があります。そのファイル名は
config.iniに既定です。注:このオプションには
-cを付けることもできますが、このショートカットは既に陳腐なため新しいインストールでは使用していません。file_name--daemon,-dndb_mgmd に daemon プロセスを実行する指示を出します。これはデフォルトの操作です。
--nodaemonndb_mgmd に daemon daemon として開始しないように指示します。
NDB プログラムに共通のオプションについては、項14.6.5. 「MySQL Cluster プロセスのコマンド オプション」 を参照してください。
--try-reconnect=numberマネジメント サーバーへの接続が切断された場合、ノードは接続できるまで 5 秒ごとに接続を試みます。このオプションを使用して、再接続の回数を
numberに制限して再接続を止めエラーとして報告することもできます。
MySQL Cluster の管理には様々なタスクを含み、その最初は設定および MySQL Cluster の起動です。これは 項14.4. 「MySQL Cluster の設定」、および 項14.6. 「MySQL Cluster のプロセス管理」 で説明しています。
以下の項では MySQL Cluster の運用管理について説明します。
MySQL Cluster の運用管理には基本的に 2
つの手法がありあます。これらの最初はマネジメント
クライアントの入力したコマンドの使用でそこではクラスタの状態をチェックし、ログ
レベルを変更し、バックアップを開始して停止し、ノードを停止して起動します。2
番目の手法はクラスタ ログ
ndb_
のコンテンツを調べることを含みます。これは通常マネジメント
サーバーの node_id_cluster.logDataDir
ディレクトリにありますが、このロケーションは
LogDestination
オプションで無効になります。? 詳細は
項14.4.4.4. 「マネジメント サーバーの定義」
を参照してください。(node_id
がその活動がログされるノードの一意の識別子を表すことを思い出してください。)クラスタ
ログは ndbd で生成されたイベント
レポートを含みます。クラスタ
ログのエントリを Unix システム
ログに送ることもできます。
この項ではクラスタが起動したときのステップを説明します。
以下に示すようにいくつかの異なる起動タイプおよびモードがあります。
最初の起動:クラスタはすべてのデータ ノードの未使用のファイルシステムで起動します。これはクラスタがまさに一番最初の起動時に発生する、あるいは
--initialオプションで再起動したときに発生します。注:ディスク データ ファイルはノードを
--initialで再起動したときには削除されません。システムの再起動:クラスタが起動しデータ ノードに保存されたデータを読み込みます。これはクラスタが使用された後にシャットダウンされ場合、クラスタが離れたところからオペレーションを再開する再に発生します。
ノードの再起動:これはクラスタそのものが稼動しているときのクラスタ ノードのオンラインの再起動です。
最初のノードの再起動:これはノード再初期化され未使用のファイルシステム起動されたときを除いて、ノードの再起動と同じです。
起動に先立ち、すべてのデータ ノード
(ndbd プロセス)
は初期化する必要があります。初期化には以下のステップが含まれます。
ノード ID の取得。
設定データの取り出し。
インターノード通信のポートの割り当て。
設定ファイルから取得した設定に基づいたメモリの割り当て。
データ ノードあるいは SQL ノードが最初にマネジメント ノードに接続すると、クラスタ ノード ID を予約します。他のノードが同じノード ID を割り当てていないか確認するために、この ID はノードがクラスタおよびノードが接続された少なくとも 1 つの ndbd レポートに接続されるまで維持されます。このノード ID の維持は問題のノードおよび ndb_mgmd 間の接続によって保護されます。
通常、ノードに問題が発生した場合、ノードの接続がマネジメント サーバーから切断され、その接続に使用されているソケットが閉じて、予約されたノード ID の予約が開放されます。しかし、ノードの接続が突然切断された場合? 例えば、クラスタのホストの 1 つのハードウェアの問題、あるいはネットワークの問題で切断されると、? オペレーティング システムによるソケットの通常の閉鎖が行われなくなります。この場合、そのノード ID は予約されたままで、TCP のタイムアウトが 10 分あるいはそれ以降には起こるまで開放されません。
この問題を対処するために PURGE STALE
SESSIONS
を使用できます。このステートメントを実行するとすべての予約したノード
ID
をチェックします。そして、実際に接続されていてノードによって使用されていないノード
ID の予約が外されます。
MySQL 5.1.11 以降では、ノード ID
の割り当てのタイムアウトの処理が導入されています。これによりおよそ
20 秒後に ID
利用を自動的にチェックするため、PURGE
STALE SESSIONS
は通常のクラスタの起動においては必要なくなります。
各ノードが初期化された後、クラスタの起動プロセスが開始されます。クラスタがこのプロセスで行うステージを以下に示します。
ステージ 0
クラスタのファイルシステムをクリアします。このステージはクラスタが
--initialオプションで起動されたとき のみ 発生します。ステージ 1
このステージはクラスタの接続を設定し、インターノード通信を確立し、クラスタのハートビートを始動します。
注:残りのノードがフェーズ 2 でハングしている時にフェーズ 1 で 1 つ以上のノードがハングした場合は、ネットワークの問題が考えられます。そのような問題で考えられる原因の 1 つは 1 つ以上のホストが複数のネットワークのインターフェースを持っている場合です。この条件の別の共通の問題点はクラスタ ノードの通信に必要な TCP/IP ポートのブロックです。後者のケースでは、ファイアウォールの設定の仕方に問題がある場合がよくあります。
ステージ 2
アービトレータ ノードが選択されます。これがシステムの再起動の場合、クラスタは最新の保存できるグルーバル チェックポイントを決定します。
ステージ 3
このステージでは多くのクラスタの変数を初期化します。
ステージ 4
最初の起動あるいは最初のノードに起動に対し、やり直し(redo) ログファイルが作成されます。これらのファイル数は
NoOfFragmentLogFilesと同じです。システムの再起動:
スキーマを読んでください。
ローカルのチェックポイントからデータ読み込みログを元に戻し ( undo) ます。
最新の保存できるグルーバル チェックポイントになるまでやり直し (redo) 情報を適用します。
ノードの再起動には、やり直し (redo) ログの最後を探します。
ステージ 5
これが最初の起動の場合、
SYSTAB_0およびNDB$EVENTS内部システム テーブルを作成します。ノードの再起動あるいは最初のノードの再起動:
このノードはトランザクションの取扱い操作に含まれています。
ノード スキーマはそのマスタに比較されそれと同期します。
INSERTフォームでこのノード グループの他のデータ ノードから受信した同期データすべてのケースにおいて、アービトレーターによって決められたローカル チェックポイントの完了を待ちます。
ステージ 6
内部変数を更新します。
ステージ 7
内部変数を更新します。
ステージ 8
システムの再起動で、すべてのインデックスを再構築します。
ステージ 9
内部変数を更新します。
ステージ 10
この段階でノードの再起動あるいは最初のノードに再起動で、API がノードに接続してイベントを受け取ります。
ステージ 11
この段階でノードの再起動あるいは最初の再起動で、イベントの配布はクラスタを結合するノードに渡されます。新たに結合されたノードはそのプライマリのデータをサブスクラーバーに届ける責任を負います。
最初の起動およびシステムの再起動のこのプロセスが完了すると、トランザクションの取扱いが有効になります。ノードの再起動あるいは最初のノードの再起動で、起動プロセスの完了はノードがトランザクションのコーオーデネーターとしての役割を始めたことを意味します。
クライアントの設定に加えて、クラスタがマネジメント クライアント ndb_mgm で利用できるコマンドライン インターフェースを通じて操作されます。これは稼動中のクラスタのプライマリの管理インターフェースです。
イベント ログのコマンドは 項14.7.3. 「MySQL Cluster で生成されたイベント レポート」 にあります。バックアップの作成およびバックアップからの保存は 項14.8. 「MySQL Cluster のオンライン バックアップ」 で提供しています。
マネジメント
クライアントには以下の基本的なコマンドがあります。その後のリストでは、
node_id
はデータベースのノード ID あるいはキーワード
ALL
を表し、それによってコマンドはすべてのクラスタのデータ
ノードに適用されます。
HELPすべての利用可能なコマンドに関する情報を表示します。
SHOWクラスタの状態に関する情報を表示します。
注:複数のマネジメント ノードを使用しているクラスタでは、このコマンドは実際に現在のマネジメント サーバーに接続されているデータノードだけに関する情報を表示します。
node_idSTARTnode_id(あるいはすべてのデータ ノード) 認識された データ ノードをオンラインにします。ALL STARTはすべてのデータ ノードでのみ機能し、マネジメント サーバーのノードには作用しません。重要このコマンドを使用してデータ ノードをオンラインにするには、データ ノードは ndbd --nostart あるいは ndbd -n を使用して起動していることが必要です。
node_idSTOPnode_idで認識されたデータあるいはマネジメント ノードを起動します。ALL STOPはすべてのデータ ノードのみを起動し、マネジメント ノードは起動しません。A node affected by this command disconnects from the cluster, and its associated ndbd or ndb_mgmd process terminates.
node_idRESTART [-n] [-i]node_id(あるいはすべてのノード) で認識されたデータ ノードを再起動します。-iオプションをRESTARTで使用するとデータ ノードが最初の再起動を実行します。つまり、ノードのファイルシステムが削除されて再度作成されます。その結果はデータ ノードの停止で得た結果と同じで、その後システム シェルの ndbd --initial を使用して再度起動します。このオプションを使用してもバックアップ ファイルとディスク データ ファイルは削除されません。-nオプションを使用するとデータ ノードのプロセスが再度実行されますが、データ ノードは実際には適切なSTARTコマンドが実行されるまでオンラインにはなりません。その結果はデータ ノードの停止で得た結果と同じで、その後システム シェルのndbd --nostartあるいはndbd -nを使用して再起動します。node_idSTATUSnode_id(あるいはすべてのデータ ノードの) で認識されたデータ ノードの状態に関する情報を表示します。ENTER SINGLE USER MODEnode_id単一のユーザーモードを入力します、そこではノード ID
node_idで認識された MySQL サーバーのみがデータベースにアクセスできます。MySQL 5.1 では単一のユーザーモードで稼動している場合はデータ ノードはクラスタに結合できません。(詳細は Bug#20395 を参照してください。)
EXIT SINGLE USER MODE単一ユーザーモードを終了するには、すべての SQL ノード (つまり、mysqld プロセスを実行している) をデータベースにアクセスさせます。
QUIT、EXITマネジメント クライアントを終了します。
このコマンドはクラスタに接続しているどのノードにも影響を与えません。
SHUTDOWNすべてのクラスタ データ ノードおよびマネジメント ノードをシャットダウンします。この操作を行った後にマネジメント サーバーを終了するには、
EXITあるいはQUITを使用します。このコマンドはクラスタに接続してるどの SQL ノードあるいは API ノードもシャットダウンしません。
この項では、MySQL Cluster により提供されたイベント ログのタイプおよびログされたイベントのタイプについて説明します。
MySQL Cluster は 2 種類のイベント ログを提供します。
クラスタ ログ、、 はすべてのぅラスタ ノードが生成したイベントを含みます。クラスタ ログは単一のロケーションでのクラスタ全体のログ情報を提供するにでほとんどのケースに使用に推薦しているログです。
デフォルトでは、クラスタ ログはndb_bgm バイナリが常駐する同じディレクトリでファイル名
ndb_で保存されます。 (そこではnode_id_cluster.lognode_idはマネジメント サーバーのノード ID です)。クラスタのログ情報をファイルに追加あるいはファイルに保存される代わりに、
DataDirおよびLogDestination設定パラメータに設定された値によって決められたようにstdoutあるいはsyslogに送られます。これらのパラメータに関する情報は、項14.4.4.4. 「マネジメント サーバーの定義」 を参照してください。ノード ログ は各ノードに対してローカルです。
ノードのイベント ログにより生成された出力はノードの
DataDirのファイルndb_(そこではnode_id_out.lognode_idはノードのノード ID です) に書き込まれます。ノードのイベント ログはマネジメント ノードおよびデータ ノードの両方に生成されます。ノード ログはアプリケーションの開発時、あるいはアプリケーション コードのデバッグ時のみ使用されるように意図されたものです。
両方のログ タイプはイベントの異なるサブセットのログに設定できます。
各レポートされるイベントは 3 つの異なる基準で分類されます。
Category:これは以下の値のいずれかになります。
STARTUP、SHUTDOWN、STATISTICS、CHECKPOINT、NODERESTART、CONNECTION、ERROR、あるいはINFO。Priority:これは 1 〜 15 の番号で表示され、1 は「最も重要」で 15 は「それほど重要でない」ことを意味します。
深刻度:これは以下の値のいずれかになります。
ALERT、CRITICAL、ERROR、WARNING、INFO、あるいはDEBUG。
クラスタ ログおよびノード ログはどちらもこれらのプロパティでフィルタできます。
クラスタ ログで使用されているフォーマットを以下示します。
2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Data usage is 2%(60 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Index usage is 1%(24 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Data usage is 2%(76 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Index usage is 1%(24 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Data usage is 2%(58 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Index usage is 1%(25 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Data usage is 2%(74 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Index usage is 1%(25 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 4: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 1: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 1: Node 9: API version 5.1.15 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 2: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 2: Node 9: API version 5.1.15 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 3: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 3: Node 9: API version 5.1.15 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 4: Node 9: API version 5.1.15 2007-01-26 19:59:22 [MgmSrvr] ALERT -- Node 2: Node 7 Disconnected 2007-01-26 19:59:22 [MgmSrvr] ALERT -- Node 2: Node 7 Disconnected
クラスタ ログの各行には以下の情報が含まれます。
タイムスタンプ
YYYY-MM-DDHH:MM:SSログを実行しているノード タイプクラスタ ログでは、これは常に
[MgmSrvr]です。イベントの深刻度です。
イベントをレポートするノード ID です。
イベントの説明です。ログの表示されれ最も一般的なイベントのタイプfはチェックポイントが発生したときのクラスタの異なるノード間の接続と切断です。ケースによっては、その記述の中に状況の情報が含まれます。
以下のマネジメント コマンドはクラスタ のログに関するものです。
CLUSTERLOG ONクラスタのログをオンにします。
CLUSTERLOG OFFクラスタのログをオフにします。
CLUSTERLOG INFOクラスタのログ設定に関する情報を提供します。
node_idCLUSTERLOGcategory=thresholdログの
categoryイベントでクラスタ ログのthreshold以下あるいは同等のイベントです。CLUSTERLOG FILTERseverity_levelseverity_levelで指定されたイベントのクラスタ ログを切り換えます。
以下のテーブルはクラスタ ログのカテゴリの閾値のデフォルトの設定 (すべてのデータ ノードの)を示しています。イベントが優先度の閾値より低いかあるいは同じ場合値を持つ場合、それはクラスタ ログにレポートされます。
イベントはデータ ノード毎にレポートされ、閾値は異なるノードの異なる値で設定できます。
| カテゴリ | デフォルトの閾値(すべてのデータ ノード) |
STARTUP | 7 |
SHUTDOWN | 7 |
STATISTICS | 7 |
CHECKPOINT | 7 |
NODERESTART | 7 |
CONNECTION | 7 |
ERROR | 15 |
INFO | 7 |
STATISTICS
カテゴリには非常に多くの役に立つデータがあります。詳細については、項14.7.3.3. 「CLUSTERLOG STATISTICSの活用」
をご参照してください。
閾値は各カテゴリ内のイベントをフィルタできます。例えば、重要度
3 の STARTUP イベントは
STARTUP の閾値が 3
あるいはそれ以下の変更されないとログされません。重要度が
3 あるいはそれ以下のイベントが閾値が 3
の場合送られます。
以下のテーブルではイベントの深刻度を表示します。(注:これらは
LOG_EMERG
およびLOG_NOTICE、それは使用されたりマップされない)
を除く Unix の syslog
レベルに一致します。
| 1 | ALERT | 破損したシステムのデータベースなどのように至急修正ガ必要な条件 |
| 2 | CRITICAL | デバイスのエラーあるいは不十分なリソースなどのクリティカルが条件 |
| 3 | ERROR | 設定エラーなど修正を必要な条件 |
| 4 | WARNING | エラーではないが、特別な扱いが必要な条件 |
| 5 | INFO | 情報に関するメッセージ |
| 6 | DEBUG | NDB Cluster の開発に使用されるデバッグ
メッセージ |
イベントの深刻度レベルはオン/オフにできます。(上記
CLUSTERLOG FILTER ?
参照)。深刻度レベルをオンにすると、深刻度がカテゴリの閾値より低いあるいは同じすべてのイベントがログされます。深刻度レベルをオフにするとその深刻度レベルに属すイベントはルグされません。
イベント ログでレポートされたイベント レポートのフォーマットは以下のようになります。
datetime[string]severity--message
例:
09:19:30 2005-07-24 [NDB] INFO -- Node 4 Start phase 4 completed
この項では各カテゴリのカテゴリおよび深刻度レベルで規定されたレポートが必要なイベントのすべてについて説明します。
イベントの説明での、GCP および LCP はそれぞれ 「グルーバル チェックポイント」 および 「ローカル チェックポイント」 を意味します。
CONNECTION
イベント
これらのイベントはクラスタ間の接続に関連しています。
| イベント | 優先度 | 深刻度レベル | 説明 |
| データ ノード接続済み | 8 | INFO | データ ノード接続済み |
| データ ノード接続済み | 8 | INFO | データ ノード接続済み |
| 通信閉鎖 | 8 | INFO | SQL ノードあるいはデータ ノード接続切断 |
| 通信再開 | 8 | INFO | SQL ノードあるいはデータ ノード接続の再開 |
CHECKPOINT
イベント
ここに示したログ メッセージはチェックポイントに関するものです。
| イベント | 優先度 | 深刻度レベル | 説明 |
| 計算が GCI を維持中の LCP の停止 | 0 | ALERT | LCP 停止 |
| ローカル チェックポイントの断片化完了 | 11 | INFO | 断片の LCP 完了 |
| グルーバル チェックポイント完了 | 10 | INFO | GCP 終了 |
| グローバル チェックポイントの開始 | 9 | INFO | GCP の開始:REDO ログのディスクへの書き込み |
| ローカル チェックポイントの完了 | 8 | INFO | LCP 通常に完了 |
| ローカル チェックポイントの開始 | 7 | INFO | LCP の開始:データのディスクへの書き込み |
| undo ログのレポートのブロック | 7 | INFO | UNDO ログのブロック; バッファのオーバーフロー |
STARTUP
イベント
以下のイベントがノードあるいはクラスタの起動、またはその成功不成功により生成されます。それらによってログの活動を含む起動プロセスの進展に関連する情報も提供されます。
| イベント | 優先度 | 深刻度レベル | 説明 |
| 内部の開始信号受信 STTORRY | 15 | INFO | 再起動完了後にブロックを受信 |
| Undo レコード実行 | 15 | INFO | ? |
| 新しい REDO ログ開始 | 10 | INFO | GCI 維持 X、最新の保存可能な GCI
Y |
| 新しいログの開始 | 10 | INFO | ログ パート X、MB の開始
Y、MB の停止
Z |
| ノードのクラスタへ包含が拒否されました。 | 8 | INFO | 設定の間違いによりノードをクラスタに含めることができません。通信の確立の失敗、または他の問題 |
| データ ノード ネーバー | 8 | INFO | 近くのデータ ノードの表示 |
データ ノードの起動フェーズX
完了 | 4 | INFO | データ ノードの起動フェーズの完了 |
| ノードが無事クラスタに含まれました | 3 | INFO | ノード、管理ノード、およびダイナミック ID の表示 |
| データ ノードの起動フェーズの開始 | 1 | INFO | NDB クラスタ ノードの開始 |
| データ ノードのすべての起動フェーズの完了 | 1 | INFO | NDB クラスタノードの開始 |
| データ ノードのシャットダウン開始 | 1 | INFO | データ ノードのスアットダウンが開始されました |
| データ ノードのシャットダウンの失敗 | 1 | INFO | データ ノードの通常のシャットダウン不可 |
NODERESTART
Events
以下のイベントがノードを再起動すると生成されノード再起動の成功あるいは失敗に関連します。
| イベント | 優先度 | 深刻度レベル | 説明 |
| ノードの失敗フェーズの完了 | 8 | ALERT | ノード失敗フェーズの完了レポート |
ノードが失敗しました。ノードの状態は
X | 8 | ALERT | ノード失敗のレポート |
| アービトレーターの結果のレポート | 2 | ALERT | アービトレーション試行で 8
つの頃なる結果があります
|
| フラグメントのコピー完了 | 10 | INFO | ? |
| ディレクトリ情報にコピー完了 | 8 | INFO | ? |
| 配布情報のコピー完了 | 8 | INFO | ? |
| フラグメントのコピー開始 | 8 | INFO | ? |
| すべてのフラグメントのコピー完了 | 8 | INFO | ? |
| GCP 引継ぎ開始 | 7 | INFO | ? |
| GCP 引継ぎ開始 | 7 | INFO | ? |
| LCP 引継ぎ開始 | 7 | INFO | ? |
LCP 引継ぎ完了 (ステート = X) | 7 | INFO | ? |
| アービトレーターの有無のレポート | 6 | INFO | アービトレーターには 7 種類の結果が可能
|
STATISTICS
イベント
以下のイベントは統計的なものです。トランザクション数、および他のオペレーション、転送したデータ量あるいは受信した個々のノード、およびメモリの使用などに関する情報を提供します。
| イベント | 優先度 | 深刻度 | 説明 |
| ジョブ スケジューリング統計レポート | 9 | INFO | 平均内部ジョブ スケジューリング統計 |
| 送信バイト数 | 9 | INFO | 平均ノード送信バイト数X |
| 受信バイト数 | 9 | INFO | ノードからの平均受信バイト数X |
| トランザクション統計のレポート | 8 | INFO | 回数:トランザクション、実行、読み込み、単純読み込み、書き込み、現在のオペレーション、属性情報、および失敗 |
| オペレーションのレポート | 8 | INFO | オペレーション数 |
| テーブル作成のレポート | 7 | INFO | ? |
| メモリの使用 | 5 | INFO | データおよびメモリの使用状況 (80%, 90%, and 100%) |
ERROR
イベント
これらのイベントはクラスタのエラーおよび警告に関するものです。1 つ以上の記録がここにある場合、それは重大な誤動作および不具合が発生したことを示しています。
| イベント | 優先度 | 深刻度 | Description |
| 不明なハートビートによるシステム停止 | 8 | ALERT | ノードX
による「不明ハートビートによる」システム停止の宣言 |
| トランスポーターエラー | 2 | エラー | ? |
| トランスポーター警告 | 8 | WARNING | ? |
| 不明なハートビート | 8 | WARNING | ノードX
不明なハートビート数Y |
| 一般的な警告イベント | 2 | WARNING | ? |
INFO
イベント
これらのイベントはクラスタおよびログおよびハートビート伝送などのクラスタのメンテナンス活動の状態に関する一般的な情報を提供します。
| イベント | 優先度 | 深刻度 | 説明 |
| 伝送ハートビート | 12 | INFO | ノードへのハートビート伝送X |
| ログ バイトの作成 | 11 | INFO | ログの部分、ログ ファイル、MB |
| 一般的な情報イベント | 2 | INFO | ? |
NDB マネジメント
クライアントの CLUSTERLOG STATISTICS
コマンドではその出力に対する様々な統計を提供します。以下の統計がトランザクション
コーオーディネーターからレポートされます。
| 統計 | 説明 (回数...) |
Trans.Count | コーオーディネーターとしてこのノードで試されたトランザクション回数 |
Commit Count | コーオーディネーターとしてこのノードで実行されたトランザクション |
Read Count | プライマリ キーの読み込み数 (すべて) |
Simple Read Count | プライマリ キーの最新の実行値の読み込み |
Write Count | プライマリ キーの書き込み (INSERT,
UPDATE、および
DELETE
オペレーションのすべてを含む) |
AttrInfoCount | 受信したすべての読み込みおよびかみこみの説明に使用したデータの単語数 |
Concurrent Operations | レポートが取得された時の実行中のすべての同時進行オペレーション数 |
Abort Count | このノードがコーオーディネーターとして実行したトランザクションの失敗した数 |
Scans | スキャン (すべて) |
Range Scans | インデックスのスキャン数 |
ndbd プロセスには無限ループで実行されるスケジューラがあります。各ループ スケジューラは以下のタスクを実行します。
ソケットからジョブバッファに受信メッセージを読み込みます。
時間を区切ったメッセージが実行されているかチェックします。実行されている場合、同様にジョブ バッファに導入します。
ジョブ バッファのメッセージを実行 (ループで) します。
ジョブ バッファでメッセージを実行することによって生成された配布メッセージを送信します。
メッセージの受信を待ちます。
3 番目のステップで実行されたループ数が
Mean Loop Counter
としてレポートされます。この統計のサイズが
TCP/IP
のバッファの利用が改善することによって大きくなります。新しいプロセスをクラスタに追加する際にこのモニタ
パフォーマンスを使用できます。
Mean send size および Mean
receive size
の統計でノード間の書き込みおよび読み込みの効率を測ることができます。これらの値はバイトで表されます。大きい値はバイト毎の送受信のコストが低いことを意味します。最大は
64k です。
すべてのクラスタ
ログの統計をログするには、NDB
マネジメント
クライアントの以下のコマンドを使用できます。
ndb_mgm> ALL CLUSTERLOG STATISTICS=15
注:STATISTICS
の閾値を 15 に設定するとクラスタ
ログが非常に冗長になり、クラスタの
ノード数およびクラスタの活動量に直接比例して直ぐにサイズが大きくなります。
単一ユーザーモード ではデータベースの管理者が MySQL サーバー (SQL ノード) あるいはndb_restore のインスタンスのようにデータベースへのアクセスを単一の APl ノードに制限できます。単一ユーザーモードに鳴ると、すべての他の API ノードが優雅に閉じられすべての実行中のトランザクションが中断されます。新しいトランザクションは実行されません。
クラスタが単一ユーザーモードになると、指定された API ノードのみがデータベースにアクセスできます。
クラスタが単一ユーザーモードに何時なった表示するにはALL STATUS コマンドを使用できます。
例:
ndb_mgm> ENTER SINGLE USER MODE 5
コマンドが実行されクラスタが単一ユーザーモードになると、ノード
ID が 5 の API
ノードがクラスタの唯一許可されたユーザーになります。
前のコマンドで指定されたノードは API ノードのなりますので、他のノード タイプを指定しようとしても拒否されます。
注:前のコマンドが呼び出されると、指定されたノードで実行中のすべてのトランザクションは中断されて接続の閉じますので、サーバーを再起動する必要があります。
EXIT SINGLE USER MODE のコマンドはクラスタのデータ ノードの状態を単一ユーザーモードから通常モードに変更します。接続を待っている (つまり、クラスタが準備が整い利用できる状態) MySQL Server? などのAPl ノード?は、再度接続を許可されます。単一ユーザーノードとしてAPI ノードはその状態が変更中あるいは変更後も (接続されている場合) 実行し続けます。
例:
ndb_mgm> EXIT SINGLE USER MODE
単一ユーザーモードで稼働中のノード不良を処理する 2 つの方法をお勧めしています。
メソッド 1:
すべての単一ユーザーモードのトランザクションを終了する
EXIT SINGLE USER MODE コマンドを発行する
クラスタのデータ ノードを再起動する
メソッド 2:
単一ユーザーモードに入る前にデータベース ノードを再起動する
この項ではバックアップの作成の仕方およびその後のバックアップのデータベースの保存に仕方について説明します。
バックアップは所定の時間でのデータベースのスナップショットです。バックアップは 3 つの主な要素で構成されます。
メタデータ:すべてのデータベース テーブルの名前と定義
テーブル レコード:バックアップしたときのデータベース テーブルに保存された実際のデータ
トランザクション ログ:データがデータベースにどのように何時保存されたを記録したシーケンシャルなレコード
これらの各要素はバックアップに使用されたすべてのノードに保存されます。バックアップ中に、各ノードはこれらの 3 つの要素をディスクの 3 つのファイルに保存します。
BACKUP-backup_id.node_id.ctlコントロール情報およびメタデータを含むコントルール ファイルです。各ノードは同じテーブル定義 (クラスタのすべてのテーブルの) をこのファイルのそれ自身のバージョンに保存します。
BACKUP-backup_id-0.node_id.dataテーブル レコードを含むデータ ファイルで、フラグメント毎に保存されます。つまり、バックアップ中に異なるノードが異なるフラグメントを保存します。各ノードに保存されたファイルがテーブルにどのデータが入っているかを示すヘッダーから始まります。レコードのリストに続いてすべてのレコードのチェックサムを含むフッターが表示されます。
BACKUP-backup_id.node_id.log実行されたトランザクションのレコードを含むログ ファイルバックアップで保存されたテーブルのトランザクションのみがログの保存されます。バックアップに関わったノードは異なるノードは異なるデータベースのフラグメントをホストするために異なるレコードを保存します。
上記おリストで、backup_id
はバックアップ識別子を表しており、node_id
はファイルを作成する一意の識別子を表します。
バックアップを開始する前に、クラスタが実行するものに対して適切に設定されているか確認します。(項14.8.4. 「クラスタ バックアップの設定」 参照。)
マネジメント クライアントを使用したバックアップの作成には以下のステップが含まれます。
マネジメント クライアントを起動 (ndb_mgm) します。
START BACKUPコマンドを実行します。マネジメント クライアントが次のように応答します。
Waiting for completed, this may take several minutes Node 1: Backup
backup_idstarted from nodemanagement_node_idここでは、
backup_idは特定のバックアップのための一意の識別子です。(設定が保存できるようになっている場合、この識別子もクラスタ ログの保存できます。)management_node_idはマネジメント クライアントが接続されるマネジメントのノード ID です。これはクラスタがバックアップの要求を受信して処理することを意味しています。それはバックアップが完了したことを意味するのではありません。
注:バックアップのメッセージは MySQL 5.1.12 or 5.1.13 のクラスタには記録されませんでした。バックアップ オペレーションのログは MySQL 5.1.14 には保存されました (Bug#24544 参照) 。
バックアップが完了すると、マネジメント .クライアントはバックアップ完了を以下のように示します。
Node 1: Backup
backup_idstarted from nodemanagement_node_idcompleted StartGCP: 417599 StopGCP: 417602 #Records: 105957 #LogRecords: 0 Data: 99719356 bytes Log: 0 bytesStartGCP、StopGCP、#Records、#LogRecords、Data、およびLogに表示された値はクラスタの特性により変化します。
クラスタのバックアップは各データ ノードの
DataDir の BACKUP
サブディレクトリのデフォルトによって作成されます。これは
1 つ以上のデータ
ノードに個別に、またはconfig.ini
ファイルのすべてのクラスタ データ ノードに
BackupDataDir
設定パラメータを使用して
Identifying
Data Nodes
で説明したようにオーバーライドされます。所定の
backup_id
でバックアップに作成されたバックアップファイルはディレクトリの
BACKUP-
の名前のサブディレクトリに保存されます。
backup_id
既に実行中のバックアップを中断します。
マネジメント クライアントを終了します。
このコマンドを実行します。
ndb_mgm>
ABORT BACKUPbackup_idbackup_idの番号はバックアップが開始されたとき (Backupのメッセージで) のマネジメント クライアントの応答に含まれるバックアップの識別子です。backup_idstarted from nodemanagement_node_idマネジメント クライアントは中断要求を
Abort of backupで認識します。注:この段階で、マネジメント クライアントはクラスタ データ ノードからこの要求の応答を受け取っておらず、バックアップは実際のところまだ中断されていません。backup_idorderedバックアップが中断されると、マネジメント クライアントは中断されたことを以下に類似した方法でレポートします。
Node 1: Backup 3 started from 5 has been aborted. Error: 1321 - Backup aborted by user request: Permanent error: User defined error Node 3: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error Node 2: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error Node 4: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error
この例では、4 つのデータ ノードを持つクラスタのサンプル出力を例示しました。そこでの中断されるバックアップのシーケンス番号は
3で、クラスタ マネジメント クライアントが接続されるマネジメント ノードのノード ID は5です。その中断の理由がユーザーの要求によるバックアップ レポートの中断を完了する最初のノードT(残りのノードはバックアップの中断は未指定の内部エラーによるものだとレポートします。)注:クラスタ ノードがABORT BACKUPコマンドに対し特定の順序で応答するかは保証はありませんBackupメッセージはバックアップが終了し、このバックアップに関連したすべてのファイルがクラスタのファイルシステムからさ削除されたことを意味します。backup_idstarted from nodemanagement_node_idhas been aborted
このコマンドを使用してシステム シェルから実行中のバックアップを中断することもできます。
shell> ndb_mgm -e "ABORT BACKUP backup_id"
注:ABORT
BACKUP が発行された時に ID
backup_id
を持つバックアップが無い場合、マネジメント
クライアントは応答せず、無効な中断コマンドが送信されましたの表示もされません。
クラスタの復旧プログラムは個別のコマンドライン
ユーティリティ ndb_restore
として実装されており、通常は MySQL
bin
ディレクトリにあります。このプログラムはバックアップの結果生成されたファイルを読みデータベースに保存された情報を挿入します。
ndb_restore
をバックアップを作成するために使用した
START BACKUP
コマンドにより作成された各バックアップファイルに対し一度実行する必要があります。(項14.8.2. 「バックアップを作成するためのマネジメント
クライアントの使用」
参照).これはバックアップが作成された時点のクラスタのデータ
ノード数の相当します。
注:ndb_restore を使用する前に、並列で複数のデータ ノードを復旧していない限り、クラスタが単一ユーザーモードで動作させることをお勧めします。単一ユーザーモードに関する情報は、項14.7.4. 「単一ユーザーモード」 を参照してください。
このユーティリティの一般的なオプションを以下に示します。
ndb_restore [-cconnectstring] -nnode_id[-m] -bbackup_id-r/path/to/backup/files
-c オプションは
ndb_restore にクラスタ
マネジメント
サーバーの位置を知らせる接続文字列を指定するために使用します。(接続文字列に関する情報は、項14.4.4.2. 「クラスタの 接続文字列」
を参照してください。)このオプションを使用していない場合、ndb_restore
が localhost:1186 のマネジメント
サーバーに接続を試みます。このユーティリティは
API ノードとして機能し、クラスタ
マネジメント
サーバーに接続するにはフリー接続の
「slot」
ガ必要です。このことは少なくとも 1 つの
[API] あるいは
[MYSQLD]
セクションがあり、クラスタの
config.ini
ファイルで使用できるということです。最低でも
1 つの空の [API] あるいは
[MYSQLD] セクションを
この目的のために MySQL
サーバーあるいは他のアプリケーションで使用されていない
config.ini
の持つことはいい考えです(項14.4.4.6. 「SQL および他の API ノードの定義」
参照)。
ndb_restore がクラスタに ndb_mgm マネジメント クライアントの SHOW コマンドを使用して接続されていることを検証できます。この検証を以下のシステム シェルで行うこともできます。
shell> ndb_mgm -e "SHOW"
-n
はバックアップが行われたデータ
ノードのノード ID
を指定するために使用します。
最初に ndb_restore
復旧プログラムを実行する際には、メタデータも復旧する必要があります。換言すれば、データベースのテーブルを再度作成する必要があります?
これはそれを -m
オプションで行うことで実行できます。バックアップを復旧する際にはクラスタに空のデータベースが無ければならないことを忘れないでください。(言い換えれば、復旧を行う前に
ndbd を --initial
で起動する必要があります。またデータ ノード
DataDir にあるディスク データ
ファイルを手動で削除する必要があります。.)
-b オプションはバックアップの ID
あるいはシーケンス番号を指定するために使用し、バックアップの完了時に
Backup メッセージのマネジメント
クライアントに表示される番号を同じです。(項14.8.2. 「バックアップを作成するためのマネジメント
クライアントの使用」
参照。)
backup_id
completed
-r
オプションは必要で、ndb_restore
にバックアップ
ファイルのあるディレクトリの所在を知らせるために使用されます。重要クラスタのバックアップを復旧する際、同じバックアップ
ID を持つバックアップのすべてのデータ
ノードの復旧を確認する必要があります。
作成されたものとは異なる設定のデータベースにバックアップを復旧することができます。例えば、2
および 3 のノード ID を持つ 2
つのデータベース
ノードの持つクラスタで作成されたバックアップ
ID 12 を持つバックアップは、4
つのノードを持つクラスタに保存する必要があります。次に
ndb_restore 2
回実行する必要があります ?
バックアップが行われたクラスタの各データベース
ノードに 1
回ずづです。しかし、ndb_restore は
MySQL の 1
つのバージョンで動作しているクラスタで作成されたバックアップを異なる
MySQL
バージョンで動作中のクラスタの常に復旧できるとは限りません。詳細については、項14.5.2. 「クラスタのアップグレードおよびダウングレードの互換性」
をご参照してください。
注:復旧を素早く行いたい場合には、十分な数のクラスタの接続が可能な場合データは並列で復旧できます。つまり、並列で複数のノードに復旧する際、各同時進行の
ndb_restore
プロセスに利用できるクラスタ
config.ini ファイルに
[API] あるいは
[MYSQLD]
セクションを持つ必要があります。しかし、データ
ファイルは常にログの前に適用する必要があります。
このプログラムのオプションの完全なリストを以下のテーブルに示します。
| 長いフォーム | 短いフォーム | Description | デフォルト値 |
--backup-id | -b | バックアップ シーケンス ID | 0 |
--backup_path | 該当なし | バックアップ ファイルへのパス | ./ |
--character-sets-dir | 該当なし | 文字セット情報が得られるディレクトリの指定 | 該当なし |
--connect,
--connectstring、あるいは
--ndb-connectstring | -c あるいは -C | 接続文字列の設定
[nodeid=
フォーマット | 該当なし |
--core-file | 該当なし | エラーの場合コア ファイルを記述 | TRUE |
--debug | -# | デバッグ ログの出力 | d:t:O, |
--dont_ignore_systab_0 | -f | 復旧の際システム テーブルを無視しない? 試験用で生産用ではありません | FALSE |
--help あるいは--usage | -? | 利用可能なオプションと現在の値を含むヘルプ メッセージの表示、そして終了 | [該当なし] |
--ndb-mgmd-host | None | マネジメント
サーバーの接続のためのホストとポートを
--connect,
--connectstring、あるいは
--ndb-connectstring
と同じだが、nodeidの指定はない | 該当無し |
--ndb-nodegroup-map | -z | ノード グループのマップの指定 ?
構文:リスト
(source_nodegroup,
destination_nodegroup) | 該当なし |
--ndb-nodeid | 該当なし | 次にノード ID の指定 ndb_restore プロセス | 0 |
--ndb-optimized-node-selection | 該当なし | トランザクションのノード選択の最適化 | TRUE |
--ndb-shm | 該当なし | 利用可能な場合共有メモリの使用 | FALSE |
--no-restore-disk-objects | -d | テーブル スペースやログ ファイル グループなどのディスク データ オブジェクトは復旧しない | FALSE
(換言すると、このオプションが使用されない場合ディスク
データ オブジェクトを復旧する) |
--nodeid | -n | ノードのバックアップ ファイルを指定した ID で使用する | 0 |
--parallelism | -p | 復旧プロセスで使用される並列トランザクションを 1 〜1024 設定する | 128 |
--print | 該当なし | データとログと次にプリントするstdout | FALSE |
--print_data | 該当なし | データと次のプリントするstdout | FALSE |
--print_log | 該当なし | ログと次にプリントするstdout | FALSE |
--print_meta | 該当なし | メタデータを次にプリントするstdout | FALSE |
--restore_data | -r | データとログの復旧 | FALSE |
--restore_epoch | -e | エポック データをステータス
テーブルに復旧する。適切な場合
ID0 を持つ
cluster.apply_status
の行に挿入あるいは更新されます。?これはレプリケーションを
MySQL Cluster レプリケーション
スレーブで開始する場合に便利です。 | FALSE |
--restore_meta | -m | テーブル メタデータの復旧 | FALSE |
--version | -V | バージョン情報を更新して終了 | [該当なし] |
注:ndb_restore
は一時的および永久的なエラーをレポートします。一時的なエラーの場合、そのエラーから回復することができる場合があります。MySQL
5.1.12 以降では、そのような場合、Restore
successful, but encountered temporary error, please look at
configuration のようにレポートされます。
バックアップには 4 つの設定パラメータが必要です。
BackupDataBufferSizeディスクに書き込まれる前のデータのバッファに必要なメモリ容量
BackupLogBufferSizeこれらがディスクに書き込まれる前のログ レコードのバッファに必要なメモリ容量
BackupMemoryデータベース ノードで割り当てられたバックアップ用のメモリの合計これはデータ バックアップ用のバッファおよびログのバックアップ用バッファに割り当てられたメモリの合計になります。
BackupWriteSizeディスクに書き込まれたブロックのデフォルトのサイズこれはデータのバックアップ用バッファおよびログのバックアップ用バッファの両方に適用されます。
BackupMaxWriteSizeディスクに書き込まれたブロックの最大サイズこれはデータのバックアップ用バッファおよびログのバックアップ用バッファの両方に適用されます。
これらのパラメータに関する詳細は Backup Parameters にあります。
バックアップ要求を出した際にエラーコードが返された場合は、その原因はメモリあるいはディスクのスペース不足の場合がよくあります。バックアップに十分なメモリが割り当てられているか確認する必要があります。重要BackupDataBufferSize
および BackupLogBufferSize
を設定してその合計が 4MB
以上の場合、BackupMemory
も同様に設定する必要があります。BackupMemory
参照。
バックアップに必要な容量に対してハードドライブのパーテッションに十分なスペースがあることも確認する必要があります。
NDB
は繰り返しの読み込みをサポートしていないので、これが復旧プロセスで問題を引き起こします。バックアップのプロセスは
「hot」 ですが、バックアップから MySQL
クラスタを復旧するのは 100% 「hot」
なプロセスではありません。これは復旧プロセスの期間に対してトランザクションの実行によって復旧データから繰り返し出来ない読み込みがあるからです。これは復旧を実行中のデータの状態が一貫していないからです。
- 14.9.1. ndb_config ? NDB 設定情報の抽出
- 14.9.2. ndb_delete_all ? NDB テーブルからのすべての行を削除する
- 14.9.3. ndb_desc ? NDB テーブルの説明
- 14.9.4. ndb_drop_index
- 14.9.5. ndb_drop_table
- 14.9.6. ndb_error_reporter
- 14.9.7. ndb_print_backup_file
- 14.9.8. ndb_print_schema_file
- 14.9.9. ndb_print_sys_file
- 14.9.10. ndb_select_all
- 14.9.11. ndb_select_count
- 14.9.12. ndb_show_tables
- 14.9.13. ndb_size.pl ? NDBCluster サイズ仕様エスティメーター
- 14.9.14. ndb_waiter
この項では mysql/bin
ディレクトリにある MySQL Cluster のユーティリティ
プログラムについて説明します。これらのすべて?
ndb_size.pl および
ndb_error_reporter
を除く?はスタンドアロンのバイナリでシステム
シェルから使用でき、MySQL サーバー (MySQL
サーバーをクラスタに接続する必要もなし)
に接続する必要はありません。
これらのユーティリティは NDB API
を使用したお客様のアプリケーションの記述する際の例として使用できます。これらのプログラムのソースコードは
MySQL5.1 ツリーの
storage/ndb/tools
ディレクトリにあります
(項2.9. 「ソースのディストリビューションを使用した MySQL
のインストール」
参照)。NDB API
はこのマニュアルでは説明していません。この API
に関する情報は
NDB API
Guide を参照してください。
すべてのNDB
ユーティリティが簡単な説明とともにここに掲載しています。
ndb_config:クラスタ設定オプション値を取り出します。
ndb_delete_all:所定のテーブルからすべての行を削除します。
ndb_desc:
NDBテーブルのすべてのプロパティのリストです。ndb_drop_index:
NDBテーブルから指定したインデックスを削除します。ndb_drop_table:
NDBテーブルを削除します。ndb_error_reporter:クラスタの問題を分析する情報を集めるために使用します。
ndb_mgm:これは 項14.7.2. 「マネジメント クライアントのコマンド」 で説明したMySQL Cluster のマネジメント クライアントです。
ndb_print_backup_file:クラスタのバックアップ ファイルから取得した分析情報をプリントします。
ndb_print_schema_file:クラスタ スキーマ ファイルから取得したの分析情報をプリントします。
ndb_print_sys_file:クラスタ システム ファイルから取得した分析情報をプリントします。
ndb_restore:バックアップからクラスタを復旧するために使用されるユーティリティです。詳細については、項14.8.3. 「クラスタのバックアップの復旧方法」 をご参照してください。
ndb_select_all:
NDBテーブルのすべての行をプリントします。ndb_select_count:1 つ以上の
NDBテーブルの行番号を取得します。ndb_show_tables:クラスタのすべての
NDBテーブルを表示します。ndb_size.pl:所定の非クラスタ データベースのすべてのテーブルを調べ、
NDBストレージ エンジンを使用するために変換された時に必要なそれぞれのストレージの容量を計算します。ndb_waiter:マネジメント クライアントのコマンド
ALL STATUSを同じような方法でクラスタのデータ ノードの状態をレポートします。
これらのユーティリティの多くは機能するためにはクラスタのマネジメント
サーバーの接続する必要があります。その例外は
ndb_size.pl
(以下参照)、およびクラスタのデータ ノード
ファイルシステムにアクセスしよってデータノードのホストで動作する必要のある以下のユーティリティです。
ndb_print_backup_file
ndb_print_schema_file
ndb_print_sys_file
ndb_size.pl は Perl
スクリプトでこれもまたシェルで使用されます。しかし、それは
MySQL アプリケーションですので MySQL
サーバーに接続できることが必要です。このスクリプトを使用する際の要件については、項14.9.13. 「ndb_size.pl ? NDBCluster サイズ仕様エスティメーター」
を参照してください。
ndb_error_reporter もまた Perl スクリプトです。それはクラスタのデータノードおよびマネジメント ノード ログをバグ レポートと一緒に tarball に集めるために使用します。ノートのファイルシステムに遠隔でアクセスするために ssh あるいは scp を使用できます。
これらのユーティリティ (ndb_mgm および ndb_restore を除く) のそれぞれに関する情報は次項以降で説明します。
注:これらのすべてのユーティリティ (ndb_size.pl および ndb_config を除く) は 項14.6.5. 「MySQL Cluster プロセスのコマンド オプション」 で説明したオプションを使用できます。各ユーティリティプログラムに特定のその他のオプションはそれぞれのプログラム一覧表で説明しています。
これらのオプションを使用する順番は一般的にはそれほど重要ではありません。例えば、これらのすべてのコマンドはすべての同じ出力をもたらします。
ndb_desc -c localhost fish -d testndb_desc fish -c localhost -d testndb_desc -d test fish -c localhost
このツールはデータ ノード、SQL
ノード、および API
ノードの設定情報をクラスタのマネジメント
ノード (およびその config.ini
ファイル) から抽出します。
使用法:
ndb_config options
このユーティリティーに利用できるoptions
はどことなく他のユーティリティに使用されるものとは異なっておりますので、次項でいくつの例と共にその全体を説明します。
オプション:
は ndb_config に利用可能なオプションのリストをプリントさせ、次に終了します。
は ndb_config にバージョン情報の文字列をプリントさせ、次に終了します。
--ndb-connectstring=connect_stringマネジメント サーバーの接続に使用される
connectstringを指定します。接続文字列のフォーマットは 項14.4.4.2. 「クラスタの接続文字列」 での説明と同じで、localhost:1186のデフォルトです。このオプションへの
-cの短いバージョンとして使用は ndb_config に対しては MySQL 5.1.12 以降でポートしています。マネジメント サーバーの設定ファイル (
config.ini) にパスを提供します。これは相対あるいは絶対パスです。マネジメント ノードが ndb_config が呼び出されるものと異なるホストにある場合、絶対パスを使用する必要があります。--query=,query-options-qquery-optionsこれはコンマ区切りの クエリ オプションのリスト ? つまり返される 1 つ以上のノード属性です。これらには
id(ノード ID)、タイプ (ノード タイプ? つまり、ndbd、mysqld、あるいはndb_mgmd)、およびそれらの値が取得される設定パラメータが含まれています。例、
--query=id,type,indexmemory,datamemoryはノード ID、ノード タイプ、DataMemory、およびIndexMemoryを各ノードに返します。注:所定のパラメータがあるタイプのノードに適用できない場合、空の文字列が相当する値に返されます。詳細はこの項の後の部分にあるサンプルを参照してください。
設定情報が返されるノードのホスト名を指定します。
--id=,node_id--nodeid=node_id設定情報が返されるノードのノード ID の指定に使用されます。
(ndb_config に
[ndbd]セクションでのみ定義されたパラメータの情報のプリントを指示します。現在、このオプションは値のチェックのみで機能していませんが将来的には[tcp]および他のクラスタ 設定ファイルのセクションで設定されたパラメータのクエリに使用する予定です。指定された
node_type(ndbd,mysqld、あるいはndb_mgmd) ノードに適用した設定値のみが返されるように結果にフィルタをかけます。--fields=,delimiter-fdelimiter結果のフィールドを分けるために使用する
delimiter文字列を指定します。デフォルトは 「、」 (コンマです)。注:
delimiterがスペースあるいはエスケープ (ラインフィード文字の\nなど) を含む場合、引用する必要があります。--rows=,separator-rseparator結果の行を分けるために使用する
separator文字列を指定します。デフォルトはスペース文字です。注:
separatorがスペースあるいはエスケープ (ラインフィード文字の\nなど) を含む場合、それを引用する必要があります。
例:
クラスタのノード ID および各ノードのタイプを取得する。
shell>
./ndb_config --query=id,type --fields=':' --rows='\n'1:ndbd 2:ndbd 3:ndbd 4:ndbd 5:ndb_mgmd 6:mysqld 7:mysqld 8:mysqld 9:mysqldこの例では、
--fieldsオプションを使用して ID および各ノードのタイプをコロン (:) で分けました。--rowsオプションは出力の新しい行の各ノードに値をつけました。データ、SQL、および API ノードがマネジメント サーバーの接続に使用する接続文字列を作成します。
shell>
./ndb_config --config-file=usr/local/mysql/cluster-data/config.ini --query=hostname,portnumber --fields=: --rows=, --type=ndb_mgmd192.168.0.179:1186ndb_config を実行してデータ ノードのみ (
--typeオプションを使用して) をチェックし、各ノード ID およびホスト名、およびそのDataMemory、IndexMemory、並びにDataDirパラメータを表示します。shell>
./ndb_config --type=ndbd --query=id,host,datamemory,indexmemory,datadir -f ' : ' -r '\n'1 : 192.168.0.193 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 2 : 192.168.0.112 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 3 : 192.168.0.176 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 4 : 192.168.0.119 : 83886080 : 18874368 : /usr/local/mysql/cluster-dataこの例では、短いオプション
-fおよび-rをフィールド区切り文字および行の分離符号の設定に使用しました。1 つの特別なものを除いてホストを結果から除外するには
--hostオプションを使用します。shell>
./ndb_config --host=192.168.0.176 -f : -r '\n' -q id,type3:ndbd 5:ndb_mgmdこの例でも、クエリされる属性を決定するために短いフォーム
-qを使用します。同様に、
--idあるいは--nodeidオプションを使用して特定の ID を持つノードに結果を制限できます。
ndb_delete_all は所定の
NDB
テーブルからすべての行を削除します。場合によっては、これは
DELETE あるいはむしろ
TRUNCATE
よりもかなり速くできます。
使用法:
ndb_delete_all -cconnect_stringtbl_name-ddb_name
これにより データベース
db_name のテーブル
tbl_name
の行をすべて削除します。それは MySQL
のTRUNCATE
で実行するのと全く同じです。
db_name.tbl_name
その他のオプション:
ndb_desc は 1 つ以上の
NDB
テーブルの詳細な説明を提供します。
使用法:
ndb_desc -cconnect_stringtbl_name-ddb_name
サンプル出力:
MySQL テーブルの作成およびポピュレーション ステートメント:
USE test;
CREATE TABLE fish (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(20),
PRIMARY KEY pk (id),
UNIQUE KEY uk (name)
) ENGINE=NDBCLUSTER;
INSERT INTO fish VALUES
('','guppy'), ('','tuna'), ('','shark'),
('','manta ray'), ('','grouper'), ('','puffer');
ndb_desc の出力:
shell> ./ndb_desc -c localhost fish -d test -p
-- fish --
Version: 16777221
Fragment type: 5
K Value: 6
Min load factor: 78
Max load factor: 80
Temporary table: no
Number of attributes: 2
Number of primary keys: 1
Length of frm data: 268
Row Checksum: 1
Row GCI: 1
TableStatus: Retrieved
-- Attributes --
id Int PRIMARY KEY DISTRIBUTION KEY AT=FIXED ST=MEMORY
name Varchar(20;latin1_swedish_ci) NULL AT=SHORT_VAR ST=MEMORY
-- Indexes --
PRIMARY KEY(id) - UniqueHashIndex
uk(name) - OrderedIndex
PRIMARY(id) - OrderedIndex
uk$unique(name) - UniqueHashIndex
-- Per partition info --
Partition Row count Commit count Frag fixed memory Frag varsized memory
2 2 2 65536 327680
1 2 2 65536 327680
3 2 2 65536 327680
NDBT_ProgramExit: 0 - OK
その他のオプション:
説明:NDB
テーブルから指定したインデックスを削除します。このユーティリティは
NDB API
アプリケーションを記述する際の例として使用することをお勧めします。
?
詳細はこの項の後にある警告を参照してください。
使用法:
ndb_drop_index -cconnect_stringtable_nameindex-ddb_name
上記のステートメントは次の名前のインデックス
index を
detabase の
table からさ削除します
その他のオプション:このアプリケーションに特定のものはありません。
警告:NDB API を使用してクラスタ テーブルのインデックスで実行したオペレーションは MySQL には表示されず MySQL サーバーではテーブルを使用できません。インデックスを削除するためにこのプログラムを使用して SQL ノードにアクセスしようとすると、以下のようにエラーになります。
shell>./ndb_drop_index -c localhost dogs ix -d ctest1Dropping index dogs/idx...OK NDBT_ProgramExit: 0 - OK shell>./mysql -u jon -p ctest1Enter password: ******* Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 7 to server version: 5.1.12-beta-20060817 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql> SHOW TABLES; +------------------+ | Tables_in_ctest1 | +------------------+ | a | | bt1 | | bt2 | | dogs | | employees | | fish | +------------------+ 6 rows in set (0.00 sec) mysql> SELECT * FROM dogs; ERROR 1296 (HY000): Got error 4243 'Index not found' from NDBCLUSTER
そのような場合、テーブルを MySQL
で再度使用できるようにする
唯一
のオプションはテーブルを削除して再度作成することです。テーブルを削除するには
SQL ステートメント DROP TABLE
あるいは ndb_drop_table
ユーティティ
(項14.9.5. 「ndb_drop_table」
参照) のいずれかを使用します。
説明:指定された
NDB テーブルを削除します。(NDB
ではなくストレージ
エンジンで作成されたテーブルでこれを使用すると、エラー
723
で失敗します。そのようなテーブルは存在しません。)ケースによってはこのオペレーションは非常に速く
? MySQL の NDB テーブルの
DROP TABLE
を使用した時よりも非常に速い順序になります。
使用法:
ndb_drop_table -cconnect_stringtbl_name-ddb_name
その他のオプション:無し
説明:アーカイブをバグあるいは他のクラスタの問題の分析を支援するデータ ノードあるいはマネジメント ノードからアーカイブを作成します。MySQL Cluster でバグのレポートをファイルするときにこのユーティリティを使用することを強くお勧めします。
使用法:
ndb_error_reporterpath/to/config-file[username] [--fs]
このユーティリティはマネジメント
ノードのホストで使用されるようになっており、マネジメント
ホストの設定ファイル (config.ini)
が必要です。オプションでは、SSH
でクラスタのデータ
ノードにアクセスできるユーザーの名前を提供できます。それによりデータ
ノードのログ
ファイルをコピーします。次に、それが実行されている同じディレクトリで作成されたアーカイブのこれらのファイルを含みます。アーカイブの名前は
ndb_error_report_、そこでは
YYYYMMDDHHMMSS.tar.bz2YYYYMMDDHHMMSS
は日時の文字列です。
--fs を使用すると、データ
ノードのファイルシステムはマネジメント
ホストにもコピーされ、このスクリプトで作成されたアーカイブに含まれます。データ
ノードのファイルシステムは圧縮後も非常に大きくなりますので、このこのオプションを使用して作成したアーカイブを特別な要求が無い限り
MySQL ABに送ら
ないようお願いします。
説明:クラスタのバックアップ ファイルから分析情報を取得します。
使用法:
ndb_print_backup_file file_name
file_name
はクラスタのバックアップ
ファイル名です。これはクラスタのバックアップ
ディレクトリにあるどのファイル
(.Data、.ctl、あるいは
.log ファイル)
でもできます。これらのファイルはサブディレクトリ
BACKUP-
の下のデータ ノードのバックアップ
ディレクトリにあります。そこでは
##
はバックアップのシーケンス番号ですクラスタのバックアップ
ファイルおよびそれらのコンテンツに関する詳細は、項14.8.1. 「クラスタ バックアップの概念」
を参照してください。
ndb_print_schema_file および
ndb_print_sys_file
(そして、マネジメント
サーバーホストで動作するあるいはマネジメント
サーバーに接続する他のほとんどの
NDB とは異なり)
ndb_print_backup_file
は、それが直接データ
ノードのファイルシステムにアクセスするため、クラスタのデータ
ノードで動作する必要があります。それはマネジメント
サーバーを使用しないため、このユーティリティはマネジメント
サーバーが稼動していない時、およびクラスタが完全にシャットダウンされた時に使用されます。
その他のオプション:無し
説明:クラスタのスキーマ ファイルから分析情報を取得します。
使用法:
ndb_print_schema_file file_name
file_name
はクラスタのスキーマのファイル名です。
ndb_print_backup_file および
ndb_print_sys_file
(そして、マネジメント
サーバーホストで動作するあるいはマネジメント
サーバーに接続する他のほとんどの
NDB ユーティリティとは異なり)
ndb_schema_backup_file
は、それが直接データ
ノードのファイルシステムにアクセスするため、クラスタのデータ
ノードで動作する必要があります。それはマネジメント
サーバーを使用しないため、このユーティリティはマネジメント
サーバーが稼動していない時、およびクラスタが完全にシャットダウンされた時に使用されます。
その他のオプション:なし
説明:クラスタのシステム ファイルから分析情報を取得します。
使用法:
ndb_print_sys_file file_name
file_name
はクラスタのシステム ファイル (sysfile)
名です。クラスタ システム
ファイルはノードのデータ ディレクトリ
(DataDir)
にあります。このディレクトリのシステム
ファイルへのパスは
ndb_
に一致します。.それぞれのケースで、#_fs/D#/DBDIH/P#.sysfile#
は番号
(必ずしも同じ番号である必要はありません)
を表します。.
ndb_print_backup_file および
ndb_print_schema_file
(そして、マネジメント
サーバーで動作するあるいはマネジメント
サーバーに接続するほとんどの他の
NDB ユーティリティとは異なり)
ndb_print_backup_file
は、それがデータ
ノードのファイルシステムと直接アクセスするので、クラスタのデータ
ノードで動作する必要があります。それはマネジメント
サーバーを使用しないため、このユーティリティはマネジメント
サーバーが稼動していない時、およびクラスタが完全にシャットダウンされた時に使用されます。
その他のオプション:なし
説明:すべての行を
NDB テーブルから
stdout にプリントします。
使用法:
ndb_select_all -cconnect_stringtbl_name-ddb_name[>file_name]
その他のオプション:
-l,lock_type--lock=lock_typeテーブルを読み込んでいるときにロックを使用します。
lock_typeに可能な値は:0: ロックを読む1: ホールドしてロックを読む2: 排他的読み込みロック
このオプションにはデフォルトの値はありません。
-o,index_name--order=index_nameindex_nameの名前のインデックスに基づいて出力を調整します。これはオンデックスの名前で、カラムの名前ではなく、インデックスは作成された時に、明示的に名前を付ける必要があります。-z,--descending降順で出力を分類します。このオプションは
-o(--order) オプションに関連してのみ使用されます。--header=FALSE出力からカラムのヘッダーを除外します。
-x,--useHexFormatすべての数値を16進数のフォーマットで表示します。これは文字列あるいは日時値に含まれる数値の出力に影響を与えません。
-D,character--delimiter=charactercharacterをカラムの区切り文字で使用できるようにします。この区切り文字ではターベルのデータ カラムのみが区切られます。デフォルトの区切り文字はタブの文字です。
--disk出力にディスク リファレンス カラムを追加します。このカラムは非インデックス カラムを持つディスク データ テーブルにのみノン エンプティです。
--rowid行が保存されるフラグメントに関する情報を提供する
ROWIDカラムを追加します。--gci各行が最後に更新された時にグローバル チェックポイントを表示する出力にカラムを追加します。チェックポイントに関する詳細は、項14.15. 「MySQL Cluster の用語」 および 項14.7.3.2. 「ログ イベント」 を参照してください。
-t,--tupscantubpe の順序でテーブルをスキャンします。
--nodataテーブルのデータを削除します。
サンプル出力:
MySQL SELECT
ステートメントからの出力
mysql> SELECT * FROM ctest1.fish;
+----+-----------+
| id | name |
+----+-----------+
| 3 | shark |
| 6 | puffer |
| 2 | tuna |
| 4 | manta ray |
| 5 | grouper |
| 1 | guppy |
+----+-----------+
6 rows in set (0.04 sec)
ndb_select_all に相当する実行からの出力:
shell> ./ndb_select_all -c localhost fish -d ctest1
id name
3 [shark]
6 [puffer]
2 [tuna]
4 [manta ray]
5 [grouper]
1 [guppy]
6 rows returned
NDBT_ProgramExit: 0 - OK
ndb_select_all
の出力ではすべての文字列の値は角括弧
(「[...]」)
で括ります。他の例については、作成されたテーブルを考慮し以下のように配布します。
CREATE TABLE dogs (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(25) NOT NULL,
breed VARCHAR(50) NOT NULL,
PRIMARY KEY pk (id),
KEY ix (name)
)
TABLESPACE ts STORAGE DISK
ENGINE=NDB;
INSERT INTO dogs VALUES
('', 'Lassie', 'collie'),
('', 'Scooby-Doo', 'Great Dane'),
('', 'Rin-Tin-Tin', Alsation),
('', 'Rosscoe', 'Mutt');
これはいくつかの追加の ndb_select_all オプションの使用に関して例示します。
shell> ./ndb_select_all -d ctest1 dogs -o ix -z --gci --disk
GCI id name breed DISK_REF
834461 2 [Scooby-Doo] [Great Dane] [ m_file_no: 0 m_page: 98 m_page_idx: 0 ]
834878 4 [Rosscoe] [Mutt] [ m_file_no: 0 m_page: 98 m_page_idx: 16 ]
834463 3 [Rin-Tin-Tin] [Alsation] [ m_file_no: 0 m_page: 34 m_page_idx: 0 ]
835657 1 [Lassie] [Collie] [ m_file_no: 0 m_page: 66 m_page_idx: 0 ]
4 rows returned
NDBT_ProgramExit: 0 - OK
説明:1 つ以上の
NDB
テーブルの行数をプリントします。1
つのテーブルでは、その結果は MySQL
ステートメント SELECT COUNT(*) FROM
を使用して得た結果と同じです。.
tbl_name
使用法:
ndb_select_count [-cconnect_string] -ddb_nametbl_name[,tbl_name2[, ...]]
その他のオプション:このアプリケーションに特定のものはありません。しかし、このコマンドを実行したときに、以下の Sample Output に示す様にスペースで分離されたテーブル名を記載することで同じデータベースの複数のテーブルの行計算を取得できます。
サンプル出力:
shell> ./ndb_select_count -c localhost -d ctest1 fish dogs
6 records in table fish
4 records in table dogs
NDBT_ProgramExit: 0 - OK
説明:クラスタのすべての
NDB データベース
オブジェクトのリストを表示します。デフォルトでは、これにはユーザー作成のテーブルおよび
NDB システム
テーブルの両方が含まむだけでなく、NDB-特定のインデックス、内部トリガ、およびクラスタ
ディスク データ
オブジェクトも同様に含まれます。
使用法:
ndb_show_tables [-c connect_string]
その他のオプション:
-l,--loopsユーティリティが実行すべき回数を指定します。このオプションが指定されない時はこれは 1 ですが、このオプションを使用する場合には、それの整数の引数を提供する必要があります。
-p,--parsableこのオプションを使用するとその出力を
LOAD DATA INFILEの使用に適したフォーマットにします。-t,--type以下に示す整数タイプのコードで指定された 1 種類のオブジェクトに出力を制限するために使用します。
1: System table
2: User-created table
3: Unique hash index
他の値はすべての
NDBデータベース オブジェクトをリスト (デフォルト) にします。-u,--unqualifiedこれを指定すると、許可されていないオブジェクト名を表示します。
注:ユーザー作成のクラスタ
テーブルのみが MySQL
からアクセスできます。SYSTAB_0 は
mysqld
には表示されません。しかし、ndb.select.all
などのNDB API
アプリケーションを使用してシステム
テーブルのコンテンツを調べることができます
(項14.9.10. 「ndb_select_all」
参照)。
これはそれが NDBCluster
ストレージ
エンジンを使用するために変換される場合の
MySQL
のデータベースで必要なスペースの量を見積もるために使用される
Perl
のスクリプトです。この項で説明した他のユーティティとは異なり、MySQL
Cluster
(実際のところ、接続する理由はないのだが)
とのアクセスは必要ありません。しかしながら、データベースの常駐をテストする
MySQL サーバーへのアクセスは必要です。
仕様:
稼働中の MySQL サーバーサーバーのインターフェースは MySQL Cluster にサポートを提供する必要はありません。
Perl の稼働中のインストール。
DBIおよびHTML::テンプレートモジュール、この両方はそれらが Perl のインストールの一部で無い場合 CPAN から取得できます。(多くの Linux および他のオペレーティング システムの配布はこれらの 1 つあるいは両方のバイナリにそれ自身のパッケージを提供します。ndb_size.tmplテンプレート ファイル、はMySQL のインストールのshare/mysqlディレクトリに見つかるはずです。このファイルはndb_size.pl? と同じディレクトリにコピーあるいは移動する必要があります。もしそれがそこに既に無い場合? スクリプトを実行する前に必要な権限を持つ MySQL ユーザーアカウント既存のアカウントの使用の希望されない場合、
GRANT USAGE ON? そこではdb_nameを使用して新たに作成します。*db_nameは検査されるデータベース名で? この目的には十分です。
ndb_size.pl および
ndb_size.tmpl は
storage/ndb/tools の MySQL
ソースにあります。これらのファイルが MySQL
のインストールに見つからない場合、MySQLForge
project page で入手できます。
使用法:
perl ndb_size.pldb_namehostnameusernamepassword>file_name.html
表示されたコマンドは
password を持つユーザー
username で MySQL
サーバーに hostname
で接続し、データベース
db_name
のすべてのテーブルを分析し、ファイル
file_name.htmlstdout に送られます。)数字はウェブ
ブラウザで表示される部分的なサンプル出力です。
このスクリプトの出力は以下を含みます。
テーブルの分析に必要な
DataMemory、IndexMemory、MaxNoOfTables、MaxNoOfAttributes、MaxNoOfOrderedIndexes、MaxNoOfUniqueHashIndexes、およびMaxNoOfTriggersの設定パラメータ。データベースで定義されたすべてのテーブル、属性、順序付けインデックス、および一意のハッシュ インデックスのメモリ要件。
テーブルおよびテーブル行毎に必要な
IndexMemoryおよびDataMemory。
説明:すべてのクラスタ
データ ノードのプリント
アウトをクラスタが所定のステータスになるまであるいは
--timeout
制限になりまで繰り返し(各 100
ミリセカンド毎)、その後終了します。デフォルトでは、すべてのノードが起動しクラスタに接続する状態を示すクラスタが
STARTED
ステータスになるまで待ちます。これは
--no-contact および
--not-started オプション
(Additional
Options 参照)
を使用することによって書き換えられます。
このノードはこのユーティリティで以下レポートされます。
NO_CONTACT:このノードは接続できません。UNKNOWN:このノードは接続せきません。そのステータスはまだ未詳です。通常、この表示はノードがSTARTあるいはRESTARTコマンドをマネジメント サーバーから受信しても、まだ実行されない状態を示します。NOT_STARTED:このノードは停止したが、まだクラスタと接続している状態を示します。この表示はノードをマネジメント クライアントのRESTARTコマンドを使用して再起動したときに表示されます。STARTING:ノードの ndbd プロセスが実行されたが、ノードがまだクラスタに接続していない状態を示します。STARTED:ノードは使用できるが、まだクラスタに接続していない状態です。SHUTTING_DOWN:ノードがシャットダウンされています。SINGLE USER MODE:これはクラスタが単一ユーザーモードの場合のすべてのクラスタ データ ノードの状態です。
使用法:
ndb_waiter [-c connect_string]
-n, --no-contact
STARTEDステートを待つ代わりに、ndb_waiter はクラスタがNO_CONTACTステータスになるまで継続し、終了すること示しています。--not-started
STARTEDステートを待つ代わりに、ndb_waiter がクラスタがNOT_STARTEDステータスになるまで継続して、終了すること示しています。-t, --timeout=#
待ち時間プログラムは指定した待ち時間(秒)内に実行されない場合終了します。デフォルトは 120 秒 (1200 レポート回数) です。
サンプル出力:
2
つのノードがシャットダウンし手動で起動した
4 つのノード クラスタを起動した際の出力
ndb_waiter
を示したものです。レポートにコピー
(「...」 による)
は削除されています。
shell> ./ndb_waiter -c localhost
Connecting to mgmsrv at (localhost)
State node 1 STARTED
State node 2 NO_CONTACT
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 UNKNOWN
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 UNKNOWN
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 STARTING
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTED
State node 3 STARTED
State node 4 STARTING
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTED
State node 3 STARTED
State node 4 STARTED
Waiting for cluster enter state STARTED
NDBT_ProgramExit: 0 - OK
Note:接続文字列が指定されていない場合、ndb_waiter
がマネジメントに
localhostで接続を試み、
Connecting to mgmsrv at (null)
をレポートします。
MySQL 5.1.6 以前のバージョンは、asynchronous replication、単に 「replication」 とよく呼ばれているものは、MySQL Cluster を使用した場合は利用できませんでした。MySQL 5.1.6 では MySQL Cluster のデータベースにマスタースレーブのレプリケーションを導入しています。この項では設定方法および設定の管理について説明します。そこでは MySQL Cluster として運用されている 1 つのグループのコンピュータを 2 番目コンピュータあるいは グループのコンピュータにレプリケートします。標準の MySQL レプリケーションに関しては読者の中にはこのマニュアルのどこかで説明した内容をご存知の方もおられると思います。(章?5. レプリケーション 参照。)
通常 (非クラスタ) のレプリケーションは
「master」 サーバーおよび 「slave」
を、マスタは運用のソースとして、データはレプリケートされるものとして、スレーブはこれらの受皿として含まれています。MySQL
Cluster
では、レプリケーションは概念的には非常に類似していますが、2
つの完全なクラスタ間のレプリケーションを含む多くの異なる設定をカバーするために拡張できるなど実際の運用においてはさらに複雑にできます。MySQL
Cluster そのものは NDB Cluster
ストレージ
エンジンにそのクラスタ機能を依存していますが、スレーブのクラスタ
ストレージ
エンジンを使用する必要はありません。しかしながら、最大の可用性を引き出すために、1
つの MySQL Cluster
から別へレプリケートでき、これが以下の図に示すここで説明する設定タイプです。
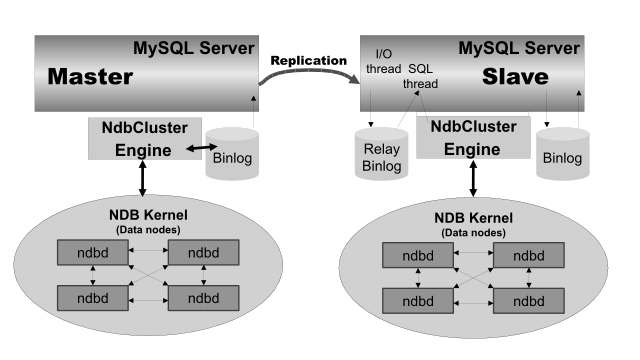
このシナリオでは、レプリケーション
プロセスはマスタ
クラスタの連続的なステートがログされスレーブのクラスタに保存されます。このプロセスは
NDB binlog
インジェクタースレッドとして知られる特別なスレッドによって実現され、それは書く
MySQL サーバー上で動作しバイナリのログ
(binlog)
を生成します。このスレッドはクラスタのすべての変更がバイナリのログ
? を生成し、MySQL Server ?
によって影響を受けたそれらの変更だけではなく正確なシリアル番号準にログに挿入されることを確認します。ここでは
MySQL レプリケーション
マスタおよびレプリケーション
サーバーとしてのレプリケーション
スレーブあるいはレプリケーション
ノード、およびそのデータ フローあるいは
replication channel
としてのそれらの間の通信ラインについて言及します。
この項を通じて、マスタおよびスレーブのクラスタ、クラスタあるいはクラスタ ノードで実行されるプロセス並びにコマンドに関する以下の略語および記号を使用します。
| 記号あるいは略語 | の説明 (参照...) |
M | (プライマリ) レプリケーション マスタとしてのクラスタ |
S | (プライマリ) レプリケーション スレーブとして機能するクラスタ |
shell | マスタ クラスタで発行されるシェル コマンド |
mysql | マスタ クラスタの SQL ノードとして動作する単一の MySQL サーバーで発行された MySQL クライアント コマンド |
mysql | レプリケーション マスタに使用されているすべての SQL ノードで発行される MySQL クライアント コマンド |
shell | スレーブ クラスタで発行される シェル コマンド |
mysql | スレーブ クラスタで SQL ノードとして実行される単一の MySQL サーバーで発行される MySQL コマンド |
mysql | MySQL client command to be issued on all SQL nodes participating in the replication slave cluster |
C | Primary replication channel |
C' | Secondary replication channel |
M' | Secondary replication master |
S' | Secondary replication slave |
レプリケーション チャネルには 2 台の MySQL サーバーをレプリケーション サーバー (マスタおよびスレーブに各 1 台ずつ) が必要です。例えば、2 つのレプリケーション チャンネル (冗長性を確保するために予備のチャンネルを提供する) でレプリケーションの設定をする場合、それぞれのクラスタ各 2 つのレプリケーション ノードがあるため合計で 4 つのレプリケーション ノードになることを意味します。
この項で説明する MySQL Cluster
のレプリケーションおよびそれに続くものは行バースのレプリケーションに依存しています。このことはレプリケーションのマスタ
MySQL サーバーは
項14.10.6. 「レプリケーションの開始 (シングル レプリケーション
チャネル)」
の説明のように --binlog-format=row
を一緒に起動する必要がありあす。行ベースのレプリケーションの一般的な情報は、
項5.1.2. 「レプリケーション フォーマット」
を参照してください。
(MySQL Cluster をステートメントをベースとしたレプリケーションでレプリケートすることができます。しかし、この場合、以下の制限が適用されます。マスタとの役割を担うクラスタのデータ行のすべての更新は単一の MySQL サーバーに割り当てる必要があります。いくつかの MySQL レプリケーション プロセスを使用して同時にクラスタをレプリケートすることはできません。SQL レベルでの変更のみレプリケートされます。)
クラスタのいずれかのレプリケーションに使用さ
MySQL サーバーはすいずれかのクラスタ (同じ ID
を共有するマスタおよびスレーブのクラスタの両方にレプリケーション
サーバーを持つことはできません)
に使用しているすべての MySQL レプリケーション
サーバー間で一意で認識される必要があります。これは各
SQL ノードを
--server-id=
オプションを使用して起動することで可能です。そこでは
idid
は一意の整数です。それは必ずしも必要ではありませんが、この説明の目的としてすべての
MySQL
のインストールは同じバーションであるものを想定しています。
いずれの場合でも、レプリケーションに使用する両方の MySQL サーバーは使用するレプリケーション プロトコルおよびそれらがサポートする SQL 機能セットに於いてお互い互換性がある必要があります。この場合にこれを確認する最も簡素で容易な方法は同じ MySQL バージョンを使用するすべてのサーバーに使用することです。多くの場合マスタのバージョンより古いバージョンを使用した MySQL バージョンで動作するスレーブでレプリケートすることはできません? 詳細は 項5.4.2. 「MySQL バージョン間のレプリケーション互換性」 を参照してください。
スレーブ サーバーあるいはクラスタはマスタのレプリケーション専用であり、他のデータはそれに保存されないものと想定しています。
以下はレプリケーションを MySQL 5.1 のMySQL Cluster で行う場合の既知の問題あるいは懸案事項です。
MySQL Cluster のレプリケーション スレーブ mysqld はマスタの接続が切断され、ログがバッファされないことを検知する方法がありません。このため、マスタが使用できなくなったりあるいはネットワークの問題が発生した場合、スレーブがマスタに対して一貫性が無くなる場合があります。
この問題を避けるために、複数のレプリケーション ラインを設け、プライマリのレプリケーション ラインでマスタ mysqld を監視し、必要に応じてフェールオーバーを 2 次側のラインに設定します。
この種の設定を行うための情報に関しては、項14.10.7. 「2 つのレプリケーション チャネルを使用する」、および 項14.10.8. 「MySQL Cluster にフェールオーバーを導入する」 を参照してください。
弊社では現在この問題の解決策を今後の MySQL Cluster のリリースも含めて検討しています。(この問題に関する説明は Bug#21494 にあります。)
循環的なレプリケーションはクラスタのレプリケーションではサポートしていません。これは特定の MySQL Cluster で作成されたすべてのログ イベントの マスタとして使用されている MySQL サーバーサーバーID のタグが間違っており、元のサーバーのサーバーID ではないからです。
その ID の間違いにより、MySQL サーバー A→B→A、そこでは B はクラスタ A に接続された MySQL サーバーで、クラスタ テーブル A からの変更 (ログ エントリ) により元のサーバーの識別名をB から A で失う 「lose」 からです。これによりその変更はサーバー A に再び適用されます。
CREATE TABLE、DROP TABLE、およびALTER TABLEなどのデータ定義ステートメントを使用はバイナリのログにそれが発行された MySQL サーバーにのみ記録されます。MySQL 5.1.6 では、明示のプライマリ キーを持つ
NDBのみがレプリケートされます。この制限は MySQL 5.1.7 が解除されています。クラスタを
--initialオプションで再起動すると GCI およびエポック番号が0から始まります。(これは一般的には MySQL Cluster では当たり前でクラスタを使用したレプリケーションのシナリオに限ったことではありません。レプリケーションに使用された MySQL サーバーはこの場合レプリケートされます。この後、RESET MASTERおよびRESET SLAVEステートメントを使用してndb_binlog_indexおよびndb_apply_statusテーブルをそれぞれクリアします。auto_increment_offsetおよびauto_increment_incrementサーバーシステムに変数を設定しようとすると予測できない結果がでます。これらの変数の使用は MySQL Cluster のレプリケーションではサポートされていません。
MySQL Cluster
でのレプリケーションではレプリケートされるクラスタおよびレプリケーション
スレーブ
(単一のサーバーあるいはクラスタのいずれか)
としての役割を果たす各 MySQL Server
インスタンスの mysql
データベースの多くの専用のテーブルを使用しています。これらのテーブルは
mysql_install_db スクリプトによって
MySQL のインストール中に作成され、バイナリ
ログのインデックス
データを保存するテーブルを含んでいます。ndb_binlog_index
テーブルは各 MySQL
サーバーに対してはローカルで、クラスタ化には使用されず、MyISAM
ストレージ
エンジンを使用します。このことはそれはマスタのクラスタに使用される各
mysqld
で個別に作成されることを意味しています。(しかし、binlog
そのものはレプリケートされるクラスタの MySQL
サーバーの更新を含んでいます。)このテーブルは以下のように定義されます。
CREATE TABLE `ndb_binlog_index` (
`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` BIGINT(20) UNSIGNED NOT NULL,
`updates` BIGINT(20) UNSIGNED NOT NULL,
`deletes` BIGINT(20) UNSIGNED NOT NULL,
`schemaops` BIGNINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`epoch`)
) ENGINE=MYISAM DEFAULT CHARSET=latin1;
重要MySQL 5.1.14
以前のバージンでは、ndb_binlog_index
テーブルは binlog_index
として知られ個別 cluster
データベースで維持され、それは MySQL 5.1.7
あるいはそれ以前のバージョンでは
cluster_replication
データベースとして知られていました。同様に、ndb_apply_status
および ndb_schema テーブルは
apply_status および
schema
として知られており、cluster
(以前は cluster_replication)
データベースにありました。しかし、MySQL 5.1.14
以降では、すべての MySQL Cluster
のレプリケーション テーブルは
mysql システム
データベースにあります。
この変更が MySQL Cluster 5.1.13 および 5.1.14 およびそれ以降のバージョンのアップグレードに影響を及ぼすかは 項C.1.3. 「Changes in release 5.1.14 (05 December 2006)」 を参照してください。
以下の図は MySQL Cluster のレプリケーション
マスタ サーバー、その binlog
インジェクタースレッド、および
mysql.ndb_binlog_index
テーブルのレプリケーションを表しています。
ndb_apply_status
の名前の新たなテーブルがマスタからスレーブにレプリケートされたオペレーションの記録を取るために使用されます。ndb_binlog_index
の場合と違って、このテーブルのデータはクラスタのどの
SQL ノード独自おものではないため、
ndb_apply_status は以下に示すように
NDB Cluster ストレージ
エンジンを使用できます。
CREATE TABLE `ndb_apply_status` (
`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY USING HASH (`server_id`)
) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
ndb_binlog_index および
ndb_apply_status
テーブルはそれらがレプリケートされる必要が無いため
mysql
データベースで作成されます。それらのいずれの作成および維持に関してユーザーが関与することは通常ありません。ndb_binlog_index
および ndb_apply_status
テーブルの双方は NDB
インジェクタースレッドで維持されます。これが
NDB ストレージ
エンジンで実行される変更に対する更新されたマスタ
mysqld
プロセスを維持します。NDB
binlog インジェクター
スレッドは NDB
ストレージ
エンジンから直接イベントを受け取ります。NDB
インジェクターはクラスタのすべてのデータ
イベントの取得を行い、データの変更、挿入、あるいは削除するすべてのイベントが
ndb_binlog_index
テーブルに記録されたことを確認します。スレーブ
I/O スレッドはイベントをマスタのバイナリ
ログからスレーブのリレーログに転送します。
しかし、これらのテーブルの存在と品質をレプリケーションに
MySQL Cluster
を準備する初期のステップで確認することをお勧めします。マスタで直接
mysql.binlog_index
テーブルをクエリするとバイナリ
ログに記録されたイベント
データを表示できます。これをレプリケーション
マスタあるいはスレーブ MySQL
サーバーのいずれかの SHOW BINLOG
EVENTS
ステートメントを使用して表示することもできます。
注:MySQL 5.1.14
以降では、apply_status
テーブルがスレーブに無い場合、ndb_restore
で作成できます。(Bug#14612)
MySQL Cluster のレプリケーションに準備をるには以下のステップを踏みます。
すべての MySQL サーバーのバージョンの互換性をチェックします (項14.10.2. 「仮定条件と一般要件」 参照)。
マスタ クラスタに権限付きのスレーブのアカウントを作成します。
mysql
M>GRANT REPLICATION SLAVE->ON *.* TO '->slave_user'@'slave_host'IDENTIFIED BY 'slave_password';slave_userがスレーブ アカウントのユーザー名の場合、slave_hostがレプリケーション スレーブのホスト名あるいは IP アドレスで、slave_passwordはこのアカウントを割り当てるパスワードです。例えば、スレーブ ユーザーアカウントを 「
myslaveの名前で作成する場合、」 ホスト名 「rep-slaveでログインし、」 パスワード 「53cr37を使用して、」 以下のGRANTステートメントを使用します。mysql
M>GRANT REPLICATION SLAVE->ON *.* TO 'myslave'@'rep-slave'->IDENTIFIED BY '53cr37';セキュリティのためには、一意のユーザーアカウント? 他の目的に使用されていない ? をレプリケーション スレーブ アカウントに使用するようお勧めします。
マスタを使用出来るようにスレーブを設定します。MySQL Monitor を使用すると、これを
CHANGE MASTER TOステートメントで実行できます。mysql
S>CHANGE MASTER TO->MASTER_HOST='->master_host',MASTER_PORT=->master_port,MASTER_USER='->slave_user',MASTER_PASSWORD='slave_password';master_hostがレプリケーション マスタのホスト名あるいは IP アドレスの場合、master_portはマスタの接続に使用されるスレーブのポートで、slave_userはマスタのスレーブの設定したユーザー名で、slave_passwordは前のステップのユーザーアカウントに設定されたパスワードです。例えば、スレーブにホスト名が 「
rep-masterの MySQL サーバーからレプリケートするよう指示した場合、」 前のステップで作成したレプリケーションのスレーブ アカウントを使用して、以下のステートメントを使用します。mysql
S>CHANGE MASTER TO->MASTER_HOST='rep-master'->MASTER_PORT=3306,->MASTER_USER='myslave'->MASTER_PASSWORD='53cr37';(このステートメントで使用する節の完全なリストは、項12.6.2.1. 「
CHANGE MASTER TO構文」 を参照してください。)スレーブのサーバー
my.cnfファイルの相当する設定オプションを設定してマスタを使用するスレーブを設定することもできます。前述の例CHANGE MASTER TOステートメントと同じようにスレーブを設定するには、スレーブのmy.cnfファイルに以下の情報を含める必要があります。[mysqld] master-host=rep-master master-port=3306 master-user=myslave master-password=53cr37
レプリケーション スレーブに
my.cnfで設定できるその他のオプションについては、項5.1.3. 「レプリケーションのオプションと変数」 を参照してください。注:レプリケーションのバックアップ機能を検証するには、レプリケーションのプロセスを始める前に
ndb-connectstringオプションのスレーブのmy.cnfファイルに追加する必要があります。.詳細は 項14.10.9. 「MySQL Cluster のレプリケーションによるバックアップ」 を参照してください。マスタ クラスタが既に使用されている場合、マスタのバックアップを作成しそれをスレーブにアップロードしてスレーブがマスタに同期する時間を節約することができます。スレーブが MySQL Cluster で稼動している場合には、バックアップを使用して項14.10.9. 「MySQL Cluster のレプリケーションによるバックアップ」 で説明したようにその手順を保存することでこれを実現できます。
ndb-connectstring=
management_host[:port]レプリケーション スレーブで MySQL Cluster を使用していない 場合、レプリケーション マスタのこのコマンドを使用してバックアップを作成できます。
shell
M>mysqldump --master-data=1ダンプ ファイルをスレーブにコピーしてその結果のデータをスレーブにインポートします。この後で、ここに示すように mysql クライアントを使用してデータをダンプファイルからスレーブのデータベースにインポートし、そこでは
dump_fileマスタの mysqldump を使用して生成したファイルの名前で、db_nameはレプリケートされるデータベースの名前です。shell
S>mysql -u root -pdb_name<dump_filemysqldump で使用する完全なオプションのリストは、項7.12. 「mysqldump ? データベースバックアッププログラム」 を参照してください。
このようにデータをスレーブにコピーするには、スレーブがコマンドラインで
--skip-slave-startオプションで起動していることを確認するかあるいはskip-slave-startをスレーブのmy.cnfファイルに入れてマスタへの接続させないようにしてすべてのデータがロードされる前にレプリケーションを始めます。データのローディングが完了したら、次の 2 項で説明するステップに従います。レプリケーション マスタとしての各 MySQL サーバーが一意のサーバーID で設定されているか、バイナリのロギングが有効になっているか、行フォーマットを使用しているか確認します。( 項5.1.2. 「レプリケーション フォーマット」 参照。)これらのオプションはマスタのmysql プロセスを実行する際にマスタのサーバー
my.cnfファイル、あるいはコマンドラインのいずれかに設定できます。後者のオプションの関する情報については、項14.10.6. 「レプリケーションの開始 (シングル レプリケーション チャネル)」 を参照してください。
この項ではシングルのレプリケーション チャネルを使用した MySQL CLuster のレプリケーションに手順に付いて説明します。
このコマンドを発行して MySQL レプリケーション マスタ サーバーを起動します。
shell
M>mysqld --nbdcluster --server-id=id\--log-bin --binlog-format=row &ここでは
idはこのサーバーの一意の ID です (項14.10.2. 「仮定条件と一般要件」 参照)。これによりサーバーの mysqld プロセスが適切なロギング フォーマットを使用してバイナリのロギングを有効にして実行されます。以下の示すように MySQL レプリケーション スレーブ サーバーを起動します。
shell
S>mysqld --ndbcluster --server-id=id&そこでは
idはスレーブ サーバーの一意の ID です。レプリケーション スレーブでロギングを有効にする必要はありません。このコマンドで
--skip-slave-startオプションを使用するか、あるいはレプリケーションを直ぐ始めることを望まないかぎりskip-slave-startをサーバーのmy.cnfファイルに入れる必要があります。このオプションを使用すると、レプリケーションの開始が以下のステップ 4 で説明したように適切なSTART SLAVEステートメントが発行されるまで遅延します。スベーブ サーバーをマスタ サーバーのレプリケーション binlog に同期する必要があります。バイナリのロギングがマスタで事前に実行kされない場合、以下のステートメントをスレーブで実行します。
mysql
S>CHANGE MASTER TO->MASTER_LOG_FILE='',->MASTER_LOG_POS=4;これによりスレーブがマスタのバイナリ ログをログ 開始ポイントから読み込みを開始します。さもなければ ? つまり、バックアップを使用してマスタからデータをローディングするには ? そのような場合の
MASTER_LOG_FILEおよびMASTER_LOG_POSに使用する正しい値の取得に関する情報は項14.10.8. 「MySQL Cluster にフェールオーバーを導入する」 を参照してください。最後に、レプリケーション スレーブの mysql クライアントからコマンドを発行してレプリケーションを適用するようにスレーブに指示する必要があります。
mysql
S>START SLAVE;これによってレプリケーションのデータのスレーブへの転送を始めます。
また次項で説明するような手順で 2 つのレプリケーション チャネルを使用することもできます。これとシングルのレプリケーション チャネルを使用する場合の違いは 項14.10.7. 「2 つのレプリケーション チャネルを使用する」 で説明しています。
さらに完全な例のシナリオでは、2 つのレプリケーション チャネルを使用することで冗長性を提供することによって、1 つのレプリケーション チャネルで考えられる問題を回避できるものと考えています。これには合計 4 台のレプリケーション サーバーが必要で、2 台のマスタ サーバーをマスタ クラスタに、後の 2 台のスレーブ サーバーをスレーブ クラスタに使用します。これからの説明のために、一意の識別子を以下のように割り当てたものとします。
| サーバー ID | 説明 |
| 1 | マスタ - プライマリ レプリケーション チャネル (M) |
| 2 | マスタ - 二次レプリケーション チャネル (M') |
| 3 | スレーブ - プライマリ レプリケーション チャネル (S) |
| 4 | スレーブ - 二次レプリケーション チャネル (S') |
2 つのチャネルでの設定は 1
つのチャネルのレプリケーション
チャネルの設定とそれ程大きく異なりません。最初にプライマリと二次レプリケーション
マスタの mysqld
プロセスは、プライマリおよび二次スレーブの実行に続いて実行します。次に、各スレーブで
START SLAVE
ステートメントを発行シテレプリケーションを始めます。コマンドおよびその発行順序を以下に示します。
プライマリのレプリケーション マスタを起動します。
shell
M>mysqld --ndbcluster --server-id=1 \--log-bin --binlog-format=row &二次レプリケーション マスタを起動します。
shell
M'>mysqld --ndbcluster --server-id=2 \--log-bin --binlog-format=row &プライマリのレプリケーション スレーブ サーバーを起動します。
shell
S>mysqld --ndbcluster --server-id=3 \--skip-slave-start &二次レプリケーション スレーブを起動します。
shell
S'>mysqld --ndbcluster --server-id=4 \--skip-slave-start &最後に、以下に示すようにプライマリ スレーブの
START SLAVEステートメントを実行してプライマリ チャネルでレプリケーションを開始します。mysql
S>START SLAVE;
前述同様、バイナリのロギングをレプリケーション スレーブで有効にする必要はありません。
プライマリのクラスタ レプリケーション プロセスが失敗した場合、二次レプリケーション チャネルに切り替えることができます。この切り替えを行うために必要なステップの手順を以下説明します。
最も最新のグローバル チェックポイント (GCP) の時間の取得.つまり、最も最新のエポックをスレーブ クラスタの
ndb_apply_statusテーブルで決める必要があります。それ以下のクエリで検索できます。mysql
S'>SELECT @latest:=MAX(epoch)->FROM mysql.ndb_apply_status;ステップ 1 で説明したクエリから取得した情報を使用して、マスタ クラスタの
ndb_binlog_indexテーブルから以下のように相当するれレコードを取得します。mysql
M'>SELECT->@file:=SUBSTRING_INDEX(File, '/', -1),->@pos:=Position->FROM mysql.ndb_binlog_index->WHERE epoch > @latest->ORDER BY epoch ASC LIMIT 1;これらはプライマリ レプリケーション チャネルの失敗以来のマスタに保存されたレコードです。ここではステップ 1 で取得した値を表すユーザー変数
@latestを使用しています。勿論、1 つの mysqld インスタンスで別のサーバーのインスタンスに設定されたユーザー変数に直接アクセスすることはできません。これらの値は手動で 2 番目のクエリあるいはアプリケーション コードに 「plugged in」 する必要があります。ここで二次のスレーブ サーバーに以下のクエリを実行して二次のチャネルを同期できます。
mysql
S'>CHANGE MASTER TO->MASTER_LOG_FILE='@file',->MASTER_LOG_POS=@pos;再度ユーザー変数 (この場合は
@fileおよび@pos) を使用してステップ 2 で取得しステップ 3 で適用した値を表します。実際はこれらの値は手動で挿入するか、あるいは使用している両方のサーバーにアクセスするアプリケーション コードを使用します。@fileは'/var/log/mysql/replication-master-bin.00001'などの文字列の値で、SQL あるいはアプリケーション コードで使用されるときに引用される必要があります。しかし、@posで表される値は引用する必要はあり ません。MySQL は通常文字列を番号を変換しようとしますが、この場合は例外です。今二次スレーブ mysqld の適切なコマンドを発行して二次チャネルでレプリケーションを開始できます。
mysql
S'>START SLAVE;
二次のレプリケーション チャネルが利用できるようになったら、プライマリの不具合を調べ問題を解決します。問題の解決にはプライマリ チャネルの問題を正しく見極めた正確な対応が必要です。
その問題が 1
台のサーバーに限定されるのであれば、その不具合は(論理的には)
M から
S'、あるいは
M' から
S
にレプリケートできます。しかし、この件はまだ検証していません。
この項ではバックアップの作成とそのバックアップの MySQL Cluster レプリケーションを使用した保存について説明します。レプリケーション サーバーが以前に説明 (項14.10.5. 「レプリケーションにクラスタを準備する」 およびその直後の項の説明を参照してください) した設定になっていることが前提です。その設定になっている場合、バックアップの作成およびそのバックアップの保存手順は以下のようになります。
バックアップを開始する 2 つの異なる方法があります。
方法 A:
この方法ではレプリケーションのプロセスを開始する前にクラスタのバックアップのプロセスがマスタ サーバーで有効になっている必要があります。これは以下の行を
ndb-connectstring=
management_host[:port]を
my.cnf fileの[MYSQL_CLUSTER]の項に含めること可能で、そこではmanagement_hostはマスタ クラスタのNDBサーバーの IP アドレスあるいはホスト名で、portはマネジメント サーバーのポート番号です。.ポート番号はデフォルトのポート (1186) が使用されていない場合にのみ指定する必要があります。(MySQL Cluster のポートおよびポートの割り当てに関する情報は、項14.3.3. 「マルチ コンピュータの設定」 を参照してください。)この場合、そのバックアップはこのステートメントをレプリケーション マスタで実行することで開始されます。
shell
M>ndb_mgm -e "START BACKUP"方法 B:
my.cnfファイルがマネジメント ホストの場所を指定していない場合、バックアップ プロセスはこの情報をNDBマネジメント クライアントにSTART BACKUPコマンドの一部として渡すことで開始できます。以下のようになります。shell
M>ndb_mgmmanagement_host:port-e "START BACKUP"そこでは
management_hostおよびportはマネジメント サーバーのホスト名およびポート番号です。前に述べたようなシナリオ (項14.10.5. 「レプリケーションにクラスタを準備する」 参照) で、以下のように実行できます。shell
M>ndb_mgm rep-master:1186 -e "START BACKUP"
どの方法の場合でも、未処理のトランザクションがある場合にはそれをバックアップを開始する前に完了し、バックアップの実施中に新たにトランザクションを実施しないようお願いします。
クラスタおバックアップファイルを行に入れるスレーブにコピーします。マスタ クラスタの ndbd プロセスで稼動している各システムはそのシステム上にクラスタのバックアップファイルを持ち、これらのall のファイルは保存の確認をするためにスレーブにコピーされます。バックアップ ファイルは、MySQL および NDB バイナリがそのディレクトリの許可を読む限りスレーブ マネジメント ホストが常駐するコンピュータのどのディレクトリにコピーできます。このように、これらのファイルはディレクトリ
/var/BACKUPS/BACKUP-1にコピーできるものと想定されます。スレーブ クラスタが ndbd プロセス (データ ノード) とマスタとして同じ番号を持つ必要なありませんが、この番号が同じにするように強くお勧めします。レプリケーション プロセスが準備不足で起動しないように、スレーブを
--skip-slave-startオプションで起動することが必要です。データベースをスレーブのレプリケートされるマスタ クラスタのスレーブ クラスタで作成します。重要レプリケートされる各データベースに相当する
CREATE SCHEMAステートメントをスレーブ クラスタの各データ ノードで実行します。MySQL Monitor のこのステートメントを使用してスレーブのクラスタをリセットします。
mysql
S>RESET SLAVE;スレーブの
apply_statusテーブルが保存プロセスを実行する前にレコードを含んでいないことが重要です。スレーブの SQL ステートメントを実行することでこれを実現できます。mysql
S>DELETE FROM mysql.ndb_apply_status;ここで各バックアップ ファイルに対して順番に ndb_restore コマンドを使用してレプリケーション プロセスを開始できます。これらを実行する前に、クラスタのメタデータを保存するには
-mオプションを含めることが必要です。shell
S>ndb_restore -cslave_host:port-nnode-id\-bbackup-id-m -rdirdirはバックアップ ファイルがレプリケーション スレーブの置かれるディレクトリへのパスです。残りのバックアップ ファイルに相当する ndb_restore コマンドに対しては、-mオプションは使用しない でください。マスタ クラスタからバックアップ ファイルがディレクトリ
/var/BACKUPS/BACKUP-1にコピーされる 4 つのデータ ノード (項14.10. 「MySQL Cluster レプリケーション」 の図を参照) に保存するには、スレーブで実行されるコマンドのシーケンスは以下のようになります。shell
S>ndb_restore -c rep-slave:1186 -n 2 -b 1 -m \-r ./VAR/BACKUPS/BACKUP-1shellS>ndb_restore -c rep-slave:1186 -n 3 -b 1 \-r ./VAR/BACKUPS/BACKUP-1shellS>ndb_restore -c rep-slave:1186 -n 4 -b 1 \-r ./VAR/BACKUPS/BACKUP-1shellS>ndb_restore -c rep-slave:1186 -n 5 -b 1 -e \-r ./VAR/BACKUPS/BACKUP-1このコマンドのシーケンスにより最も最新のエポック レコードをスレーブの
ndb_apply_statusテーブルに書き込みます。ここで最も最新のエポックをスレーブの
ndb_binlog_indexテーブルkら取得する必要があります(項14.10.8. 「MySQL Cluster にフェールオーバーを導入する」 の説明参照):mysql
S>SELECT @latest:=MAX(epoch)FROM mysql.ndb_binlog_index;@latestを前のステップで取得したエポック値をとして使用して、以下のクエリを使用してマスタのmysql.ndb_binlog_indexテーブルから正しいバイナリ ログ ファイル@fileの正しい起動位置@posを取得できます。mysql
M>SELECT->@file:=SUBSTRING_INDEX(File, '/', -1),->@pos:=Position->FROM mysql.ndb_binlog_index->WHERE epoch > @latest->ORDER BY epoch ASC LIMIT 1;前のステップで取得下値を使用して、スレーブのmysql クライアントの適切な
CHANGE MASTER TOステートメントを発行できます。mysql
S>CHANGE MASTER TO->MASTER_LOG_FILE='@file',->MASTER_LOG_POS=@pos;スレーブが
binlogファイルがマスタからデータを読み込むどのポイントかを「知って」 いるので、この標準の MySQL ステートメントでスレーブにレプリケーションを開始させることができます。mysql
S>START SLAVE;
バックアップを実行して二次のレプリケーション チャネルで保存するには、これらのステップを繰り返し、適切と思われる場合二次マスタおよびスレーブのホスト名および ID をプライマリのマスタおよびスレーブ レプリケーションに置き換えて、前のステートメントをそれらの上で実行するのみで可能です。
クラスタのバックアップおよびバックアップからのクラスタの保存に関する詳細は、項14.8. 「MySQL Cluster のオンライン バックアップ」 を参照してください。.
前項で説明した多くのプロセスを自動化できます
(項14.10.9. 「MySQL Cluster のレプリケーションによるバックアップ」
参照)。以下の Perl スクリプト
reset-slave.pl
はこの方法に関する例を提供します。
#!/user/bin/perl -w
# file: reset-slave.pl
# Copyright c2005 MySQL AB
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to:
# Free Software Foundation, Inc.
# 59 Temple Place, Suite 330
# Boston, MA 02111-1307 USA
#
# Version 1.1
######################## Includes ###############################
use DBI;
######################## Globals ################################
my $m_host='';
my $m_port='';
my $m_user='';
my $m_pass='';
my $s_host='';
my $s_port='';
my $s_user='';
my $s_pass='';
my $dbhM='';
my $dbhS='';
####################### Sub Prototypes ##########################
sub CollectCommandPromptInfo;
sub ConnectToDatabases;
sub DisconnectFromDatabases;
sub GetSlaveEpoch;
sub GetMasterInfo;
sub UpdateSlave;
######################## Program Main ###########################
CollectCommandPromptInfo;
ConnectToDatabases;
GetSlaveEpoch;
GetMasterInfo;
UpdateSlave;
DisconnectFromDatabases;
################## Collect Command Prompt Info ##################
sub CollectCommandPromptInfo
{
### Check that user has supplied correct number of command line args
die "Usage:\n
reset-slave >master MySQL host< >master MySQL port< \n
>master user< >master pass< >slave MySQL host< \n
>slave MySQL port< >slave user< >slave pass< \n
All 8 arguments must be passed. Use BLANK for NULL passwords\n"
unless @ARGV == 8;
$m_host = $ARGV[0];
$m_port = $ARGV[1];
$m_user = $ARGV[2];
$m_pass = $ARGV[3];
$s_host = $ARGV[4];
$s_port = $ARGV[5];
$s_user = $ARGV[6];
$s_pass = $ARGV[7];
if ($m_pass eq "BLANK") { $m_pass = '';}
if ($s_pass eq "BLANK") { $s_pass = '';}
}
############### Make connections to both databases #############
sub ConnectToDatabases
{
### Connect to both master and slave cluster databases
### Connect to master
$dbhM
= DBI->connect(
"dbi:mysql:database=mysql;host=$m_host;port=$m_port",
"$m_user", "$m_pass")
or die "Can't connect to Master Cluster MySQL process!
Error: $DBI::errstr\n";
### Connect to slave
$dbhS
= DBI->connect(
"dbi:mysql:database=mysql;host=$s_host",
"$s_user", "$s_pass")
or die "Can't connect to Slave Cluster MySQL process!
Error: $DBI::errstr\n";
}
################ Disconnect from both databases ################
sub DisconnectFromDatabases
{
### Disconnect from master
$dbhM->disconnect
or warn " Disconnection failed: $DBI::errstr\n";
### Disconnect from slave
$dbhS->disconnect
or warn " Disconnection failed: $DBI::errstr\n";
}
###################### Find the last good GCI ##################
sub GetSlaveEpoch
{
$sth = $dbhS->prepare("SELECT MAX(epoch)
FROM mysql.ndb_apply_status;")
or die "Error while preparing to select epoch from slave: ",
$dbhS->errstr;
$sth->execute
or die "Selecting epoch from slave error: ", $sth->errstr;
$sth->bind_col (1, \$epoch);
$sth->fetch;
print "\tSlave Epoch = $epoch\n";
$sth->finish;
}
####### Find the position of the last GCI in the binlog ########
sub GetMasterInfo
{
$sth = $dbhM->prepare("SELECT
SUBSTRING_INDEX(File, '/', -1), Position
FROM mysql.ndb_binlog_index
WHERE epoch > $epoch
ORDER BY epoch ASC LIMIT 1;")
or die "Prepare to select from master error: ", $dbhM->errstr;
$sth->execute
or die "Selecting from master error: ", $sth->errstr;
$sth->bind_col (1, \$binlog);
$sth->bind_col (2, \$binpos);
$sth->fetch;
print "\tMaster bin log = $binlog\n";
print "\tMaster Bin Log position = $binpos\n";
$sth->finish;
}
########## Set the slave to process from that location #########
sub UpdateSlave
{
$sth = $dbhS->prepare("CHANGE MASTER TO
MASTER_LOG_FILE='$binlog',
MASTER_LOG_POS=$binpos;")
or die "Prepare to CHANGE MASTER error: ", $dbhS->errstr;
$sth->execute
or die "CHNAGE MASTER on slave error: ", $sth->errstr;
$sth->finish;
print "\tSlave has been updated. You may now start the slave.\n";
}
# end reset-slave.pl
MySQL 5.1.6 では、ディスクの NDB
テーブルの非インデックスのカラムを、以前のバージョンの
MySQL Cluster の RAM
以外に保存できるようになりました。
クラスタ ディスク データの作業の一貫で、ノードのリカバリおよび再起動時に多量(テラ バイト)のデータの取扱い効率を上げるための多くの改善を加えています。これらの改善点の中には非常に大きなデータセットを持つノードの起動の同期する 「no-steal」 アルゴリズムが含まれています。詳細については MySQL Cluster の開発者 Mikael Ronstrom および Jonas Oreland による説明書 Recovery Principles of MySQL Cluster 5.1 を参照してください。
MYSQL 5.1.6 あるいはそれ以降で稼動する MySQL Cluster をすべてのノード (マネジメント および SQL ノードを含む) を設定したと仮定すると、ディスクでクラスタ テーブル作成の基本的なステップは以下のようになります。
log file group を作成し、1つ以上の
UNDOログ ファイルをそれに割り当て (UNDOログ ファイルはUNDOFILEとも言われます) ます。.tablespace を作成し、1 つい上のデータ ファイルおよびログ ファイル グループをそれに割り当てます。
データのストレージにテーブルスペースを使用するあディスク データ テーブルを作成します。
これらの各タスクは以下の例に示すように SQL ステートメントで実行できます。
lg_1の名前のログ ファイル グループをCREATE LOGFILE GROUPを使用して作成します。このログ ファイルのグループは 2 つのUNDOログ ファイルで構成され、それぞれの名前をundo_1.datおよびundo_2.datとし、それらの初期サイズはそれぞれ 16 MB および 12 MB です。(ログ ファイルをログ ファイル グループに追加する際はそれらの初期サイズを指定する必要があります。オプションで、ログ ファイル グループのUNDOバッファのサイズを指定するか、デフォルト値の 8 MB のまま使用することもできます。この例では、UNDO バッファのサイズを 2 MB にしています。UNDOログ ファイルと一緒にログ ファイルのグループを作成する必要があります。ここではundo_1.datをlg_1にこのCREATE LOGFILE GROUPステートメントで追加します。CREATE LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_1.dat' INITIAL_SIZE 16M UNDO_BUFFER_SIZE 2M ENGINE NDB;undo_2.datをログ ファイルのグループに追加するには、以下のALTER LOGFILE GROUPステートメントを使用します。ALTER LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_2.dat' INITIAL_SIZE 12M ENGINE NDB;いくつかの項目に関する備考
ここで使用されている
.datのファイル拡張は必要ありません。ここで使用しているのはログおよびデータ ファイルが分かり易いように使用しているだけです。すべての
CREATE LOGFILE GROUPおよびALTER LOGFILE GROUPステートメントにはENGINE節を含める必要があります。MySQL 5.1 では、この節に許可された値はNDBおよびNDBCLUSTERです。重要MySQL 5.1.8 およびそれ以降では、所定の時間ではログ ファイル グループは 1 つだけです。
UNDOログ ファイルをログ ファイル グループにADD UNDOFILE 'を使用して追加するときに、filename'filenameの名前のファイルがクラスタの各データ ノードのData Directoryのndb_ディレクトリで作成されます。そこではnodeid_fsnodeidはデータ ノードのノード ID です。UNDO_BUFFER_SIZEは利用できるシステム メモリの容量によって制限されます。CREATE LOGFILE GROUPステートメントの詳細に関しては 項12.1.9. 「CREATE LOGFILE GROUP構文」 を参照してください。.ALTER LOGFILE GROUPの詳細は、 項12.1.3. 「ALTER LOGFILE GROUP構文」 を参照してください。
ここでテーブルスペースを作成します。テーブルスペースは MySQL Cluster ディスク データ テーブルで使用されるそれらのデータを保存するファイルを含みます。テーブルスペースは特定のログ ファイルのグループに関連付けられています。新たにテーブルスペースを作成する際は、
UNDOロギングで使用されるログ ファイルのグループを指定する必要があります。データ ファイルも指定する必要があります。テーブルスペースを作成した後にさらにテーブルスペースを追加することもできます。データスペースからデータ ファイルを削除することもできます (データ ファイルの削除の例はこの項で後ほど提供します)。ts_1の名前でlg_1でログ ファイルのグループとして使用されるテーブルスペースを作成するものとします。このテーブルスペースは 2 つのデータ ファイルdata_1.datおよびdata_2.datを含むものとし、それぞれの初期のサイズをそれぞれ 32 MB および 48 MB とします。これを 2 つの SQL ステートメントを使用して行います。CREATE TABLESPACE、ts_1をデータ ファイルdata_1.datで作成し、ts_1をログ ファイル グループlg_1に関連付けし、ALTER TABLESPACEは 2 番目のデータ ファイルを追加します。以下のこれらのステートメントを示します。CREATE TABLESPACE ts_1 ADD DATAFILE 'data_1.dat' USE LOGFILE GROUP lg_1 INITIAL_SIZE 32M ENGINE NDB; ALTER TABLESPACE ts_1 ADD DATAFILE 'data_2.dat' INITIAL_SIZE 48M ENGINE NDB;いくつかの項目に関する備考
ここで
UNDOログ ファイルに使用されたファイル名の場合と同様、.datファイル拡張の特別な重要性はありません。分かり易くするためにのみ使用しています。すべての
CREATE TABLESPACEおよびALTER TABLESPACEステートメントはENGINE節を含む必要があり、テーブルスペースと同じストレージ エンジンを使用しているテーブルのみがテーブルスペースで作成されます。MySQL 5.1 では、この節に許可された値はNDBおよびNDBCLUSTERだけです。CREATE TABLESPACEおよびALTER TABLESPACEステートメントに関する詳細は、 項12.1.10. 「CREATE TABLESPACE構文」 、および 項12.1.4. 「ALTER TABLESPACE構文」 を参照してください。
ここで非インデックスのカラムがテーブルスペース
ts_1のディスクの保存されるテーブルを作成できます。CREATE TABLE dt_1 ( member_id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, last_name VARCHAR(50) NOT NULL, first_name VARCHAR(50) NOT NULL, dob DATE NOT NULL, joined DATE NOT NULL, INDEX(last_name, first_name) ) TABLESPACE ts_1 STORAGE DISK ENGINE NDB;TABLESPACE ...STORAGE DISK節がNDB Clusterストレージ エンジンにテーブルスペースts_1をディスク データ ストレージに使用するよう指示します。以下のようにテーブル
ts_1が以下のように作成されたら、他の MySQL テーブルでするようにINSERT、SELECT、UPDATE、およびDELETEステートメントを実行できます。テーブル
dt_1にはここで定義されたように、dobおよびjoinedカラムのみがディスクに保存できます。これはidにインデックスがあるからで、last_name、およびfirst_nameカラム、並びにこれらのカラムに所属するが RAM に保存されます。MySQL 5.1 では、非インデックスカラムのみがディスクの保存されます。インデックスおよびインデックスの付いたカラムはメモリに保存されます。このインデックスと RAM の保存間の兼ね合いはディスク データ テーブルを設計する際に忘れてはならないものです。重要MySQL 5.1 のディスク データ テーブルには、変数長カラムがある一定のスペースを使用します。各行では、そのカラムの一番大きな値を保存するのに必要なスペースに相当します。(これらの計算に関するヘルプに関しては、項10.5. 「データタイプが必要とする記憶容量」 を参照してください。)
注:クラスタを
--initialオプションで起動するとディスク データ ファイルは削除されません。クラスタを最初の再起動を実行するときに手動でそうする必要があります。
これらを使用しているログ ファイル グループ、テーブルスペース、およびディスク データ テーブルは特別な順序で作成する必要があります。これらのオブジェクトを削除する際も同様です。
ログ ファイル グループはテーブルスペースがそれを使用しいる場合は削除できません。
テーブルスペースはそれがデータ ファイルを含んでいる場合には削除できません。
テーブルスペースを使用しているテーブルが残っている限りテーブルスペースからデータ ファイルを削除することはできません。
MySQL 5.1.12 以降では、ファイルが作成されたもの以外の異なるテーブルスペースに関連して作成されたファイルは削除できなくなりました。(Bug#20053)
例えば、この項でこれまで作成してきたすべてのオブジェクトを削除するには、以下のステートメントを使用します。
mysql>DROP TABLE dt_1;mysql>ALTER TABLESPACE ts_1->DROP DATAFILE 'data_2.dat'->ENGINE NDB;mysql>ALTER TABLESPACE ts_1->DROP DATAFILE 'data_1.dat'->ENGINE NDB;mysql>DROP TABLESPACE ts_1->ENGINE NDB;mysql>DROP LOGFILE GROUP lg_1->ENGINE NDB;
これらのステートメントは表示された順序で実行する必要があります。ALTER
TABLESPACE ...DROP DATAFILE のこの 2
つのステートメントはどちらの順序でも実行できる場合があります。
INFOMATION_SCHEMA データベースで
FILES
テーブルにクエリしてディスク データ
テーブルに使用されるデータ
ファイルに関する情報を取得できます。undo ログ
ファイルに関する情報を提供するために特別な
「NULL 行」 が MySQL 5.1.14
に追加されています。使用例に関する詳細は、
項21.21. 「INFORMATION_SCHEMA FILES テーブル」 を参照してください。.
パラメータの設定により以下を含むディスク データ の振る舞いに影響を及ぼします。
DiskPageBufferMemoryこれによりディスクのキャッシュ ページに使用されるスペースを決め、
config.iniファイルの[NDBD]あるいは[NDBD DEFAULT]セクションに設定されます。そのスペースはバイトで測定されます。各ページは 32k です。このことはNが負の整数以外の場合、クラスタ デスク データ ストレージは常にN* 32k メモリを使用することを意味します。SharedGlobalMemoryこれはログ バッファに使用されるメモリ容量、ディスク オペレーション(ページ リクエストおよび待ちキューなど)、およびテーブルスペースのメタデータ、ログ ファイル グループ、
UNDOファイル、ならびにデータ ファイルを決めます。それはconfig.ini設定ファイルの[NDBD]あるいは[NDBD DEFAULT]セクションで設定され、バイトで測定されます。
注:OPTIMIZE
TABLE ステートメントはディスク データ
テーブルには影響を及ぼしません。
1996 年に NDB Cluster
の設計を始める以前から既に、ネットワークのノード間の通信が並列のデータベースの構築で問題になるだろうということは明らかになっていました。このため、NDB
Cluster
が多くの異なるデータ転送メカニズムに使用するためにその初期の段階から設計されました。本マニュアルでは、これらの用語に
transporter を使用しています。
MySQL Cluster のコードベースでは 4 つの異なるトランスポーターをサポートしています。
TCP/IP は 100 Mbps あるいはギガ バイト Ethernet を 項14.4.4.7. 「Cluster TCP/IP Connections」 の説明にあるように使用しています。
直接 (マシン対マシン) TCP/IP、このトランスポーターは同じ TCP/IP プロトコルを以前説明したアイテムと使用していますが、ハードウェアの設定を別にし設定も同様に変える必要があります。このため、それは MySQL Cluster の個別の転送メカニズムと考えられています。詳細は 項14.4.4.8. 「直接接続を使用した TCP/IP の接続」 を参照してください。
共有メモリ (SHM)。SHM に関する情報は、項14.4.4.9. 「共有メモリ接続」 を参照してください。
スケーラブル コヒーラント インターフェース (SCI)、本章の次項、項14.4.4.10. 「SCI トランスポート接続」 で説明します。
多くのユーザーはそれがユビキタスであるため現在 TCP/IP を Ethernet で使用しています。TCP/IP はまたこれまで MySQL Cluster での使用に於いては最も検証されたトランスポーターです。
ndbd プロセスによる通信を 「chunks」 でできるように現在準備しています。これができるようになるとすべてのデータ 転送に恩恵を齎します。
ユーザーが希望されるのであれば、クラスタのインターコネクトを使用してパフォーマンスをより向上させることも可能です。これを実現する 2 つの方法があります。カスタムのトランスポーターをこれに使用できるように設計するか、あるいは TCP/IP スタックを拡張できるようにバイパスするソケットを使用することによって実現できます。弊社では Dolphin 社が開発した SCI (スケーラブル コヒーラント インターフェース) テクノロジを使用してこの 2 つのテクノロジを実験しました。
この項では、クラスタを通常の TCP/IP 通信に SCI ソケットを使用できるようにするために設定について説明します。この説明は 2004 年 10 月 1 日現在の SCI Socket バージョン 2.3.0 に基づいています。
必要条件
SCI ソケットを使用するマシンは SCI カード実装が必要です。
SCI ソケットはどのバージョンの MySQL Cluster でも使用できます。それは既に MySQL Cluster で利用できる通常のソケット呼び出しを使用していますので特別な構築は必要ありません。しかし、SCI Soket は現在 Linux 2.4 および 2.6 kernels 上でしかサポートされていません。SCI トランスポーターはその他のオペレーティング システムでも検証されていますが今までのところ弊社では Linux 2.4 でしかこれらの検証を行っておりません。
これらは SCI Socket の使用する際の基本的な要件です。
SCI Socket ライブラリの構築。
SCI Socket kernel ライブラリのインストール。
1 つ以上の設定ファイルのインストール。
SCI Socket kernel ライブラリはマシン全体あるいは MySQL Cluster プロセスが実行されるシェルのいずれかに有効でなければなりません。
このプロセスは SCI Socket をインターノード通信に使用する際のクラスタの各マシンに繰返されます。
SCI Socket を動作させるには 2 つのパッケージを取り出す必要があります。
SCI Socket ライブラリの DIS サポート ライブラリを含むソースコード パッケージ。
SCI Socket ライブラリそのもののソースコード パッケージ
現在は、これらはソースコードのフォーマットでしか利用できません。本マニュアルを書いている段階でのこれらのパッケージの最新のバージョンは
(それぞれ)
DIS_GPL_2_5_0_SEP_10_2004.tar.gz および
SCI_SOCKET_2_3_0_OKT_01_2004.tar.gz
が利用できました。これらは
(または最新バージョン) は
http://www.dolphinics.no/support/downloads.html
で入手できます。
パッケージのインストール
これらのライブラリのパッケージを入手したら、以下のステップでそれらを適切なディレクトリに解凍し、そこで SCI Socket ライブラリを DIS コードの下のディレクトリに入れます。次に、ライブラリを構築する必要があります。この例ではこのタスクを実行するための Linux/x86 でのコマンドを示します。
shell>tar xzf DIS_GPL_2_5_0_SEP_10_2004.tar.gzshell>cd DIS_GPL_2_5_0_SEP_10_2004/src/shell>tar xzf ../../SCI_SOCKET_2_3_0_OKT_01_2004.tar.gzshell>cd ../adm/bin/Linux_pkgsshell>./make_PSB_66_release
これらの ライブラリを 64 ビットのプロセッサに構築できます。64 ビット拡張を使用してライブラリを Opteron CPU に構築するには、make_PSB_66_X86_64_release を実行します。make_PSB_66_release ではありません。それを Itanium マシンに構築した場合には、 make_PSB_66_IA64_release を使用する必要があります。X86-64 バリアントは Intel EM64T アーキテクチャで動作しますが、これはまだ (弊社の知っている限り) まだ検証されていません。
構築が完了したら、コンパイルしたライブラリは
zip の tar ファイルで
DIS-
の名前で検索できます。ここでパッケージを適切なスペースにインストールします。この例ではインストールを
<operating-system>-time-date/opt/DIS
に入れます。(注:多くの場合以下をシステム
root
ユーザーとして実行する必要があります。)
shell>cp DIS_Linux_2.4.20-8_181004.tar.gz /opt/shell>cd /optshell>tar xzf DIS_Linux_2.4.20-8_181004.tar.gzshell>mv DIS_Linux_2.4.20-8_181004 DIS
ネットワークの設定
すべてのライブラリおよびバイナリが準備できたら、SCI カードが SCI アドレス スペースで適切なノード ID を持っているか確認する必要があります。
次に進む前にネットワーク構成で決める必要があります。これ例で使用できるネットワーク構成は 3 種類あります。
簡単な一次元リング
スイッチ ポートと毎に 1 つのリングを持つ 1 つ以上の SCI スイッチ
2 あるいは 3次元トーラス
これらの各トポロジにはノード ID を提供するそれぞれの手法があります。簡単にそれぞれについて説明します。
簡単なリングは非ーゼロの 4 の倍数を使用します。 4, 8, 12,...
次の例は SCI スイッチを使用しています。SCI スイッチには 8 ポートあり、それぞれのポートはリングをサポートします。異なるリングは異なるノード ID スペースを使用することを確認する必要があります。一般的な設定では、最初のポートは 64 (4 ? 60) 以下のノード ID を使用し、次の 64 ノード ID (68 ? 124) は次のポートに割り当てられ、そのように続いてノード ID 452 ? 508 は 8 番目のポートに割り当てられます。
2、3 次元のトーラス ネットワーク構成は各ノードは各次元のどこに配置され、最初の次元で各ノードを 4 で増分し、2 次元では 64、および (適用できる場合) 3 次元では 1024 で増分します。さらに詳しい説明については Dolphin 社のウェブ サイト を参照してください。
弊社の試験ではスイッチを使用しました。大きなクラスタのインストールでは 2 あるいは 3 次元のローラス構成を使用します。スイッチを使用する利点は、2 つの SCI および 2 つのスイッチでは、比較的容易に冗長ネットワークを構築でき、そこでは SCI ネットワークの標準フェールオーバー時間は 一般的に100 ミリセカンドです。これは MySQL Cluster の SCI トランスポーターでサポートされており、現在 SCI Socket に導入するために開発中です。
2D/3D トーラスでのファールオーバーは可能ですがすべてのノードに対して新しいルート インデックスを送る必要があります。しかし、これには それを完了するには 100 ミリセカンドあるいはそれくらいが必要で、多くの高可用性を要求されるケースで使用せきなればなりません。
クラスタのデータ ノードをスイッチのアーキテクチャに適切に配置することで、2 つのスイッチを使用して 16 台のコンピュータをインターコネクトし 1 つの不具合が他の 1 つ以上に影響を及ぼさない構成を構築できます。32 台のコンピュータと 2 つのスイッチで、1 つの不具合が 2 つい上のノードの損失につながらないようにクラスタを設定することができます。この場合、その組のノードが影響されたかを知ることも可能です。このように、2 つのノードを個別のノード グループに配置することで、「安全な」 MySQL Cluster のインストールを構築できます。
ノード ID を SCI カードに設定するには
/opt/DIS/sbin
ディレクトリの以下のコマンドを使用します。この例では、-c
1 は SCI カード (これはマシンにカードが
1 つだけの場合には常に 1 です)
の番号を表し、-a 0 はアダプタ
0、および 68 はノード ID
を意味します。
shell> ./sciconfig -c 1 -a 0 -n 68
同じマシンに複数の SCI
カードがある場合、以下のコマンド
(ここでは使用するディレクトリを
/opt/DIS/sbin とします)
を発行することでどのカードにどのスロットがあるか決めることができます。
shell> ./sciconfig -c 1 -gsn
これにより SCI
カードのシリアル番号が決まります。次にマシンの各カードにこのプロシージャを
-c 2
などで繰り返します。各カードをスロットに合わせたら、ノード
ID をすべてのカードに設定できます。
必要なライブラリおよびバイナリをインストールすると、SCI
ノードと ID
が設定され、次のステップでホスト名(あるいは
IP アドレス) から SCI ノード ID
のマッピングを設定します。これは SCI Socket
の設定ファイルで行われ、/etc/sci/scisock.conf
として保存します。このファイルで、各 SCI
ノード ID は適切な SCI
カードから通信するホスト名あるいは IP
アドレスにマップされます。ここにその様な設定ファイルの極めて簡単な例を示します。
#host #nodeId alpha 8 beta 12 192.168.10.20 16
設定をこれらのホストの利用できるポートのサブセットにのみ適用できるように制限することも可能です。これを行うために別の設定ファイル
/etc/sci/scisock_opt.conf
を以下のように使用できます。
#-key -type -values EnablePortsByDefault yes EnablePort tcp 2200 DisablePort tcp 2201 EnablePortRange tcp 2202 2219 DisablePortRange tcp 2220 2231
ドライバのインストール
設定ファイルの用意ができたら、ドライバをインストールできます。
最初に、低レベルのドライバ、次に SCI ソケット ドライバをインストールする必要があります。
shell>cd DIS/sbin/shell>./drv-install add PSB66shell>./scisocket-install add
任意で、SCI ソケットの設定ファイルのすべてのノードがアクセスできることを検証するスクリプトを実行してインストールをチェックできます。
shell>cd /opt/DIS/sbin/shell>./status.sh
エラーが発生し SCI ソケットの設定の変更が必要な場合、このタスクを実行するためには ksocketconfig を使用する必要があります。
shell>cd /opt/DIS/utilshell>./ksocketconfig -f
設定テスト
SCI
ソケットが実際に使用されているか確認するには、latency_bench
テスト
プログラムを使用します。このユーティリティのサーバーコンポーネントを使用して、接続のレーテンシーをテストするためにサーバーに接続できます。SCI
が有効であるかを確認するにはこのレーテンシーを確認することで用意に分かります。(注:latency_bench
を使用する前に、LD_PRELOAD
環境変数をこの項の後で述べるように設定する必要があります。
サーバーを設定するには、以下を使用します。
shell>cd /opt/DIS/bin/socketshell>./latency_bench -server
クライアントを起動するには、latency_bench
を、この場合は -client
オプションを除いて再度使用します。
shell>cd /opt/DIS/bin/socketshell>./latency_bench -clientserver_hostname
SCI ソケットの設定はこれで完了し、MySQL Cluster の SCI ソケット および SCI トランスポート (項14.4.4.10. 「SCI トランスポート接続」 参照) を使用する用意ができました。
クラスタの起動
プロセスの次のステップで MySQL Cluster
が起動します。SCI
ソケットの使用を有効にするには、環境変数
LD_PRELOAD を
ndbd、mysqld、および
ndb_mgmd
を実行する前に設定します。.この変数は SCI
ソケットの kernel
ライブラリに向ける必要があります。
ndbd をバッシュ シェルで起動するには、以下に従います。
bash-shell>export LD_PRELOAD=/opt/DIS/lib/libkscisock.sobash-shell>ndbd
tcsh 環境では、以下で同様のことが出来ます。
tcsh-shell>setenv LD_PRELOAD=/opt/DIS/lib/libkscisock.sotcsh-shell>ndbd
注:MySQL Cluster は SCI ソケットの kernel 派生品のみ使用できます。
ndbd プロセスには多くの簡単な構成があり、MySQL Cluster のアクセスに使用します。それらのパフォーマンスおよび様々なインターコネクトがそのパフォーマンスに及ぼす影響をチェックする簡単なベンチマークを作成しました。
4 つのアクセス方法があります。
プライマリ キーアクセス
これはレコードのそのプライマリ キーによるアクセスです。最も簡単なケースでは、一度に 1 つのレコードのみによるアクセスさせます。それによって 多くのTCP/IP のメッセージの設定の全コストおよびスイッチングのコンテキストの多くのコストはこの 1 つのリクエストから生じます。この場合複数のプライマリ キーのアクセスは 1 回のバッチで送られ、それらのアクセスは TCP/IP メッセージの必要な設定およびスイッチのコンテキストに要する費用を分担します。TCP/IP メッセージのディスティネーションが異なる場合、新たに TCP/IP メッセージを設定する必要があります。
一意のキーアクセス
一意のキーアクセスは一意のキーアクセスはテーブルのプライマリ キーアクセスに続くインデックス テーブルの読み込みとして実行され以外はプライマリ キーアクセスに類似しています。しかし、MySQL サーバーからはリクエストが 1 つだけ送られ、インデックス テーブルの読み込みは ndbd によって処理されます。それらのリクエストはバッチにより恩恵を受けます。
テーブルの完全スキャン
テーブルのルックアップにインデックスが存在しない場合、テーブルの完全スキャンを実施します。これは 1 つのリクエストとして ndbd プロセスに送られ、そこでテーブルスキャンをすべてのクラスタ ndbd プロセスの一連の並列スキャンに分割します。将来的には MySQL Cluster のバージョン、SQL ノードはこれらのスキャンのいくつかをフィルタできるようになります。
順序付けされたインデックスを仕様したレンジ スキャン
順序付けされたインデックスを使用すると、SQL サーバー(SQL ノード) により転送されたクエリの範囲にあるそれらのレコードのみをスキャンする以外は、全なテーブルのスキャンと同様にスキャンを実施します。すべての結合した属性がパーティッション キーのすべての属性を含む場合パーティッションは並列でスキャンされます。
これらのアクセス方法の基本的なパフォーマンスをチェックするために、一連のベンチマークを開発しました。そのようなベンチマークの一つは、testReadPerf、でn簡単なバッチのプライマリおよび一意のキーアクセスをテストします。このベンチマークはまた 1 つのレコードを返すスキャンを発行することで範囲スキャンの設定コストを測定します。範囲スキャンを使用してレコードのバッチを取り出すこのベンチマークの派生版もあります。
この様に、基本となるアクセス方法で、使用している通信メディアの影響を測定するばかりでなく、1 つのキーアクセスおよび 1 つのレコードスキャン アクセスの両方のコストを決定できます。
弊社のテストでは、これらのベンチマークを TCP/IP ソケットを使用した通常のトランスポーターおよび SCI ソケットを使用した類似の設定の両方に使用しています。以下テーブルのレポートした図はアクセス毎に 20 レコードの小さなアクセスに使用します。シリアルおよびバッチのアクセスは 2KB のレコードを使用した場合 3 と 4 の因数が減少します。SCI ソケットは 2KB レコードでテストしていません。テストは AMD 社の MP1900+ プロセッサを搭載した 2 つのデュアル CPU マシン上で動作する 1 つのクラスタに 2 つのデータ ノードで実行しました。
| アクセス タイプ | TCP/IP ソケット | SCI ソケット |
| シリアル pk アクセス | 400 マイクロセカンド | 160 マイクロセカンド |
| バッチ pk アクセス | 28 マイクロセカンド | 22 マイクロセカンド |
| シルアル uk アクセス | 500 マイクロセカンド | 250 マイクロセカンド |
| バッチuk アクセス | 70 マイクロセカンド | 36 マイクロセカンド |
| インデックス eq-バウンド | 1250 マイクロセカンド | 750 マイクロセカンド |
| インデックス レンジ | 24 マイクロセカンド | 12 マイクロセカンド |
SCI ソケット vis-a-vis と SCI トランスポーターのパフォーマンス、およびこれら両方を TCP/IP トランスポーターと比較したパフォーマンスをチェックしました。これらすべてのテストにはプライマリ キーアクセスをシリアルおよび複数のスレッド、あるいは複数のスレッドおよびバッチのいずれかに使用しました。
このテストでは SCI ソケットが TCP/IP よりもおよそ 100% 早いことが分かりました。SCI トランスポーターは SCI ソケットに比べると殆どのケースで速くなっています。テスト プログラムの多くのスレッドで注目すべきことが発生した。それは SCI トランスポーターは mysqld プロセスに使用した場合あまりよい結果を示しませんでした。
全体的な結論としては、通信のパフォーマンスが懸案でないときの珍しいインスタンスを除いて、ほとんどのベンチマークで、SCl ソケットは TCP/IP に対しておよそ 100% パフォーマンスを改善することです。これはスキャンのフィルタが殆どのプロセス時間を使った場合あるいはプライマリ きーの非常に大きなバッチ アクセスが達成されたときに起こります。その様な場合、ndbd プロセスの CPU の処理がオーバーヘッドのかなり大きな部分になります。
SCI ソケットの代わりに SCI トランスポートを使用するには、ndbd プロセス間の通信の端に興味によるものです。SCI トランスポーターを使用するのも単なる興味からで、SCl トランスポーターがこのプロセスが決して停止しないことを確認するため、CPU を ndbd プロセスに専用にできるかとの単なる興味からのものです。ndbd プロセスの優先権がプロセスが、Linux 2.6 でプロセスをロックできるように、時間を延長して実行されても優先権がなくならないように設定されているか確認する必要があります。そのような設定が可能な場合、ndbd プロセスは SCI ソケットを使用した場合に比べて 10?70% 恩恵があることになります。(更新および並列スキャンのオペレーションでは大きな数字になります。)
コンピュータのクラスタに Myrinet、ギガビット Ethernet、Infiniband および VIA インターフェースなど他にもいくつかの最適化ソケットの実装があります。これまでに MySQL Cluster を SCI ソケットだけでしかテストしていません。通常の TCP/IP を MySQL Cluster 使用した SCI ソケットの設定方法については、項14.12.1. 「SCI ソケットを使用するための MySQL Cluster の設定」 を参照してください。
この項では、MySQL Cluster の 5.1.x
シリーズのリリースの MyISAM および
InnoDB ストレージ
エンジンを使用した際に利用できる機能との比較における既知の制限のリストを提供します。現在、これからリリースされる
MySQL 5.1
でこれらを試す計画はありません。しかし、今後のリリースではこれらの問題で解決されたことを提供するつもりです。「Cluster」
カテゴリを http://bugs.mysql.com の MySQL
バグ データベースでチェックすると、MySQL
5.1
の今後のリリースで修正する既知のバグ
(「5.1」 の印の)
を検索できます。
ここに掲げるリストは以下の条件で完成する予定です。何か齟齬があった場合には 項1.7. 「質問またはバグの報告」 の指示に従って MySQL バグ データベースにレポートできます。その問題を MySQL 5.1 で修正しない場合には、それをリストに追加します。
(注:現在のバージョンで解決された MySQL 5.0 Cluster の問題のリストについてはこの項の末尾を参照してください。
MySQL Cluster のレプリケーションに特定の制限とその他の問題に関しては、項14.10.3. 「既知の問題」 の説明を参照してください。
構文の不承諾 (既存のアプリケーションを実行中のエラーによる):
テンポラリ テーブルはサポートしていません。
テキスト インデックスはサポートしていません。つまり、
TEXTデータベースのカラムにはインデックスを作成できません。またNDBストレージ エンジンはFULLTEXTインデックス (これらはMyISAMのみサポートしています。) をサポートしていません。しかし、NDBテーブルのVARCHARカラムはインデックスできます。A
BITカラムはプライマリ キー、インデックスにはできません。またコンポジットのプライマリ キー、一意のキー、あるいはインデックスの一部を構成することもできません。ジオメトリーデータ タイプは (
WKTおよびWKB) はMySQL のNDBテーブルでサポートされています。5.1.しかし、スペーシャル インデックスはサポートされていません。CREATE TABLEステートメントは 4096 文字以内です。この制限は MySQL 5.1.6、5.1.7、および 5.1.8 のみに影響を及ぼします。.(See Bug#17813)MySQL 5.1.7 およびそれ以前では、
INSERT IGNORE、UPDATE IGNORE、およびREPLACEはプライマリ キーのみサポートしており、一意のキーはサポートしていません。この制約を外す一つの解決策は一意のインデックスを削除し、挿入を実行し、次に一意のインデックスを再度追加することです。この制限は MySQL 5.1.8 の
INSERT IGNOREおよびREPLACEには削除されています (Bug#17431)。MySQL 5.1 の MySQL Cluster のユーザー定義のパーティショニングのサポートは [
LINEAR]KEYパーティショニングに制限されています。MySQL 5.1.12 以降では、他のパーティショニング タイプをCREATE TABLEのENGINE=NDBあるいはENGINE=NDBSLUSTERステートメントで使用するとエラーになります。MySQL 5.1.6 では、デフォルトでテーブルのプライマリ キーをパーティショニング キーとして使用して
KEYによってパーティションされています。プライマリ キーが明示的にテーブルに設定されていない場合、代わりにNDBストレージ エンジンによって自動的に作成された 「非表示」 のプライマリ キーが使用されます。これらの説明およびf関する問題に関しては、 項15.2.4. 「KEY分割」 を参照してください。NDBテーブルからALTER TABLE ...DROP PARTITIONを使用してパーティションを削除することはできません。ALTER TABLE?ADD PARTITION、REORGANIZE PARTITION、およびCOALESCE PARTITION? への他のパーティションの拡張はクラスタ テーブルにはサポートされていますが、コピーなどの使用は最適化できません。 項15.3.1. 「RANGEとLISTパーティションの管理」 および 項12.1.2. 「ALTER TABLE構文」 を参照してください。行ベースのレプリケーションを MySQL Cluster で使用する場合、バイナリのロギングは無効にできません。つまり、
NDBストレージ エンジンはSQL_LOG_BINの値を無視します。(Bug#16680)auto_increment_incrementおよびauto_increment_offsetサーバーシステムの変数はクラスタのレプリケーションをサポートしていません。
制限あるいは振る舞いの不承認 (既存のアプリケーションを実行した場合エラーになる場合があります。):
メモリの使用:
データが
NDBテーブルに挿入された際に使用されたメモリは他のストレージ エンジン同様削除されても自動的元に戻りません。代わりに以下の規則が適用されます。NDBテーブルのDELETEステートメントは削除された行で公式に使用されたメモリを同じテーブルに挿入に対してのみ再利用できるようにします。メモリは他のNDBテーブルでは使用できません。NDBテーブルのDROP TABLEあるいはTRUNCATEオペレーションはこのテーブルで使用されたメモリをNDBテーブル ? を同じテーブルあるいは別のNDBテーブルのいずれかで使用できるようにします。(
TRUNCATEはテーブルを削除して再度作成するこを思い出してください項12.2.9. 「TRUNCATE構文」 参照。)DELETEオペレーションで使用できるようになったがそれでも特定のテーブルに割り当てられているメモリはクラスタのローリング再起動を実行することで一般的に再度使用できるようになります。項14.5.1. 「クラスタのローリング再起動の実行」 参照。
エラーの報告:
キーエラー2 回でエラーメッセージ ERROR 23000 が返されます。:書き込みできません。キーを
tbl_name' で.他の MySQL ストレージ エンジン同様、
NDBストレージ エンジンは最大のAUTO_INCREMENTカラムをテーブル毎に扱います。しかし、明示のプライマリ キーのないクラスタ テーブルの場合、AUTO_INCREMENTカラムは自動的に定義され 「非表示」 のプライマリ キーとして使用されます。このため、AUTO_INCREMENTカラムを持つテーブルはカラムもまたPRIMARY KEYオプションを使用して宣言されない限りテーブルを定義することはできません。テーブルのプライマリ キーではない
AUTO_INCREMENTカラムのテーブルを作成しようとしてNDBストレージ エンジンを使用すると、エラーになり失敗します。
トランザクションの取扱い:
NDB ClusterはREAD COMMITTEDトランザクションの分離レベルのみサポートします。トランザクションの部分的なロールバックはありません。複製キーおよび同様のエラーはトランザクション全体のロールバックにつながります。
重要クラスタ テーブルの
SELECTがBLOBあるいはTEXTカラムを含む場合、READ COMMITTEDトランザクションの分離は読み込みロックで読み込みに変換されます。これはこれらのタイプのカラムに保存された値の一部は実際は個別のテーブルから読まれるので一貫性を保証するために行われます。本章で気付かれたことと思いますが、MySQL Cluster は大きなトランザクションの取扱いは得意ではありません。非常にたくさんのオペレーションを含む 1 つの大きなトランザクションを扱うよりはオペレーションの数が少ない多くの小さなトランザクションの扱いに向いています。
とりわけ、大きなトランザクションは非常に大きなメモリを必要とします。このため、多くのMySQL ステートメントのトランザクションの振る舞いが以下のリストで説明するように影響を受けます。
TRUNCATEはNDBテーブルで使用するとトランザクションを行いません。TRUNCATEがテーブルを空に出来ない場合、成功するまで続ける必要があります。DELETE FROM(WHERE節がない場合でも) はトランザクションできます。非常に多くの行を含むテーブルの場合、いくつかのDELETE FROM ...LIMIT ...ステートメントを使用して削除操作を 「チャンク」 することでパフォーマンスが改善する場合があります。テーブルを空にしたい場合には、代わりにTRUNCATEを使用します。TRUNCATEはNDBテーブルで使用するとトランザクションを行いません。そのようなオペレーション中には、NDBエンジンは指示に従って実行されます。LOAD DATA FROM MASTERは MySQL Cluster ではサポートされていません。テーブルを
ALTER TABLEの一部としてコピーする場合、コピーの作成は非トランザクションです。(いぞれの場合も、このオペレーションはコピーが削除されるとロールバックします。)
ノードの起動、停止、あるいは再起動:ノードの起動、停止、あるいは再起動によってトランザクションの失敗につながるテンポラリのエラーが増える場合があります。これらには以下のケースが含まれます。
最初にノードを起動する場合、エラー 1204 のテンポラリな不具合、配布の変更、 および類似のテンポラリ エラーが表示される場合があります。
データ ノードの停止あるいは不具合によって多くの異なるノード不具合エラーにつながる場合があります。(しかし、クラスタの予定したシャットダウンを実行中にはトランザクションの中断はありません。)
これらのいずれのケースの場合にも、生成されたエラーはアプリケーション内で処理する必要があります。トランザクションを再試行することによって行われます。
設定可能な多くのハードの制限がありまが、クラスタの設定制限のメインメモリで利用できます。項14.4.4. 「設定ファイル」 の設定パラメータの完全なリストを参照してください。多くの設定パラメータはオンラインで更新できます。これらのハードの制限には以下が含まれます。
データベースのメモリ サイズとインデックスのメモリ サイズ (
DataMemoryおよびIndexMemory、それぞれ)。DataMemoryには 32KB ページが割り当てられています。各DataMemoryページが使用されると、それは特定のテーブルに割り当てられます。一度割り当てられるとこのメモリはテーブルを削除しない限り自由にはできません。DataMemoryおよびIndexMemoryの詳細は、項14.4.4.5. 「Defining Data Nodes」 を参照してください。トランザクション毎に実行できる最大のオペレーション数は設定パラメータ
MaxNoOfConcurrentOperationsおよびMaxNoOfLocalOperationsで設定できます。バルクでローディングする場合、TRUNCATE TABLE、およびALTER TABLEが複数のトランザクションを実行することで特別なケースとして扱われ、よってこの制限は適用されません。テーブルおよびインデックスに関連した異なる制限例えば、テーブル毎の最大数の順序付けされたインデックスが
MaxNoOfOrderedIndexesで決められた場合。
データベース名、テーブル名および属性名は
NDBテーブルでは他のテーブル ハンドラーより長くすることはできません。属性名は 31 文字に切り捨てられ、切り捨ての後一意でない場合にはえらーになります。データベース名およびテーブル名の合計は 122 文字です。(つまり、NDB Clusterのテーブル名の最大長は 122 文字からテーブルが属しているデータベースの数を引いたものになります。クラスタのデータベースの最大テーブル数は 20320 に制限されています。
MySQL 5.1.10 および以前のバージョンでは、非表示のプライマリ キーを含む
AUTO_INCREMENTカラム ? を持つ最大のテーブル数? は 2048です。この制限は MySQL 5.1.11 では解除されています。
テーブル毎の最大属性数は 128 に制限さえれています。
1 行の許可された最大サイズは 8KB です。それぞれの
BLOBあるいはTEXTカラムはこの合計に対して 256 + 8 = 264 バイトです。キー毎の属性の最大数は 32 です。
サポートされていない機能 (エラーにはならないが、サポートされていないもしくは強化できない):
外部キーの構成は、
MyISAMテーブルの場合と同様無視されます。セーブポイントおよびサーブポイントへのロールへバックは
MyISAMで無視されます。OPTIMIZEオペレーションはサポートされていません。LOAD TABLE ...FROM MASTERはサポートされていません。
パフォーマンスおよび制限に関連した問題:
NDBストレージ エンジンへのシーケンシャルなアクセスによるクエリのパフォーマンスの問題があります。多くの範囲のスキャンをするのはMyISAMあるいはInnoDBで行うより比較的高価になります。Records in range統計は利用できますが検証が済んでいないあるいは公式にはサポートしていません。これにより場合によっては non-optimal query plan になります。必要に応じてこの目的のためにUSE INDEXあるいはFORCE INDEXを使用できます。USING HASHで作成された一意のハッシュ インデックスはNULLがキーの一部として与えられた場合はテーブルのアクセスに使用できません。SQL_LOG_BINはデータのオペレーションには影響を及ぼしません。それはスキーマのオペレーションにサポートされています。MySQL Cluster は
BLOBカラムを持ちしかもプライマリ キーではないテーブルの binlog は生成しません。以下のスキーマのみがステートメントを実行する mysqld にはない クラスタの binlog にログインされます。
CREATE TABLEALTER TABLEDROP TABLECREATE DATABASE/CREATE SCHEMADROP DATABASE/DROP SCHEMACREATE TABLESPACEALTER TABLESPACEDROP TABLESPACECREATE LOGFILE GROUPALTER LOGFILE GROUPDROP LOGFILE GROUP
不明な機能:
唯一サポートされている分離レベルは
READ COMMITTEDです。(InnoDB はREAD COMMITTED、READ UNCOMMITTED、REPEATABLE READ、およびSERIALIZABLEをサポートしています。)これがバックアップおよびクラスタ データベースの保存に与える影響に関する情報は、項14.8.5. 「バックアップのトラブルシューティング」 を参照してください。ディスクで複製できないコミットコミットは複製できますがログのコミットのフラッシュは保証していません。
複数の MySQL サーバー (
MyISAMあるいはInnoDBには無関係):ALTER TABLEは複数の MySQL サーバー (配布テーブル ロックがない場合) を稼働中は完全にロックできません。DDL オペレーションはノード不具合が起こる場合があります。これらの 1 つ (
CREATE TABLEあるいはALTER TABLEなど) を実行しようとすると、データディクショナリがロックされクラスタを再起動しない限り DDL ステートメントはそれ以上実行されません。
MySQL Cluster 専用に発行 (
MyISAMあるいはInnoDBには関連せず):クラスタで使用されるすべてのマシンは同じアーキテクチャである必要があります。つまり、ノードをホストするすべてのマシンは big-endian あるいは little-endian のいずれかである必要があり、その両方を一緒に使用することはできません。例えば、x86 マシンで動作しているデータ ノードに指示する PowerPC で動作しているマネジメント ノードを持つことはできません。この制限は単に mysql あるいはクラスタの SQL ノードにアクセスする他のクライアントで稼動しているマシンには適用されません。
ノードをオンラインで追加あるいは削除することはできません (そのような場合クラスタを再起動する必要があります)。
1 台のホストで同時に複数のクラスタのプロセスを実行できますが、他の要因はともかくパフォーマンスおよび高可用性の理由によってそのように使用することは推奨できません。とくに、MySQL 5.1 は 1 つい上の ndbd プロセスが 1 台の物理マシンで実行されている MySQL Cluster の開発を使用している生産をサポートしていません。
今後の MySQL リリースではホスト毎の複数のデータ ノードを以下のテストを行うことでサポートします。しかし、MySQL 5.1 では、そのような設定は実験レベルだけでの検討になります。
クラスタをディスク無しで稼動している場合ディスク データ テーブルはサポートされていません。MySQL 5.1.12 以降のバージョンではそれはどちらも許可されていません。(Bug#20008)
複数のマネジメント サーバーを使用する場合:
ノード ID の自動割り当ては複数のマネジメント サーバー間では機能しないので接続文字列でノードに明示の ID を与える必要があります。
すべてのマネジメント サーバーに同じ設定をする際は特別な注意が必要です。この件に関してクラスタではと特別なチェックありません。
データ ノード毎の複数のネットワークはサポートされていません。これらを使用すると問題が発生します。データ ノードの不具合が発生した場合には、そのデータ ノードに別のルートが開放されていますので SQL はデータ ノードが停止ししかもそれを受信しなくなるまでその確認を待ちます。これにより効果的にクラスタの稼動を止めます。
1 つのデータ ノードに複数のネットワーク ハードウェア インターフェース (Ethernet カードなど) を使用できますが、これらは同じアドレスを使用する必要があります。こらは
config.iniファイルで接続毎に 1 つ以上の[TCP]セクションを使用できないことを意味しています。詳細については、項14.4.4.7. 「Cluster TCP/IP Connections」 をご参照してください。データ ノードの最大数は 48 です。
MySQL Cluster のノードの最大数は 63 です。この数にはすべての SQL ノード (MySQL サーバー)、API ノード (MySQL サーバー以外にクラスタにアクセスするアプリケーション)、データ ノード、およびマネジメント サーバーが含まれています。
MySQL 5.1 Cluster のメタデータ オブジェクトの最大数は 20320 です。この制限はハードで制限されています。
MySQL 5.1 で解決された MySQL Cluster 以前のバージョンの問題:
NDB Clusterストレージ エンジンは今はin-memory テーブルにサポートしています。以前は、これは? 例えば ? 比較的に小さい値をもつ 1 つ以上の
VARCHARフィールドを持ち、NDBClusterストレージ エンジンを使用するときに同じ テーブルおよびデータを持つMyISAMエンジンを使用した場合に比べてより多くのメモリやディスク スペースを必要としたクラスタ テーブルのことを意味します。言い換えれば、VARCHARカラムの場合で、同じサイズのCHARカラムと同じストレージ容量が要求されるカラムのです。MySQL 5.1 では、これはもはや in-memory テーブルには当てはまらず、そこではVARCHARおよびBINARYなどの変数カラムのストレージ要件がMyISAMテーブルで使用された場合これらのカラム タイプに対してそれらと互換性があります(項10.5. 「データタイプが必要とする記憶容量」 参照)。重要MySQL Cluster のディスク データ テーブルでは、固定幅の制限はそのまま適用されます。項14.11. 「MySQL Cluster ディスク データ ストレージ」 参照。
MySQL のレプリケーションを Cluster データベースに使用できるようになりました。詳細に関しては 項14.10. 「MySQL Cluster レプリケーション」 を参照して下さい。
しかしながら、循環型レプリケーションは現在 MySQL では現在サポートされていません 。項14.10.3. 「既知の問題」 参照。
所定の mysqld が既に動作していてデータベースが異なる mysqld で作成されると同時にクラスタに接続される場合、データベースの自動検索は現在同じ MySQL Cluster にアクセスする複数の MySQL サーバーをサポートしています。
このことは mysqld プロセスが
db_nameの名前のデータベースが作成された後に最初にクラスタの接続すると、それが最初に MySQL Cluster にアクセスしたときに「新しい」 MySQL サーバーでCREATE SCHEMAステートメントを発行する必要があります。これが完了すると、その 「新しい」 mysqld はそのデータベースのテーブルをエラーなしで削除できます。db_nameこのとこはまたオンラインで
NDBテーブルのスキーマの変更が可能であることを意味しています。つまり、クラスタの SQL ノードで実行されたALTER TABLEおよびCREATE INDEXなどのオペレーションの結果がなんら他の操作をしなくてもクラスタの他の SQL ノードに見えるということです。MySQL 5.1.10 以降では、クラスタのバックアップを行って異なるアーキテクチャ間で保存できます。以前は? 例えば ? big-endian プラットフォームで動作しているクラスタをバックアップできず、またそのバックアップから little-endian システムで動作しているクラスタに保存できませんでした。(Bug#19255)
MySQL 5.1.10 以降は MySQL をクラスタのサポート付きで非デフォルトのロケーションにインストールして
--basedirあるいは--character-sets-dirオプションのいずれかを使用してフロント ディスクリプション ファイルの検索パスkを変更できます。(以前は MySQL 5.1 の ndbd はデフォルトのパスのみを検索していました ? 一般的には/usr/local/mysql/share/mysql/charsets? 文字セットに対して)MySQL 5.1 では、それはもはや必要なくなり、複数のマネジメント サーバーを稼動するとき、マネジメント ノードがお互いを見るにようにするにはすべてのクラスタのデータ ノードを再起動します。
この項では、MySQL 5.1 を MySQL 5.0 に比較した場合の MySQL Cluster の実装における変更点について説明します。
MySQL 5.0 に比較した場合、MySQL 5.1 への NDB
Cluster ストレージ
エンジンの実装では多くの大きな変更点があります。これらの変更点の概要については、項14.14.1. 「MySQL 5.1 における MySQL Cluster の変更点」
を参照してください。
MySQL Cluster の多くの新機能が MySQL 5.1 に導入せれています。:
MySQL Cluster の MySQL レプリケーションへの統合:この統合によってクラスタのどの MySQL サーバーからの更新が可能になりクラスタの MySQL サーバーの 1 台による MySQL レプリケーションを持ち、スレーブ スライドの状態がマスタとして機能するクラスタとの一貫性を維持しています。
詳しくは 項14.10. 「MySQL Cluster レプリケーション」 を参照してください。
ディスク ベースのレコードのサポート:ディスクのレコードは今サポートされています。プライマリ キーのハッシュ インデックスを含むインデックス領域はまだ RAM に保存される必要がありますが、他のすべての領域はディスクに保存できます。
詳しくは 項14.11. 「MySQL Cluster ディスク データ ストレージ」 を参照してください。
変数サイズのレコード:
VARCHAR(255)として定義されたカラムは現在特定のレコードに保存されたものとは別個に 260 バイトのストレージを使用しています。MySQL 5.1 のクラスタ テーブルでは、実際はレコードで使用されるカラムの一部のみが保存されます。これによりそのようなカラムのスペースを多くのケースで 5 倍ほど削減します。ユーザー定義のパーテッショニング:ユーザーはプライマリ キーの一部であるカラムのパーテッションを定義できます。
NDBテーブルをKEYおよびLINEAR KEYスキーマに基づいてパーティッションできます。この機能は多くの他の MySQL ストレージ エンジンにも利用できます。それによってNDB Clusterテーブルでは利用できない特別なパーティショニングをサポートします。MySQL 5.1 のユーザー定義のパーティショニングの一般情報の詳細に関しては、 章?15. パーティショニング を参照してください。パーティショニングの詳細については 項15.2. 「パーティショニングのタイプ」 で説明します。
MySQL サーバーはいくつかのパーティションを
WHERE節から 「剪定」 することもできます。 項15.4. 「パーティションの刈り込み」 参照。テーブル スキーマの変更点の自動検索.MySQL 5.1 では、
FLUSH TABLESあるいは 「ダミー」SELECTをNDBテーブルあるいは 1 つの SQL ノードの既存のNDBテーブルのスキーマに加えた変更に対して発行して クラスタの他のSQL ノードで見えるようにする必要が無くなりました。注:新たにデータベースを作成するとき、それでも
CREATE DATABASEあるいはCREATE SCHEMAステートメントをクラスタの各 SQL ノードに発行する必要があります。
詳細に関しては MySQL Cluster issues from previous versions that have been resolved in MySQL 5.1 を参照してください。
以下の用語は MySQL Cluster の理解あるいは MySQL Cluster に関する特別な意味を持ちます。
クラスタ:
一般的な意味は、クラスタはユニットで動作する一連のコンピュータで 1 つのタスクを実行するために一緒に作業します。
NDB Cluster:これは MySQL のストレージ エンジンでいくつかのコンピュータを束ねてデータ ストレージ、検索、および管理を行うためのものです。
MySQL Cluster:
これは
NDBストレージ エンジンを使用した一群のコンピュータが一緒に作業して、in-memory storage を使用して アーキテクチャを共有しない構成で分散型 MySQL データベースをサポートすることを意味します。設定ファイル:
テキスト ファイルで命令およびクラスタ、そのホスト、およびそのノードに関する情報を含んでいます。これらはクラスタが起動したときにクラスタのマネジメント ノードで読み込まれます。詳細は 項14.4.4. 「設定ファイル」 を参照してください。
Backup:
クラスタ、トランザクションおよびログの完全なコピーで、ディスクあるいは他の長期使用のストレージに保存されます。
復旧:
クラスタをバックアップで保存した前の状態に戻します。
チェックポイント:
一般的には、データがディスクの保存された場合、チェックポイントに達したと言われています。クラスタに特化した場合には、すべての実行されたトランザクションがディスクに時宜をえて保存された時点を意味します。
NDBストレージ エンジンに関しては、2 種類のチェックポイントがありそれが共同して安定したクラスタの表示を維持します。ローカル チェックポイント (LCP):
これは 1 つのノードに特化したチェックポイントですが、LCP はクラスタではほぼ同時にすべてのノードで行われます。LCP はノードのすべてのデータのディスクへの保存に関わり、通常は数分間隔でそれを実行します。この正確な間隔はノードで保存されるデータ量、クラスタの作業量、および他の要因によってばらつきがあります。
グローバル チェックポイント (GCP):
GCP はすべてのノードのトランザクションの同期および redo-log のディスクへのフラッシュ時に数秒毎に実行されます。
クラスタ ホスト:
MySQL Cluster の一部を構成するコンピュータ。クラスタには物理構成と論理構成の両方があります。物理的には、クラスタ ホスト (あるいはもっ単に ホスト) と呼ばれる多くのコンピュータで構成されます。以下のノードおよびノード グループを参照してください。
ノード:
これは MySQL Cluster の論理および関数単位に関するもので、クラスタ ノード とも呼ばれます。MySQL Cluster の説明では、「ノート」 用語をクラスタの物理コンポーネントよりはむしろプロセスとして使用しています。MySQL Cluster の構築するには 3 種類のノードが必要です。
マネジメント (MGM) ノード:
MySQL Cluster の他のノードを管理します。それは他のノードに設定データ、つまりノードの起動および停止、ネットワークのパーティショニングの取扱い、バックアップの作成およびその保存などの設定データを提供します。
SQL (MySQL サーバー) ノード:
MySQL サーバーのインスタンスで、クラスタの データ ノード に保持されたデータへのフロントエンドの役割を果たします。データを保存、抽出、あるいは更新を希望するクライアントは他の MySQL サーバーにアクセスするように SQL ノードにアクセスし、通常の認証手法および API を使用し、ノード グループ間のデータの配布をユーザーやアプリケーションに透明にします。SQL ノードは異なるデータ ノードあるいはホスト間のデータの配布には関係なくクラスタのデータベース全体にアクセスします。
データ ノード:
これらのノードが実際のデータを保存します。テーブル データのフラグメントは一連のノード グループに保存されます。各ノード グループはテーブル データの異なるサブセットを保存します。ノード グループを構成する各ノードはノード グループが担当するフラグメントのコピーを保存します。現在は 1 つのクラスタは合計で 48 データ ノードまでサポートしています。
1 つ以上のノードが 1 台のマシンに共存できます。(実際は、1 台のマシンに完全なクラスタを構築できますが、これを実際の生産環境で使用しようとは思わないでしょう。MySQL Cluster で作業するとき、用語のホストはクラスタの物理コンポーネントで、一方ノード は論理あるいは機能のコンポーネント (つまり、プロセス) を覚えておくと便利です。
用語に関する備考:旧バージョンの MySQL Cluster の説明書では、データ ノードを 「データベース ノード」 を書いていたこともあります。「ストレージ ノード」 の用語を使っていたときもあります。さらに、SQL ノードを 「クライアント ノード」 と呼んだときもあります。.古い用語は混乱を避けるために使われなくなってきており、その意味においては使わないほうがいいでしょう。それらはまた 「API ノード」 とも言われます ? SQL ノードは実際はクラスタへの API ノードのインターフェースを提供します。
ノード グループ:
一連のデータ ノードノード グループのすべてのデータ ノードは同じデータ (フラグメント) を含みます。そして 1 つのグループのすべてのノードは異なるホストに常駐する必要があります。どのノードがどのノード グループに属するか管理できます。
詳細は、項14.2.1. 「MySQL Cluster ノード、ノード グループ、レプリカ、およびパーテッション」 を参照してください。
ノード不具合:
MySQL Cluster はクラスタを構成する 1 つのノードのだけに依存している訳ではないので、クラスタは 1 つ以上のノードが失敗しても動作を続けます。所定のクラスタが耐えられるノードの不具合の正確な数はノード数およびクラスタの構成によります。
ノードの再起動:
失敗したクラスタ ノードの再起動プロセス
内部ノードの再起動:
ファイルシステムを削除したクラスタ ノードの起動プロセス。これはソフトウェアのアップグレードおよび他の特殊な環境でたまに使用されます。
システム クラッシュ (あるいは システム不具合):
これは多くのクラスタ ノードに不具合が発生してクラスタがそれ以上耐えられなくなると起こります。
システムの再起動:
クラスタの再起動およびディスクのログおよびチェックポイントからの初期化のプロセスです。これはクラスタの予定されたあるいは予定外のシャットダウンの後に必要になります。
フラグメント:
データベース テーブルの一部で、
NDBストレージ エンジンでは、テーブルは分割されたくさんのフラグメントで保存されます。フラグメントはたまに 「パーティション」 とも呼ばれます。しかし、「フラグメント」 のほうが好ましい用語です。テーブルは マシンとノード間の負荷分散のために MySQL Cluster クラスタでフラグメント化(分割)されます。レプリカ:
NDBストレージ エンジンでは、各テーブルのフラグメントは冗長性を提供するために他のデータで保存された多くのレプリカ(コピー)保持します。現在は、フラグメント毎に 4 つのレプリカがあります。トランスポーター:
ノード間のデータ伝送を提供するプロトコルです。MySQL Cluster は現在 4 種類のトランスポーター接続をサポートしています。
TCP/IP
これは、勿論、馴染みのネットワーク プロトコルでインターネット上の HTTP、FTP (など) を基礎をなすものです。TCP/IP はローカルおよびリモート接続の両方に使用できます。
SCI
スケーラブル コヒーラント インターフェースはマルチプロセッサ システムおよび並列処理アプリケーションを構築する高速のプロトコルです。SCI を MySQL Cluster で使用するには 項14.12.1. 「SCI ソケットを使用するための MySQL Cluster の設定」 で説明した特別なハードウェアが必要です。SCI に関する基本的な説明は this essay at dolphinics.com を参照してください。
SHM
Unix-style のshared memory セグメントです。サポートされている場合、SHM は同じホストで動作しているノードを自動的に接続するために使用します。この件に関する詳細な情報を得るにはUnix man page for
shmop(2)が最適です。
注:クラスタのトランスポーターはクラスタに対しては内部的です。MySQL Cluster を使用したアプリケーションは SQL ノードとれらが他のバージョンの MySQL サーバー (TCP/IP 経由、あるいは Unix のソケット ファイルあるいは Windows パイプ) と同じように通信します。クエリが送られ標準の MySQL クライアント API を使用して結果を取り出します。
NDB:これは Network Database のことで、MySQL Cluster を使用するためのストレージ エンジンのことです。
NDBストレージ エンジンはすべての通常の MySQL データ タイプおよび SQL ステートメントをサポートし、ACID に準拠しています。このエンジンはまたトランザクション (実行およびロールバック) をフル サポートしています。非共有アーキテクチャ:
MySQL Cluster の理想緒的なアーキテクチャです。それはまさに何も共有しない設定で、各ノードは個別のホストで動作します。そのような配列の利点はどのホストやノードもシングル ポイントの不具合あるいは全体としてシステムのパフォーマンスのボトルネックになり得ないということです。
In-memory ストレージ:
各データ ノードに格納されたすべてのデータはノードのホスト コンピュータのメモリに保持されます。クラスタの各データ ノードには、データベースにレプリカを乗算し、それをデータ ノードで除算した数に相当する RAM 容量を持つ必要があります。このように、データベースのメモリが 1GB で、クラスタを 4 つのレプリカと 8 つのでーた ノードで構成する場合、メモリはノード毎に最低 500MB 必要になります。これはオペレーティング システムおよびホストで動作する他のアプリケーションが必要とするメモリに追加されます。
MySQL 5.1 では、非印インデックス カラムがディスクで保存される ディスク データ も作成でき、このようにクラスタが必要とするメモリ容量を減らすことができます。インデックスおよびインデックスを付したカラムはそのまま RAM に保持されます。項14.11. 「MySQL Cluster ディスク データ ストレージ」 参照。
テーブル:
リレーショナル データベースの場合と同様、用語の 「テーブル」 は全く同一に構成されたレコードを意味します。MySQL Cluster では、データベースのテーブルは一連のフラグメントとしてデータ ノードに保持され、それらはそれぞれ追加されたデータ ノードでレプリケートされます。データ ノードのセットは同じフラグメントをレプリケートしあるいはフラグメントのセットは ノード グループ として言及されます。
Cluster のプログラム:
これらは MySQL の動作、設定、管理に使用されるコマンドラインのプログラムです。それらにはサーバーのデーモン(daemons)が含まれます。:
ndbd:
データ ノード デーモン (データ ノードのプロセスを実行します)
ndb_mgmd:
マネジメント サーバーデーモン(マネジメント サーバーのプロセスを実行します)
およびクライアント プログラム:
ndb_mgm:
マネジメント クライアント (マネジメント コマンドを実行するためのインターフェースを提供します)
ndb_waiter:
クラスタのすべてのノードの状態を検証するために使用します。
ndb_restore:
バックアップからのクラスタのデータの復旧
これらのプログラムおよびそれらの使用法については 項14.6. 「MySQL Cluster のプロセス管理」 を参照してください。.
イベント ログ:
MySQL Cluster はイベントをカテゴリ (起動、シャットダウン、エラー、チェックポイントなど)、優先順位、および重要度別のログに記録します。レポートする (記録に残す) すべてのイベントの完全なリストは 項14.7.3. 「MySQL Cluster で生成されたイベント レポート」 にあります。イベント ログは 2種類あります。
クラスタ ログ:
クラスタの全体に関するレポートを希望するイベントのレコードを維持します。
ノード ログ:
各個別のノードを記録した個別のログ
通常の環境では、クラスタ ログのみの維持管理が必要でまたそれで十分です。ノード ログはアプリケーションの開発およびデバッグ処理にのみ使用されます。